 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo-Skim: Towards Efficiency Robustness Evaluation on Skimming-based Language Models
Dec 18, 2023To reduce the computation cost and the energy consumption in large language models (LLM), skimming-based acceleration dynamically drops unimportant tokens of the input sequence progressively along layers of the LLM while preserving the tokens of semantic importance. However, our work for the first time reveals the acceleration may be vulnerable to Denial-of-Service (DoS) attacks. In this paper, we propose No-Skim, a general framework to help the owners of skimming-based LLM to understand and measure the robustness of their acceleration scheme. Specifically, our framework searches minimal and unnoticeable perturbations at character-level and token-level to generate adversarial inputs that sufficiently increase the remaining token ratio, thus increasing the computation cost and energy consumption. We systematically evaluate the vulnerability of the skimming acceleration in various LLM architectures including BERT and RoBERTa on the GLUE benchmark. In the worst case, the perturbation found by No-Skim substantially increases the running cost of LLM by over 145% on average. Moreover, No-Skim extends the evaluation framework to various scenarios, making the evaluation conductible with different level of knowledge.
Matryoshka: Stealing Functionality of Private ML Data by Hiding Models in Model
Jun 29, 2022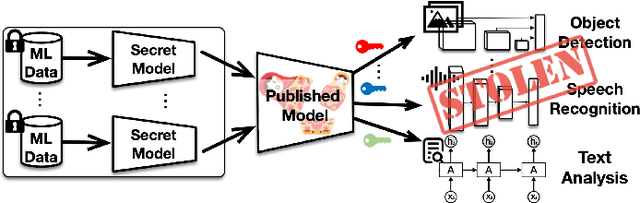
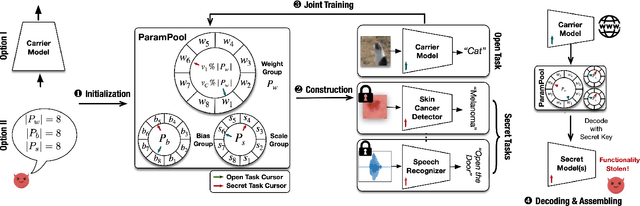
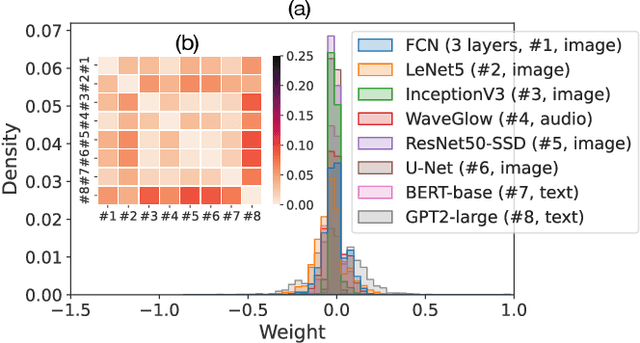
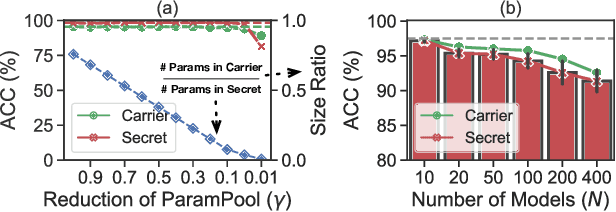
In this paper, we present a novel insider attack called Matryoshka, which employs an irrelevant scheduled-to-publish DNN model as a carrier model for covert transmission of multiple secret models which memorize the functionality of private ML data stored in local data centers. Instead of treating the parameters of the carrier model as bit strings and applying conventional steganography, we devise a novel parameter sharing approach which exploits the learning capacity of the carrier model for information hiding. Matryoshka simultaneously achieves: (i) High Capacity -- With almost no utility loss of the carrier model, Matryoshka can hide a 26x larger secret model or 8 secret models of diverse architectures spanning different application domains in the carrier model, neither of which can be done with existing steganography techniques; (ii) Decoding Efficiency -- once downloading the published carrier model, an outside colluder can exclusively decode the hidden models from the carrier model with only several integer secrets and the knowledge of the hidden model architecture; (iii) Effectiveness -- Moreover, almost all the recovered models have similar performance as if it were trained independently on the private data; (iv) Robustness -- Information redundancy is naturally implemented to achieve resilience against common post-processing techniques on the carrier before its publishing; (v) Covertness -- A model inspector with different levels of prior knowledge could hardly differentiate a carrier model from a normal model.
Matching Questions and Answers in Dialogues from Online Forums
May 19, 2020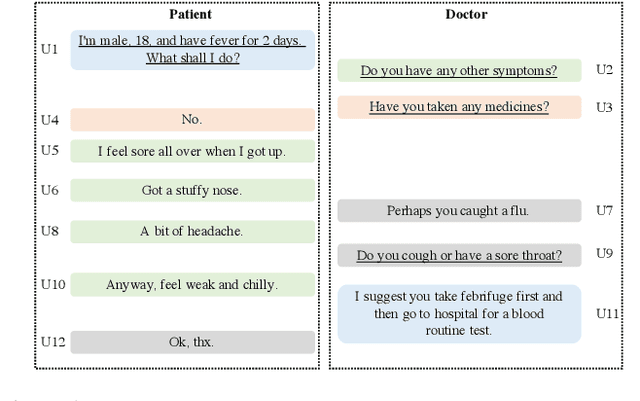

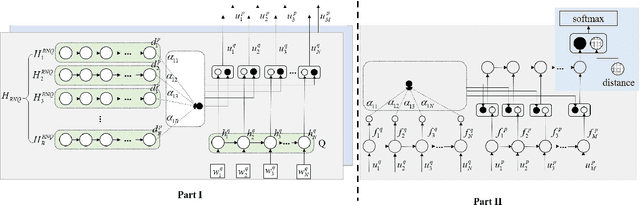

Matching question-answer relations between two turns in conversations is not only the first step in analyzing dialogue structures, but also valuable for training dialogue systems. This paper presents a QA matching model considering both distance information and dialogue history by two simultaneous attention mechanisms called mutual attention. Given scores computed by the trained model between each non-question turn with its candidate questions, a greedy matching strategy is used for final predictions. Because existing dialogue datasets such as the Ubuntu dataset are not suitable for the QA matching task, we further create a dataset with 1,000 labeled dialogues and demonstrate that our proposed model outperforms the state-of-the-art and other strong baselines, particularly for matching long-distance QA pairs.