 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Multi-Head Channel Self-Attention for Facial Expression Recognition
Nov 18, 2021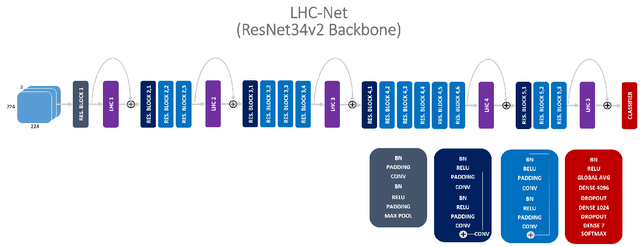
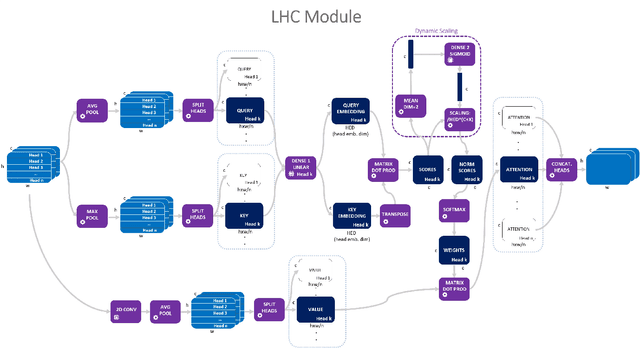
Since the Transformer architecture was introduced in 2017 there has been many attempts to bring the self-attention paradigm in the field of computer vision. In this paper we propose a novel self-attention module that can be easily integrated in virtually every convolutional neural network and that is specifically designed for computer vision, the LHC: Local (multi) Head Channel (self-attention). LHC is based on two main ideas: first, we think that in computer vision the best way to leverage the self-attention paradigm is the channel-wise application instead of the more explored spatial attention and that convolution will not be replaced by attention modules like recurrent networks were in NLP; second, a local approach has the potential to better overcome the limitations of convolution than global attention. With LHC-Net we managed to achieve a new state of the art in the famous FER2013 dataset with a significantly lower complexity and impact on the "host" architecture in terms of computational cost when compared with the previous SOTA.