 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUTE-SLAM: Real-Time Neural SLAM with Multiple Tri-Plane Hash Representations
Mar 26, 2024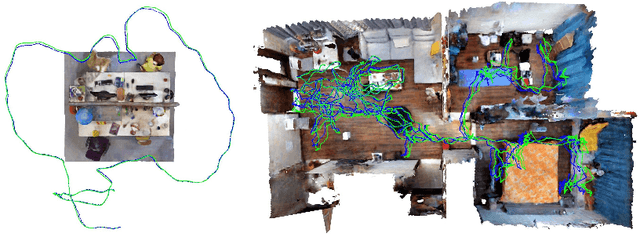
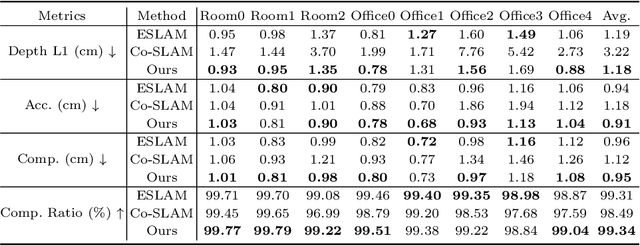
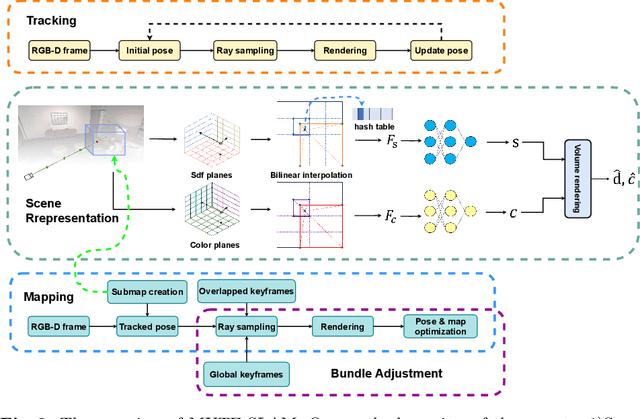
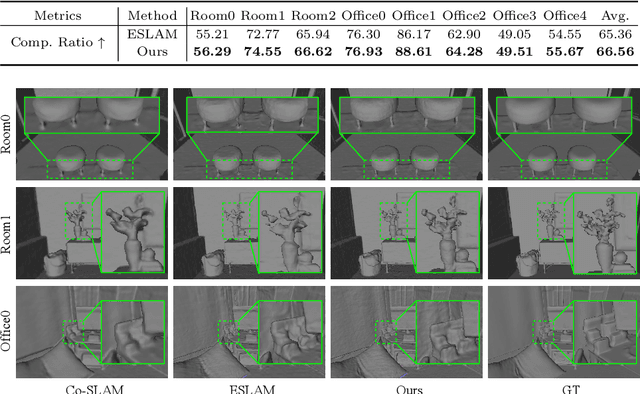
We introduce MUTE-SLAM, a real-time neural RGB-D SLAM system employing multiple tri-plane hash-encodings for efficient scene representation. MUTE-SLAM effectively tracks camera positions and incrementally builds a scalable multi-map representation for both small and large indoor environments. It dynamically allocates sub-maps for newly observed local regions, enabling constraint-free mapping without prior scene information. Unlike traditional grid-based methods, we use three orthogonal axis-aligned planes for hash-encoding scene properties, significantly reducing hash collisions and the number of trainable parameters. This hybrid approach not only speeds up convergence but also enhances the fidelity of surface reconstruction. Furthermore, our optimization strategy concurrently optimizes all sub-maps intersecting with the current camera frustum, ensuring global consistency. Extensive testing on both real-world and synthetic datasets has shown that MUTE-SLAM delivers state-of-the-art surface reconstruction quality and competitive tracking performance across diverse indoor settings. The code will be made public upon acceptance of the paper.
Rethinking White-Box Watermarks on Deep Learning Models under Neural Structural Obfuscation
Mar 17, 2023



Copyright protection for deep neural networks (DNNs) is an urgent need for AI corporations. To trace illegally distributed model copies, DNN watermarking is an emerging technique for embedding and verifying secret identity messages in the prediction behaviors or the model internals. Sacrificing less functionality and involving more knowledge about the target DNN, the latter branch called \textit{white-box DNN watermarking} is believed to be accurate, credible and secure against most known watermark removal attacks, with emerging research efforts in both the academy and the industry. In this paper, we present the first systematic study on how the mainstream white-box DNN watermarks are commonly vulnerable to neural structural obfuscation with \textit{dummy neurons}, a group of neurons which can be added to a target model but leave the model behavior invariant. Devising a comprehensive framework to automatically generate and inject dummy neurons with high stealthiness, our novel attack intensively modifies the architecture of the target model to inhibit the success of watermark verification. With extensive evaluation, our work for the first time shows that nine published watermarking schemes require amendments to their verification procedures.
