 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxic language detection: a systematic survey of Arabic datasets
Dec 12, 2023This paper offers a comprehensive survey of Arabic datasets focused on online toxic language. We systematically gathered a total of 49 available datasets and their corresponding papers and conducted a thorough analysis, considering 16 criteria across three primary dimensions: content, annotation process, and reusability. This analysis enabled us to identify existing gaps and make recommendations for future research works.
Transformers and Ensemble methods: A solution for Hate Speech Detection in Arabic languages
Mar 17, 2023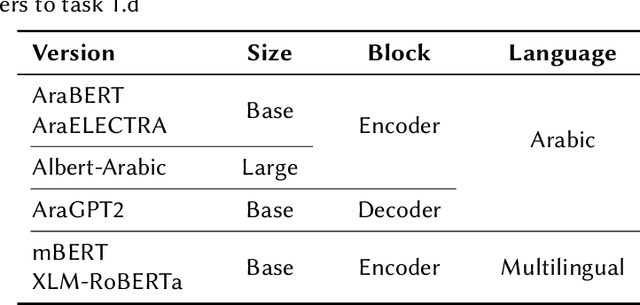
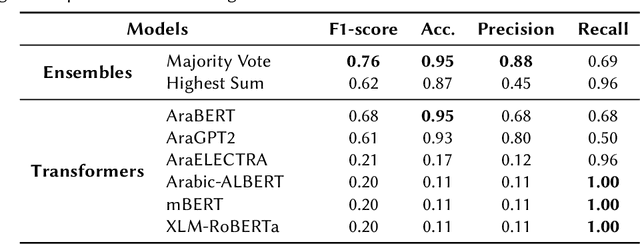
This paper describes our participation in the shared task of hate speech detection, which is one of the subtasks of the CERIST NLP Challenge 2022. Our experiments evaluate the performance of six transformer models and their combination using 2 ensemble approaches. The best results on the training set, in a five-fold cross validation scenario, were obtained by using the ensemble approach based on the majority vote. The evaluation of this approach on the test set resulted in an F1-score of 0.60 and an Accuracy of 0.86.