 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePainting the black box white: experimental findings from applying XAI to an ECG reading setting
Oct 27, 2022The shift from symbolic AI systems to black-box, sub-symbolic, and statistical ones has motivated a rapid increase in the interest toward explainable AI (XAI), i.e. approaches to make black-box AI systems explainable to human decision makers with the aim of making these systems more acceptable and more usable tools and supports. However, we make the point that, rather than always making black boxes transparent, these approaches are at risk of \emph{painting the black boxes white}, thus failing to provide a level of transparency that would increase the system's usability and comprehensibility; or, even, at risk of generating new errors, in what we termed the \emph{white-box paradox}. To address these usability-related issues, in this work we focus on the cognitive dimension of users' perception of explanations and XAI systems. To this aim, we designed and conducted a questionnaire-based experiment by which we involved 44 cardiology residents and specialists in an AI-supported ECG reading task. In doing so, we investigated different research questions concerning the relationship between users' characteristics (e.g. expertise) and their perception of AI and XAI systems, including their trust, the perceived explanations' quality and their tendency to defer the decision process to automation (i.e. technology dominance), as well as the mutual relationships among these different dimensions. Our findings provide a contribution to the evaluation of AI-based support systems from a Human-AI interaction-oriented perspective and lay the ground for further investigation of XAI and its effects on decision making and user experience.
Everything is Varied: The Surprising Impact of Individual Variation on ML Robustness in Medicine
Oct 11, 2022In medical settings, Individual Variation (IV) refers to variation that is due not to population differences or errors, but rather to within-subject variation, that is the intrinsic and characteristic patterns of variation pertaining to a given instance or the measurement process. While taking into account IV has been deemed critical for proper analysis of medical data, this source of uncertainty and its impact on robustness have so far been neglected in Machine Learning (ML). To fill this gap, we look at how IV affects ML performance and generalization and how its impact can be mitigated. Specifically, we provide a methodological contribution to formalize the problem of IV in the statistical learning framework and, through an experiment based on one of the largest real-world laboratory medicine datasets for the problem of COVID-19 diagnosis, we show that: 1) common state-of-the-art ML models are severely impacted by the presence of IV in data; and 2) advanced learning strategies, based on data augmentation and data imprecisiation, and proper study designs can be effective at improving robustness to IV. Our findings demonstrate the critical relevance of correctly accounting for IV to enable safe deployment of ML in clinical settings.
A Distributional Approach for Soft Clustering Comparison and Evaluation
Jun 20, 2022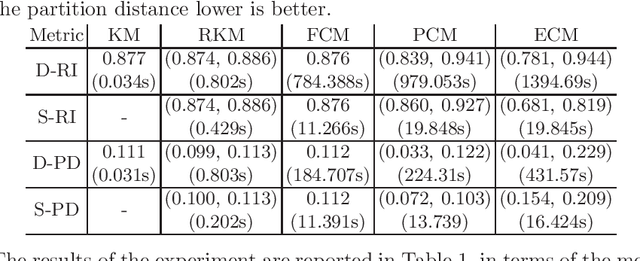
The development of external evaluation criteria for soft clustering (SC) has received limited attention: existing methods do not provide a general approach to extend comparison measures to SC, and are unable to account for the uncertainty represented in the results of SC algorithms. In this article, we propose a general method to address these limitations, grounding on a novel interpretation of SC as distributions over hard clusterings, which we call \emph{distributional measures}. We provide an in-depth study of complexity- and metric-theoretic properties of the proposed approach, and we describe approximation techniques that can make the calculations tractable. Finally, we illustrate our approach through a simple but illustrative experiment.