Matryoshka: Stealing Functionality of Private ML Data by Hiding Models in Model
Jun 29, 2022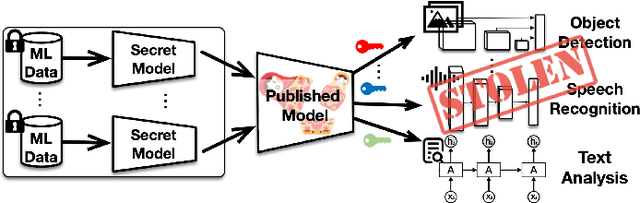
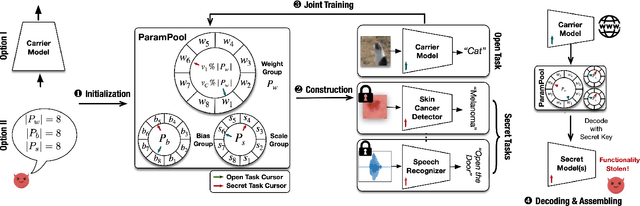
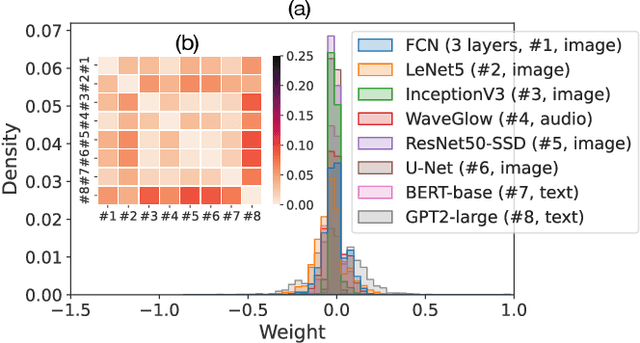
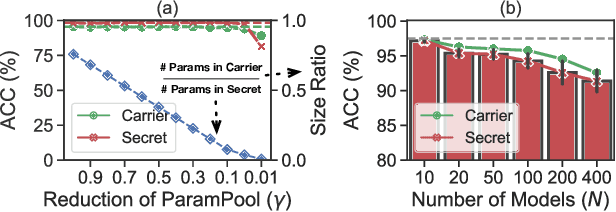
In this paper, we present a novel insider attack called Matryoshka, which employs an irrelevant scheduled-to-publish DNN model as a carrier model for covert transmission of multiple secret models which memorize the functionality of private ML data stored in local data centers. Instead of treating the parameters of the carrier model as bit strings and applying conventional steganography, we devise a novel parameter sharing approach which exploits the learning capacity of the carrier model for information hiding. Matryoshka simultaneously achieves: (i) High Capacity -- With almost no utility loss of the carrier model, Matryoshka can hide a 26x larger secret model or 8 secret models of diverse architectures spanning different application domains in the carrier model, neither of which can be done with existing steganography techniques; (ii) Decoding Efficiency -- once downloading the published carrier model, an outside colluder can exclusively decode the hidden models from the carrier model with only several integer secrets and the knowledge of the hidden model architecture; (iii) Effectiveness -- Moreover, almost all the recovered models have similar performance as if it were trained independently on the private data; (iv) Robustness -- Information redundancy is naturally implemented to achieve resilience against common post-processing techniques on the carrier before its publishing; (v) Covertness -- A model inspector with different levels of prior knowledge could hardly differentiate a carrier model from a normal model.
