 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgetn4ml: Tensor Network Training and Customization for Machine Learning
Feb 18, 2025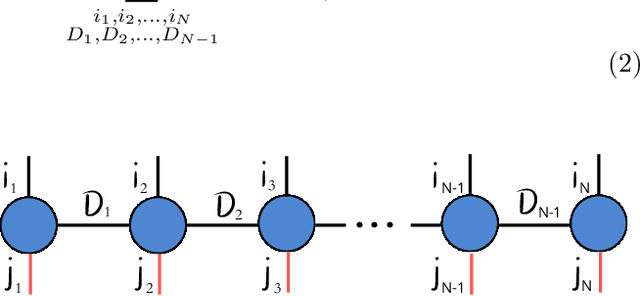
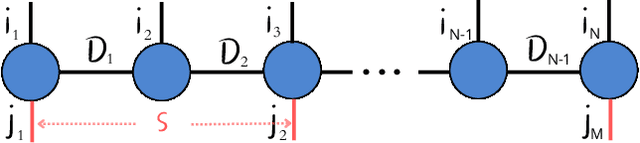
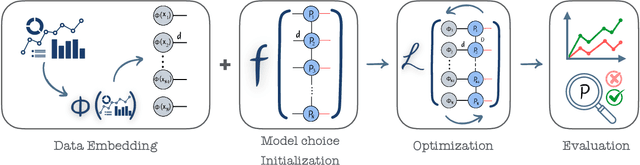
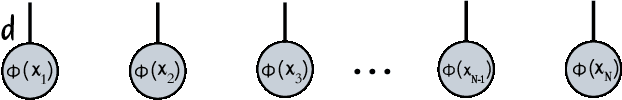
Tensor Networks have emerged as a prominent alternative to neural networks for addressing Machine Learning challenges in foundational sciences, paving the way for their applications to real-life problems. This paper introduces tn4ml, a novel library designed to seamlessly integrate Tensor Networks into optimization pipelines for Machine Learning tasks. Inspired by existing Machine Learning frameworks, the library offers a user-friendly structure with modules for data embedding, objective function definition, and model training using diverse optimization strategies. We demonstrate its versatility through two examples: supervised learning on tabular data and unsupervised learning on an image dataset. Additionally, we analyze how customizing the parts of the Machine Learning pipeline for Tensor Networks influences performance metrics.
Qibo: a framework for quantum simulation with hardware acceleration
Sep 03, 2020
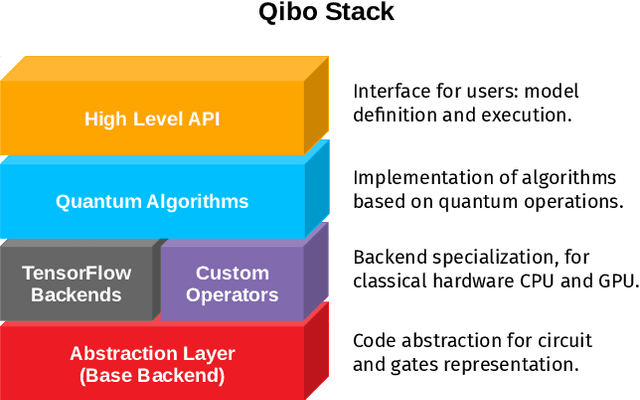
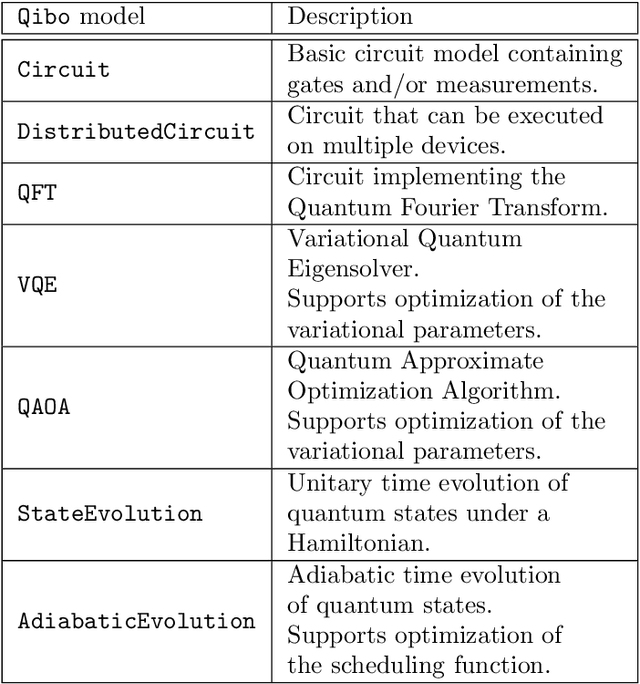
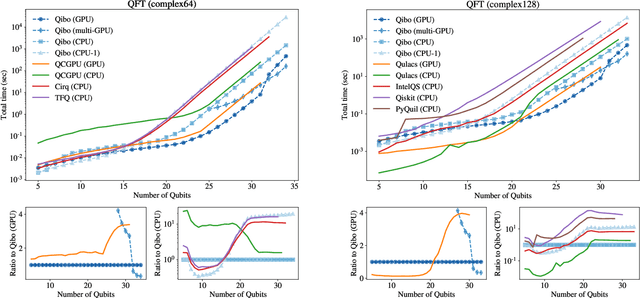
We present Qibo, a new open-source software for fast evaluation of quantum circuits and adiabatic evolution which takes full advantage of hardware accelerators. The growing interest in quantum computing and the recent developments of quantum hardware devices motivates the development of new advanced computational tools focused on performance and usage simplicity. In this work we introduce a new quantum simulation framework that enables developers to delegate all complicated aspects of hardware or platform implementation to the library so they can focus on the problem and quantum algorithms at hand. This software is designed from scratch with simulation performance, code simplicity and user friendly interface as target goals. It takes advantage of hardware acceleration such as multi-threading CPU, single GPU and multi-GPU devices.
