 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Dataset Creation: Critical View of Annotation Variation and Bias Probing of a Dataset for Online Radical Content Detection
Dec 16, 2024The proliferation of radical content on online platforms poses significant risks, including inciting violence and spreading extremist ideologies. Despite ongoing research, existing datasets and models often fail to address the complexities of multilingual and diverse data. To bridge this gap, we introduce a publicly available multilingual dataset annotated with radicalization levels, calls for action, and named entities in English, French, and Arabic. This dataset is pseudonymized to protect individual privacy while preserving contextual information. Beyond presenting our \href{https://gitlab.inria.fr/ariabi/counter-dataset-public}{freely available dataset}, we analyze the annotation process, highlighting biases and disagreements among annotators and their implications for model performance. Additionally, we use synthetic data to investigate the influence of socio-demographic traits on annotation patterns and model predictions. Our work offers a comprehensive examination of the challenges and opportunities in building robust datasets for radical content detection, emphasizing the importance of fairness and transparency in model development.
Cloaked Classifiers: Pseudonymization Strategies on Sensitive Classification Tasks
Jun 25, 2024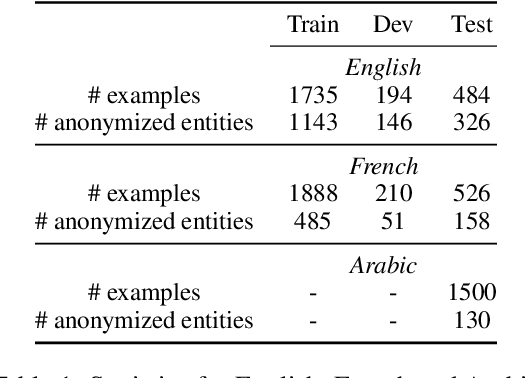
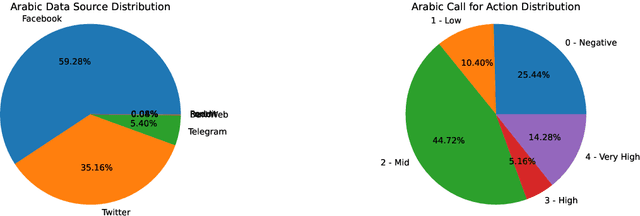

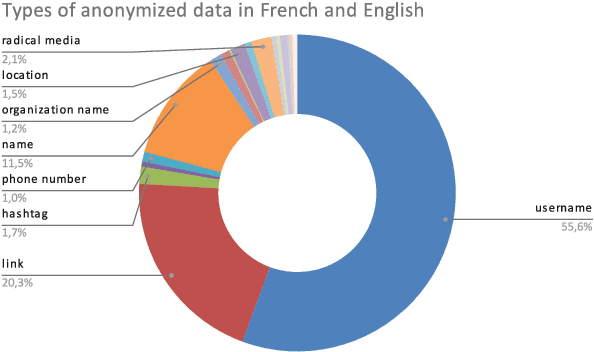
Protecting privacy is essential when sharing data, particularly in the case of an online radicalization dataset that may contain personal information. In this paper, we explore the balance between preserving data usefulness and ensuring robust privacy safeguards, since regulations like the European GDPR shape how personal information must be handled. We share our method for manually pseudonymizing a multilingual radicalization dataset, ensuring performance comparable to the original data. Furthermore, we highlight the importance of establishing comprehensive guidelines for processing sensitive NLP data by sharing our complete pseudonymization process, our guidelines, the challenges we encountered as well as the resulting dataset.