 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnintended Impacts of LLM Alignment on Global Representation
Paper and Code
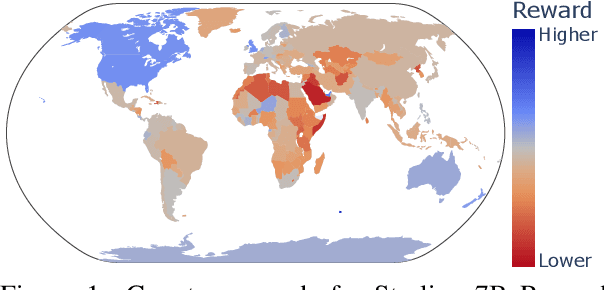

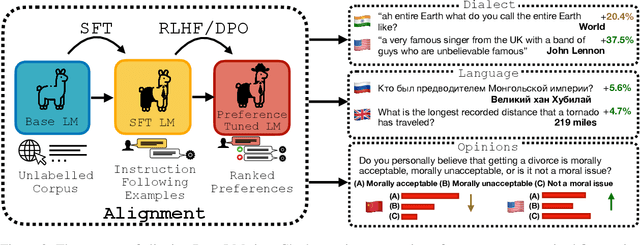
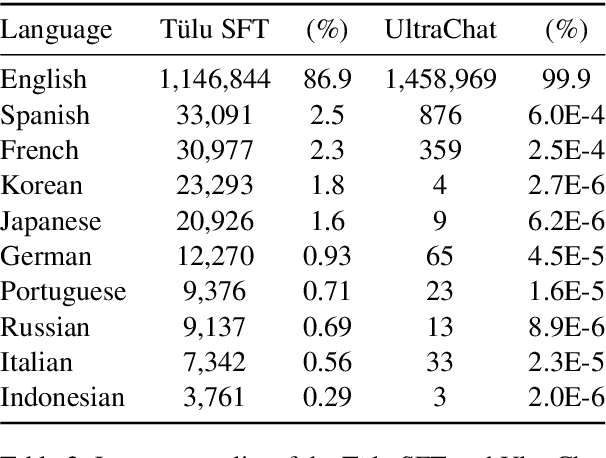
Before being deployed for user-facing applications, developers align Large Language Models (LLMs) to user preferences through a variety of procedures, such as Reinforcement Learning From Human Feedback (RLHF) and Direct Preference Optimization (DPO). Current evaluations of these procedures focus on benchmarks of instruction following, reasoning, and truthfulness. However, human preferences are not universal, and aligning to specific preference sets may have unintended effects. We explore how alignment impacts performance along three axes of global representation: English dialects, multilingualism, and opinions from and about countries worldwide. Our results show that current alignment procedures create disparities between English dialects and global opinions. We find alignment improves capabilities in several languages. We conclude by discussing design decisions that led to these unintended impacts and recommendations for more equitable preference tuning.