 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic White Paper on AI Infrastructure for Particle, Nuclear, and Astroparticle Physics: Insights from JENA and EuCAIF
Mar 18, 2025



Artificial intelligence (AI) is transforming scientific research, with deep learning methods playing a central role in data analysis, simulations, and signal detection across particle, nuclear, and astroparticle physics. Within the JENA communities-ECFA, NuPECC, and APPEC-and as part of the EuCAIF initiative, AI integration is advancing steadily. However, broader adoption remains constrained by challenges such as limited computational resources, a lack of expertise, and difficulties in transitioning from research and development (R&D) to production. This white paper provides a strategic roadmap, informed by a community survey, to address these barriers. It outlines critical infrastructure requirements, prioritizes training initiatives, and proposes funding strategies to scale AI capabilities across fundamental physics over the next five years.
Large Physics Models: Towards a collaborative approach with Large Language Models and Foundation Models
Jan 09, 2025

This paper explores ideas and provides a potential roadmap for the development and evaluation of physics-specific large-scale AI models, which we call Large Physics Models (LPMs). These models, based on foundation models such as Large Language Models (LLMs) - trained on broad data - are tailored to address the demands of physics research. LPMs can function independently or as part of an integrated framework. This framework can incorporate specialized tools, including symbolic reasoning modules for mathematical manipulations, frameworks to analyse specific experimental and simulated data, and mechanisms for synthesizing theories and scientific literature. We begin by examining whether the physics community should actively develop and refine dedicated models, rather than relying solely on commercial LLMs. We then outline how LPMs can be realized through interdisciplinary collaboration among experts in physics, computer science, and philosophy of science. To integrate these models effectively, we identify three key pillars: Development, Evaluation, and Philosophical Reflection. Development focuses on constructing models capable of processing physics texts, mathematical formulations, and diverse physical data. Evaluation assesses accuracy and reliability by testing and benchmarking. Finally, Philosophical Reflection encompasses the analysis of broader implications of LLMs in physics, including their potential to generate new scientific understanding and what novel collaboration dynamics might arise in research. Inspired by the organizational structure of experimental collaborations in particle physics, we propose a similarly interdisciplinary and collaborative approach to building and refining Large Physics Models. This roadmap provides specific objectives, defines pathways to achieve them, and identifies challenges that must be addressed to realise physics-specific large scale AI models.
TrackFormers: In Search of Transformer-Based Particle Tracking for the High-Luminosity LHC Era
Jul 09, 2024



High-Energy Physics experiments are facing a multi-fold data increase with every new iteration. This is certainly the case for the upcoming High-Luminosity LHC upgrade. Such increased data processing requirements forces revisions to almost every step of the data processing pipeline. One such step in need of an overhaul is the task of particle track reconstruction, a.k.a., tracking. A Machine Learning-assisted solution is expected to provide significant improvements, since the most time-consuming step in tracking is the assignment of hits to particles or track candidates. This is the topic of this paper. We take inspiration from large language models. As such, we consider two approaches: the prediction of the next word in a sentence (next hit point in a track), as well as the one-shot prediction of all hits within an event. In an extensive design effort, we have experimented with three models based on the Transformer architecture and one model based on the U-Net architecture, performing track association predictions for collision event hit points. In our evaluation, we consider a spectrum of simple to complex representations of the problem, eliminating designs with lower metrics early on. We report extensive results, covering both prediction accuracy (score) and computational performance. We have made use of the REDVID simulation framework, as well as reductions applied to the TrackML data set, to compose five data sets from simple to complex, for our experiments. The results highlight distinct advantages among different designs in terms of prediction accuracy and computational performance, demonstrating the efficiency of our methodology. Most importantly, the results show the viability of a one-shot encoder-classifier based Transformer solution as a practical approach for the task of tracking.
