 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing ChatGPT Generated Data to Retrieve Depression Symptoms from Social Media
Paper and Code
Jul 06, 2023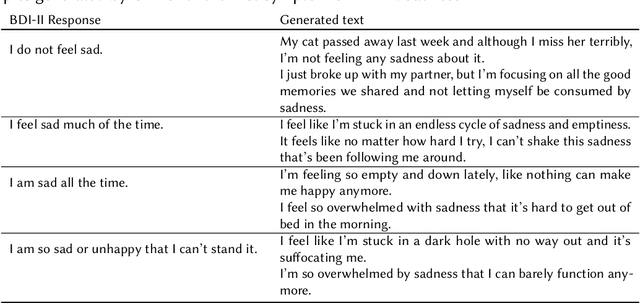


In this work, we present the contribution of the BLUE team in the eRisk Lab task on searching for symptoms of depression. The task consists of retrieving and ranking Reddit social media sentences that convey symptoms of depression from the BDI-II questionnaire. Given that synthetic data provided by LLMs have been proven to be a reliable method for augmenting data and fine-tuning downstream models, we chose to generate synthetic data using ChatGPT for each of the symptoms of the BDI-II questionnaire. We designed a prompt such that the generated data contains more richness and semantic diversity than the BDI-II responses for each question and, at the same time, contains emotional and anecdotal experiences that are specific to the more intimate way of sharing experiences on Reddit. We perform semantic search and rank the sentences' relevance to the BDI-II symptoms by cosine similarity. We used two state-of-the-art transformer-based models (MentalRoBERTa and a variant of MPNet) for embedding the social media posts, the original and generated responses of the BDI-II. Our results show that using sentence embeddings from a model designed for semantic search outperforms the approach using embeddings from a model pre-trained on mental health data. Furthermore, the generated synthetic data were proved too specific for this task, the approach simply relying on the BDI-II responses had the best performance.