 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Irony Detection with Dependency Syntax and Neural Models
Paper and Code
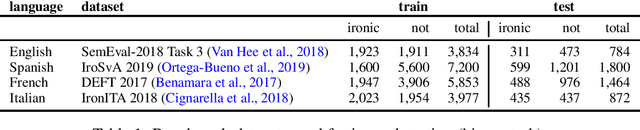


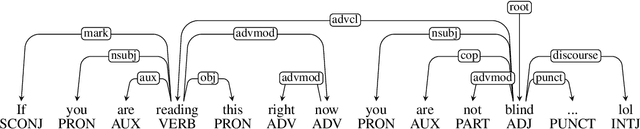
This paper presents an in-depth investigation of the effectiveness of dependency-based syntactic features on the irony detection task in a multilingual perspective (English, Spanish, French and Italian). It focuses on the contribution from syntactic knowledge, exploiting linguistic resources where syntax is annotated according to the Universal Dependencies scheme. Three distinct experimental settings are provided. In the first, a variety of syntactic dependency-based features combined with classical machine learning classifiers are explored. In the second scenario, two well-known types of word embeddings are trained on parsed data and tested against gold standard datasets. In the third setting, dependency-based syntactic features are combined into the Multilingual BERT architecture. The results suggest that fine-grained dependency-based syntactic information is informative for the detection of irony.