 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModernBERT or DeBERTaV3? Examining Architecture and Data Influence on Transformer Encoder Models Performance
Paper and Code
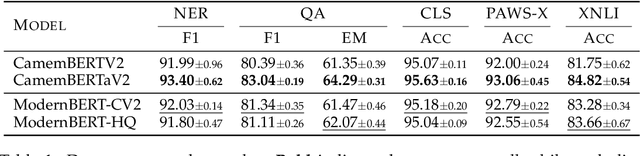
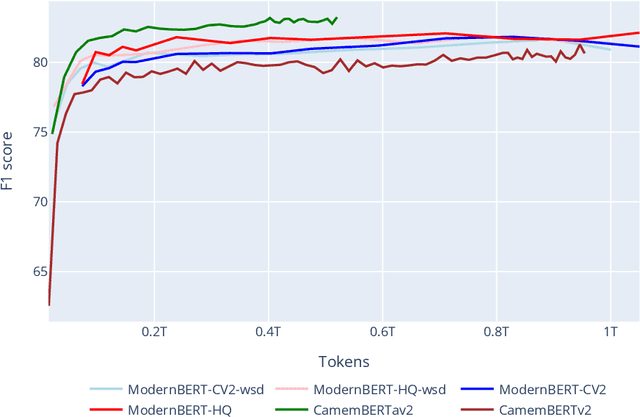
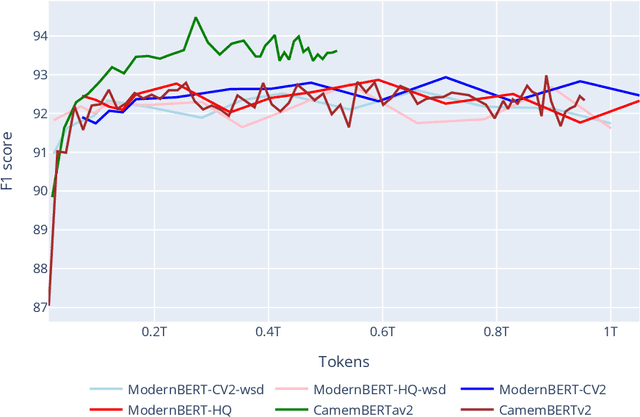
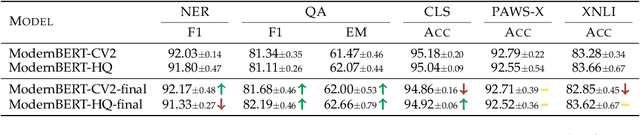
Pretrained transformer-encoder models like DeBERTaV3 and ModernBERT introduce architectural advancements aimed at improving efficiency and performance. Although the authors of ModernBERT report improved performance over DeBERTaV3 on several benchmarks, the lack of disclosed training data and the absence of comparisons using a shared dataset make it difficult to determine whether these gains are due to architectural improvements or differences in training data. In this work, we conduct a controlled study by pretraining ModernBERT on the same dataset as CamemBERTaV2, a DeBERTaV3 French model, isolating the effect of model design. Our results show that the previous model generation remains superior in sample efficiency and overall benchmark performance, with ModernBERT's primary advantage being faster training and inference speed. However, the new proposed model still provides meaningful architectural improvements compared to earlier models such as BERT and RoBERTa. Additionally, we observe that high-quality pre-training data accelerates convergence but does not significantly improve final performance, suggesting potential benchmark saturation. These findings show the importance of disentangling pretraining data from architectural innovations when evaluating transformer models.