 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Media Bias Detection Using Distant Supervision With BABE -- Bias Annotations By Experts
Paper and Code
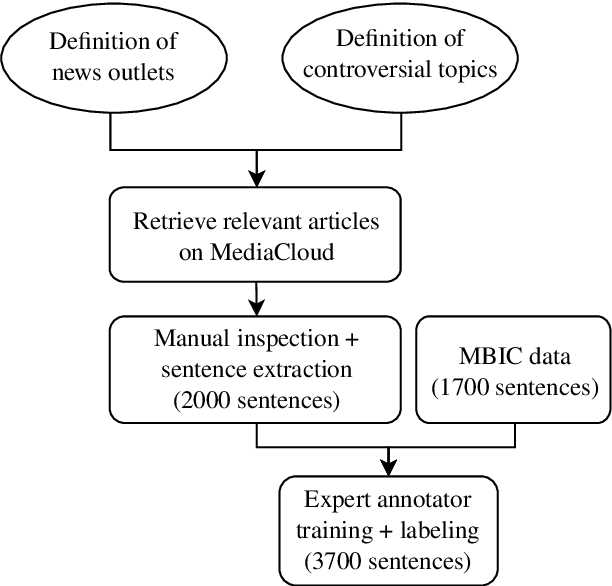
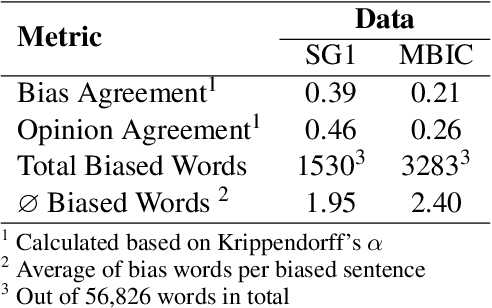
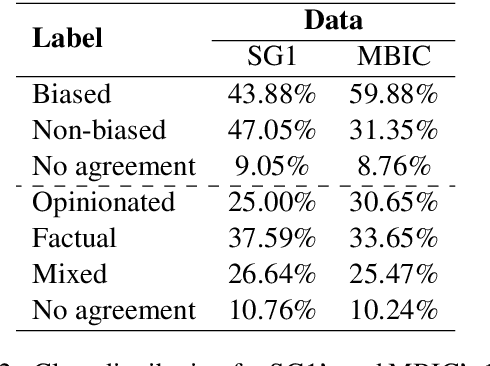
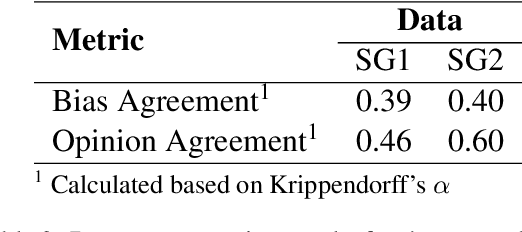
Media coverage has a substantial effect on the public perception of events. Nevertheless, media outlets are often biased. One way to bias news articles is by altering the word choice. The automatic identification of bias by word choice is challenging, primarily due to the lack of a gold standard data set and high context dependencies. This paper presents BABE, a robust and diverse data set created by trained experts, for media bias research. We also analyze why expert labeling is essential within this domain. Our data set offers better annotation quality and higher inter-annotator agreement than existing work. It consists of 3,700 sentences balanced among topics and outlets, containing media bias labels on the word and sentence level. Based on our data, we also introduce a way to detect bias-inducing sentences in news articles automatically. Our best performing BERT-based model is pre-trained on a larger corpus consisting of distant labels. Fine-tuning and evaluating the model on our proposed supervised data set, we achieve a macro F1-score of 0.804, outperforming existing methods.