 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarvesting Textual and Structured Data from the HAL Publication Repository
Paper and Code
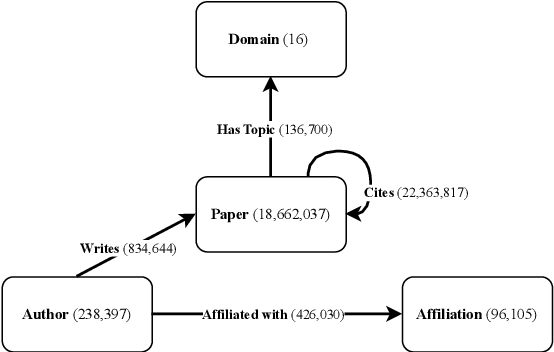



HAL (Hyper Articles en Ligne) is the French national publication repository, used by most higher education and research organizations for their open science policy. As a digital library, it is a rich repository of scholarly documents, but its potential for advanced research has been underutilized. We present HALvest, a unique dataset that bridges the gap between citation networks and the full text of papers submitted on HAL. We craft our dataset by filtering HAL for scholarly publications, resulting in approximately 700,000 documents, spanning 34 languages across 13 identified domains, suitable for language model training, and yielding approximately 16.5 billion tokens (with 8 billion in French and 7 billion in English, the most represented languages). We transform the metadata of each paper into a citation network, producing a directed heterogeneous graph. This graph includes uniquely identified authors on HAL, as well as all open submitted papers, and their citations. We provide a baseline for authorship attribution using the dataset, implement a range of state-of-the-art models in graph representation learning for link prediction, and discuss the usefulness of our generated knowledge graph structure.