Novel Approaches for ML-Assisted Particle Track Reconstruction and Hit Clustering
May 27, 2024



Track reconstruction is a vital aspect of High-Energy Physics (HEP) and plays a critical role in major experiments. In this study, we delve into unexplored avenues for particle track reconstruction and hit clustering. Firstly, we enhance the algorithmic design effort by utilising a simplified simulator (REDVID) to generate training data that is specifically composed for simplicity. We demonstrate the effectiveness of this data in guiding the development of optimal network architectures. Additionally, we investigate the application of image segmentation networks for this task, exploring their potential for accurate track reconstruction. Moreover, we approach the task from a different perspective by treating it as a hit sequence to track sequence translation problem. Specifically, we explore the utilisation of Transformer architectures for tracking purposes. Our preliminary findings are covered in detail. By considering this novel approach, we aim to uncover new insights and potential advancements in track reconstruction. This research sheds light on previously unexplored methods and provides valuable insights for the field of particle track reconstruction and hit clustering in HEP.
Reduced Simulations for High-Energy Physics, a Middle Ground for Data-Driven Physics Research
Aug 30, 2023Subatomic particle track reconstruction (tracking) is a vital task in High-Energy Physics experiments. Tracking is exceptionally computationally challenging and fielded solutions, relying on traditional algorithms, do not scale linearly. Machine Learning (ML) assisted solutions are a promising answer. We argue that a complexity-reduced problem description and the data representing it, will facilitate the solution exploration workflow. We provide the REDuced VIrtual Detector (REDVID) as a complexity-reduced detector model and particle collision event simulator combo. REDVID is intended as a simulation-in-the-loop, to both generate synthetic data efficiently and to simplify the challenge of ML model design. The fully parametric nature of our tool, with regards to system-level configuration, while in contrast to physics-accurate simulations, allows for the generation of simplified data for research and education, at different levels. Resulting from the reduced complexity, we showcase the computational efficiency of REDVID by providing the computational cost figures for a multitude of simulation benchmarks. As a simulation and a generative tool for ML-assisted solution design, REDVID is highly flexible, reusable and open-source. Reference data sets generated with REDVID are publicly available.
Towards a Benchmark for Scientific Understanding in Humans and Machines
Apr 21, 2023Scientific understanding is a fundamental goal of science, allowing us to explain the world. There is currently no good way to measure the scientific understanding of agents, whether these be humans or Artificial Intelligence systems. Without a clear benchmark, it is challenging to evaluate and compare different levels of and approaches to scientific understanding. In this Roadmap, we propose a framework to create a benchmark for scientific understanding, utilizing tools from philosophy of science. We adopt a behavioral notion according to which genuine understanding should be recognized as an ability to perform certain tasks. We extend this notion by considering a set of questions that can gauge different levels of scientific understanding, covering information retrieval, the capability to arrange information to produce an explanation, and the ability to infer how things would be different under different circumstances. The Scientific Understanding Benchmark (SUB), which is formed by a set of these tests, allows for the evaluation and comparison of different approaches. Benchmarking plays a crucial role in establishing trust, ensuring quality control, and providing a basis for performance evaluation. By aligning machine and human scientific understanding we can improve their utility, ultimately advancing scientific understanding and helping to discover new insights within machines.