Quantum Observables for continuous control of the Quantum Approximate Optimization Algorithm via Reinforcement Learning
Nov 21, 2019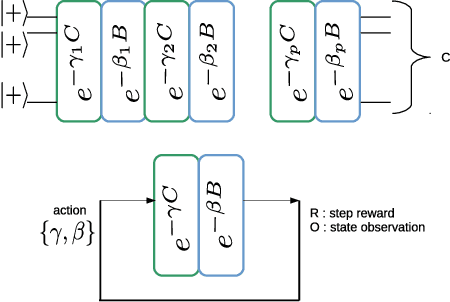
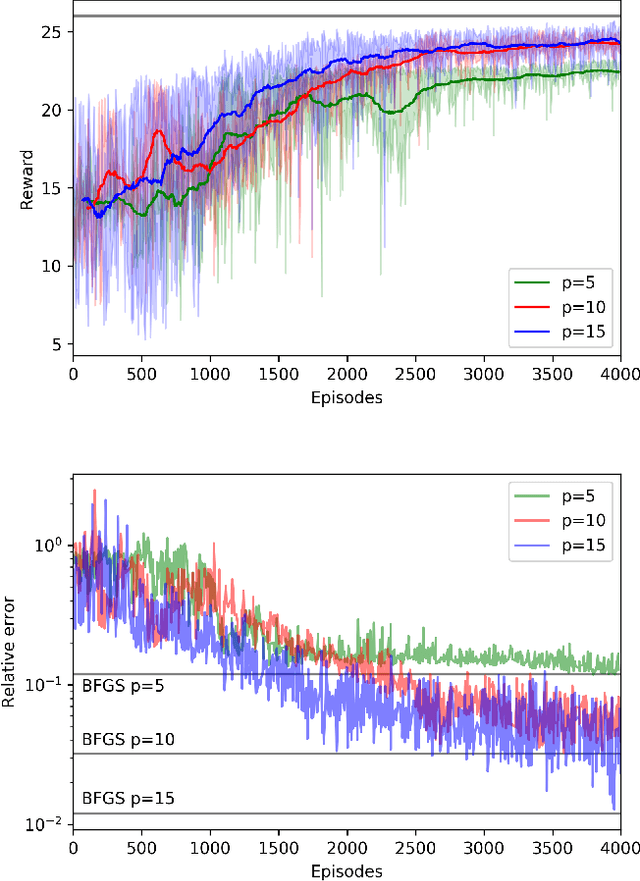
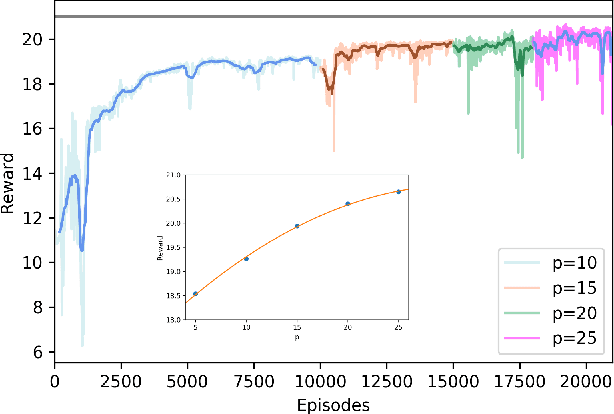
We present a classical control mechanism for Quantum devices using Reinforcement Learning. Our strategy is applied to the Quantum Approximate Optimization Algorithm (QAOA) in order to optimize an objective function that encodes a solution to a hard combinatorial problem. This method provides optimal control of the Quantum device following a reformulation of QAOA as an environment where an autonomous classical agent interacts and performs actions to achieve higher rewards. This formulation allows a hybrid classical-Quantum device to train itself from previous executions using a continuous formulation of deep Q-learning to control the continuous degrees of freedom of QAOA. Our approach makes a selective use of Quantum measurements to complete the observations of the Quantum state available to the agent. We run tests of this approach on MAXCUT instances of size up to N = 21 obtaining optimal results. We show how this formulation can be used to transfer the knowledge from shorter training episodes to reach a regime of longer executions where QAOA delivers higher results.