Toward a Perspectivist Turn in Ground Truthing for Predictive Computing
Sep 09, 2021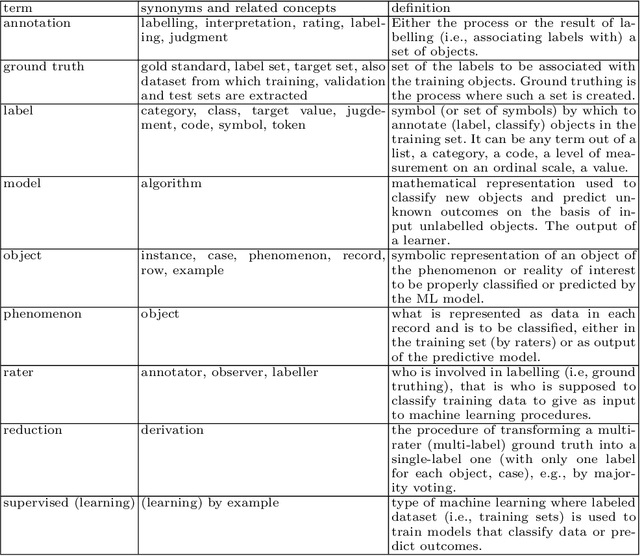
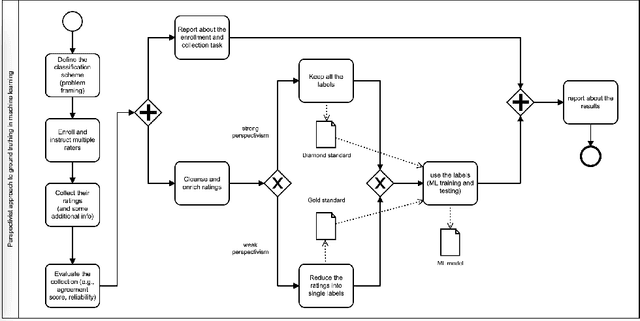
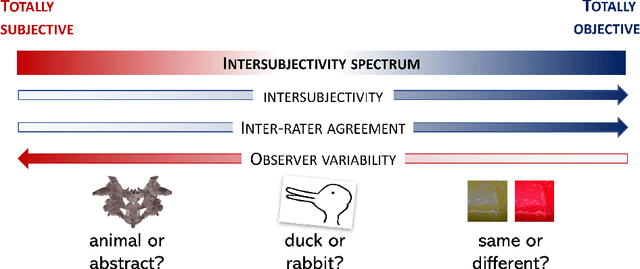
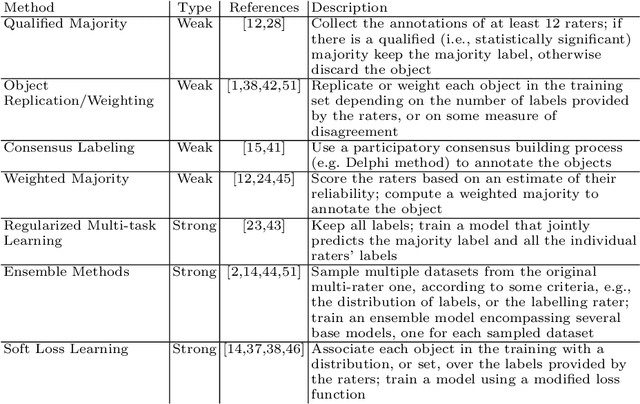
Most Artificial Intelligence applications are based on supervised machine learning (ML), which ultimately grounds on manually annotated data. The annotation process is often performed in terms of a majority vote and this has been proved to be often problematic, as highlighted by recent studies on the evaluation of ML models. In this article we describe and advocate for a different paradigm, which we call data perspectivism, which moves away from traditional gold standard datasets, towards the adoption of methods that integrate the opinions and perspectives of the human subjects involved in the knowledge representation step of ML processes. Drawing on previous works which inspired our proposal we describe the potential of our proposal for not only the more subjective tasks (e.g. those related to human language) but also to tasks commonly understood as objective (e.g. medical decision making), and present the main advantages of adopting a perspectivist stance in ML, as well as possible disadvantages, and various ways in which such a stance can be implemented in practice. Finally, we share a set of recommendations and outline a research agenda to advance the perspectivist stance in ML.
Who wants accurate models? Arguing for a different metrics to take classification models seriously
Oct 22, 2019

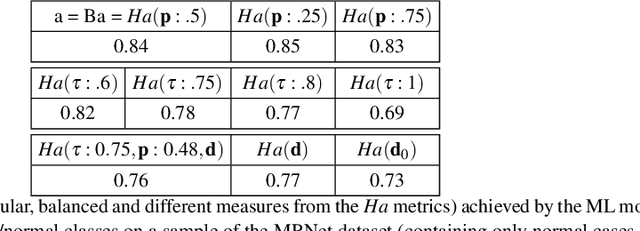

With the increasing availability of AI-based decision support, there is an increasing need for their certification by both AI manufacturers and notified bodies, as well as the pragmatic (real-world) validation of these systems. Therefore, there is the need for meaningful and informative ways to assess the performance of AI systems in clinical practice. Common metrics (like accuracy scores and areas under the ROC curve) have known problems and they do not take into account important information about the preferences of clinicians and the needs of their specialist practice, like the likelihood and impact of errors and the complexity of cases. In this paper, we present a new accuracy measure, the H-accuracy (Ha), which we claim is more informative in the medical domain (and others of similar needs) for the elements it encompasses. We also provide proof that the H-accuracy is a generalization of the balanced accuracy and establish a relation between the H-accuracy and the Net Benefit. Finally, we illustrate an experimentation in two user studies to show the descriptive power of the Ha score and how complementary and differently informative measures can be derived from its formulation (a Python script to compute Ha is also made available).