Benchmarking energy consumption and latency for neuromorphic computing in condensed matter and particle physics
Sep 21, 2022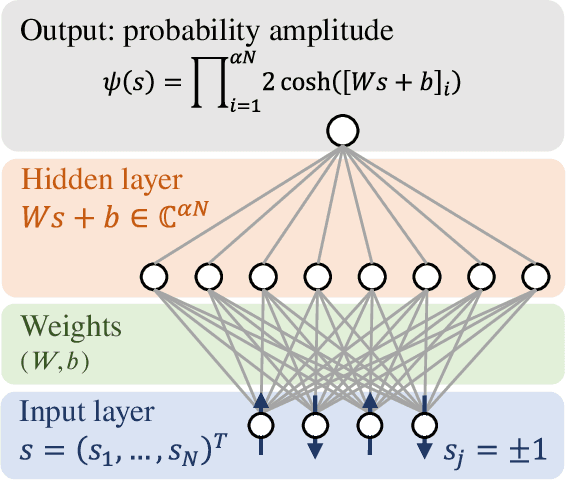
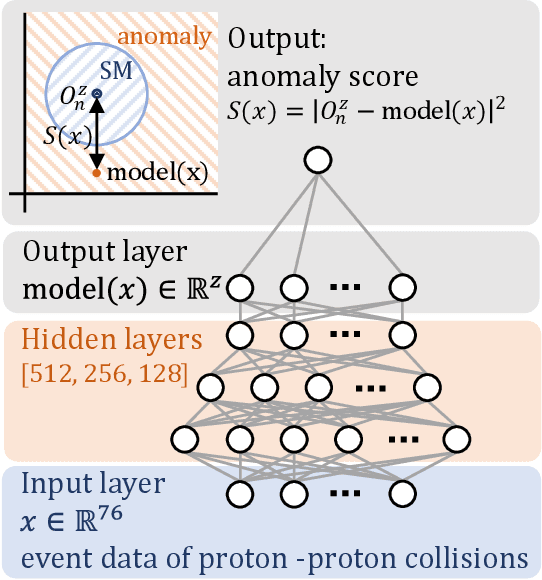
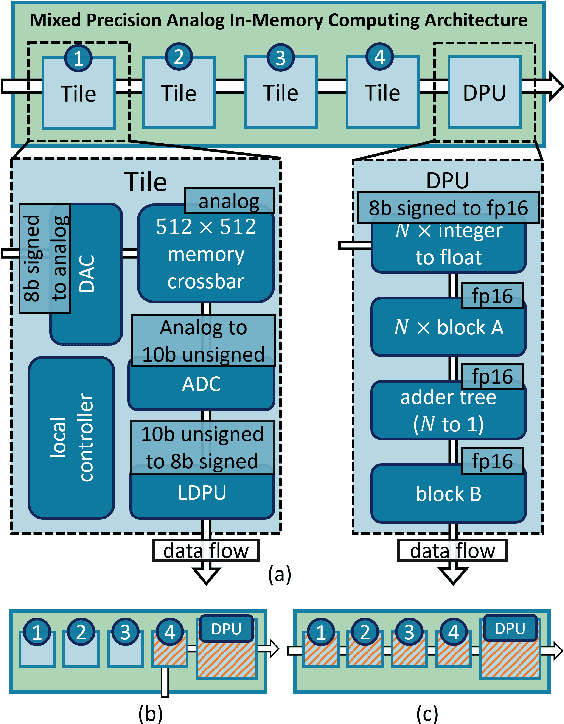
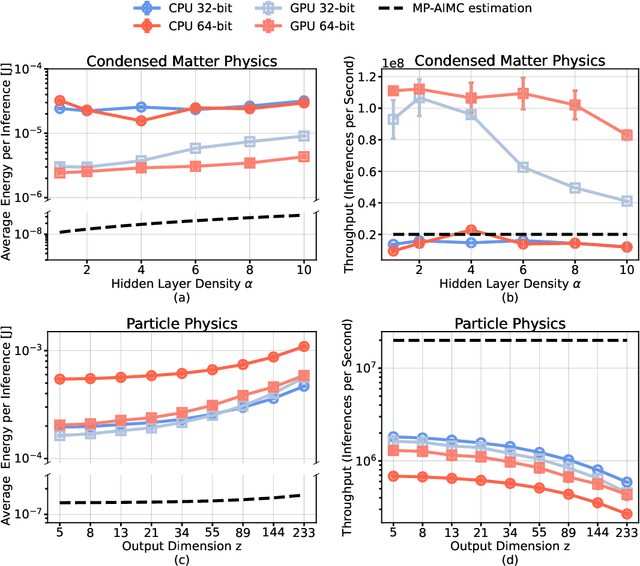
The massive use of artificial neural networks (ANNs), increasingly popular in many areas of scientific computing, rapidly increases the energy consumption of modern high-performance computing systems. An appealing and possibly more sustainable alternative is provided by novel neuromorphic paradigms, which directly implement ANNs in hardware. However, little is known about the actual benefits of running ANNs on neuromorphic hardware for use cases in scientific computing. Here we present a methodology for measuring the energy cost and compute time for inference tasks with ANNs on conventional hardware. In addition, we have designed an architecture for these tasks and estimate the same metrics based on a state-of-the-art analog in-memory computing (AIMC) platform, one of the key paradigms in neuromorphic computing. Both methodologies are compared for a use case in quantum many-body physics in two dimensional condensed matter systems and for anomaly detection at 40 MHz rates at the Large Hadron