 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reinforcement Learning from Human Feedback with Efficient Reward Model Ensemble
Paper and Code
Jan 30, 2024

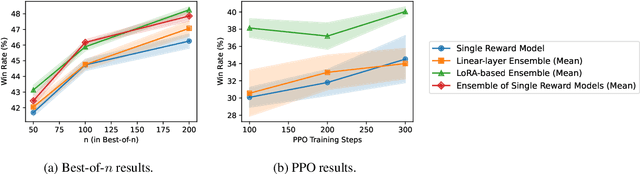

Reinforcement Learning from Human Feedback (RLHF) is a widely adopted approach for aligning large language models with human values. However, RLHF relies on a reward model that is trained with a limited amount of human preference data, which could lead to inaccurate predictions. As a result, RLHF may produce outputs that are misaligned with human values. To mitigate this issue, we contribute a reward ensemble method that allows the reward model to make more accurate predictions. As using an ensemble of large language model-based reward models can be computationally and resource-expensive, we explore efficient ensemble methods including linear-layer ensemble and LoRA-based ensemble. Empirically, we run Best-of-$n$ and Proximal Policy Optimization with our ensembled reward models, and verify that our ensemble methods help improve the alignment performance of RLHF outputs.