Collider in particle physics. We find that AIMC can achieve up to one order of magnitude shorter computation times than conventional hardware, at an energy cost that is up to three orders of magnitude smaller. This suggests great potential for faster and more sustainable scientific computing with neuromorphic hardware.
Constraining the Parameters of High-Dimensional Models with Active Learning
May 19, 2019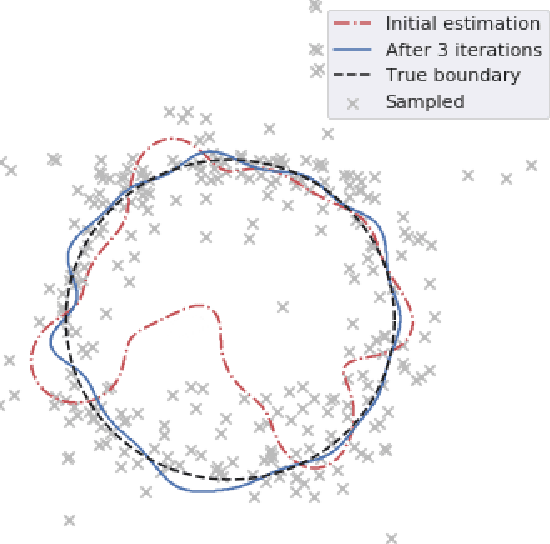

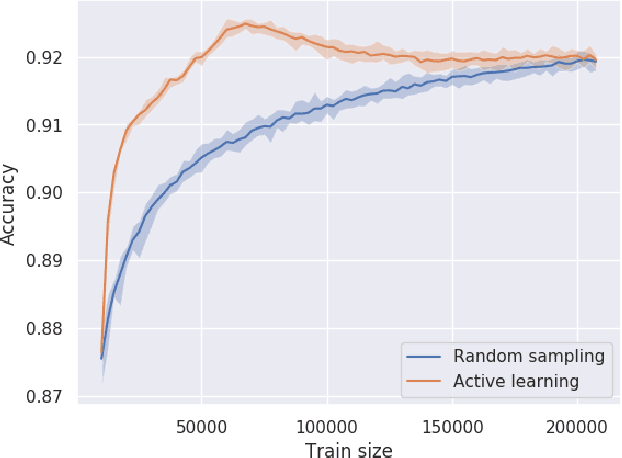

Constraining the parameters of physical models with $>5-10$ parameters is a widespread problem in fields like particle physics and astronomy. In this paper we show that this problem can be alleviated by the use of active learning. We illustrate this with examples from high energy physics, a field where computationally expensive simulations and large parameter spaces are common. We show that the active learning techniques query-by-committee and query-by-dropout-committee allow for the identification of model points in interesting regions of high-dimensional parameter spaces (e.g. around decision boundaries). This makes it possible to constrain model parameters more efficiently than is currently done with the most common sampling algorithms. Code implementing active learning can be found on GitHub.