Cracking White-box DNN Watermarks via Invariant Neuron Transforms
May 19, 2022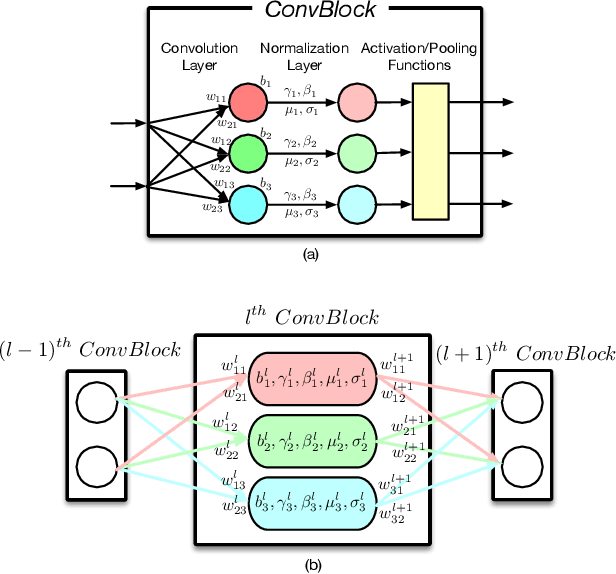
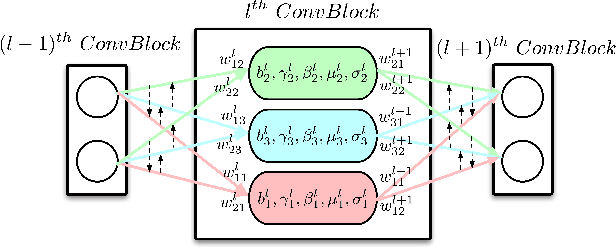
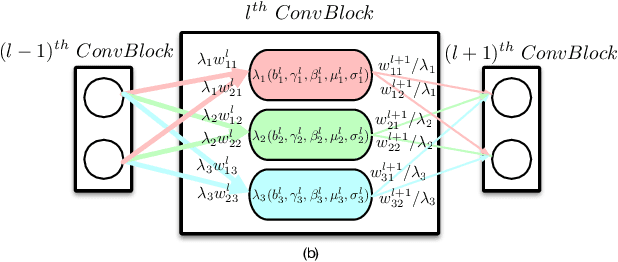
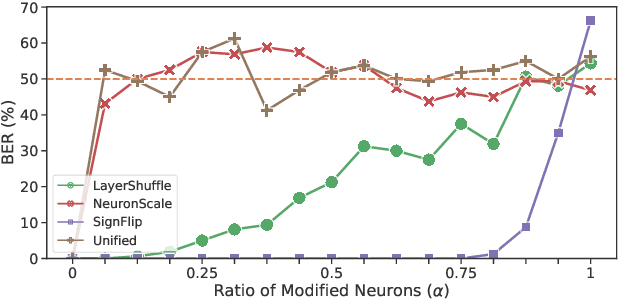
Recently, how to protect the Intellectual Property (IP) of deep neural networks (DNN) becomes a major concern for the AI industry. To combat potential model piracy, recent works explore various watermarking strategies to embed secret identity messages into the prediction behaviors or the internals (e.g., weights and neuron activation) of the target model. Sacrificing less functionality and involving more knowledge about the target model, the latter branch of watermarking schemes (i.e., white-box model watermarking) is claimed to be accurate, credible and secure against most known watermark removal attacks, with emerging research efforts and applications in the industry. In this paper, we present the first effective removal attack which cracks almost all the existing white-box watermarking schemes with provably no performance overhead and no required prior knowledge. By analyzing these IP protection mechanisms at the granularity of neurons, we for the first time discover their common dependence on a set of fragile features of a local neuron group, all of which can be arbitrarily tampered by our proposed chain of invariant neuron transforms. On $9$ state-of-the-art white-box watermarking schemes and a broad set of industry-level DNN architectures, our attack for the first time reduces the embedded identity message in the protected models to be almost random. Meanwhile, unlike known removal attacks, our attack requires no prior knowledge on the training data distribution or the adopted watermark algorithms, and leaves model functionality intact.
Theory-Oriented Deep Leakage from Gradients via Linear Equation Solver
Oct 26, 2020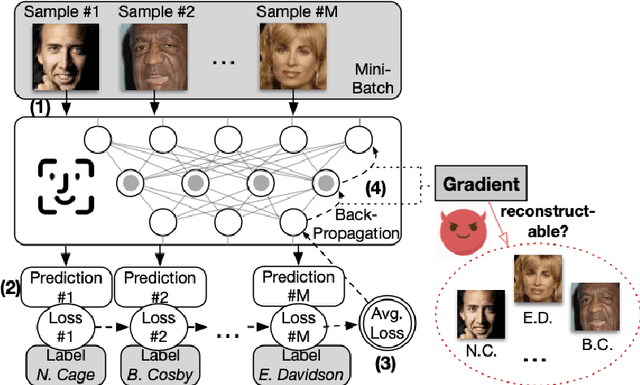
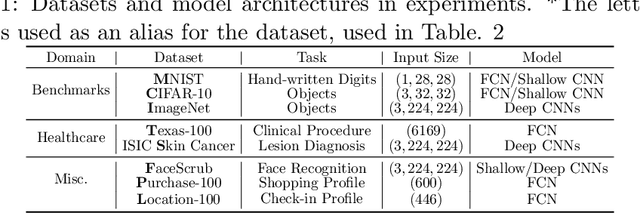
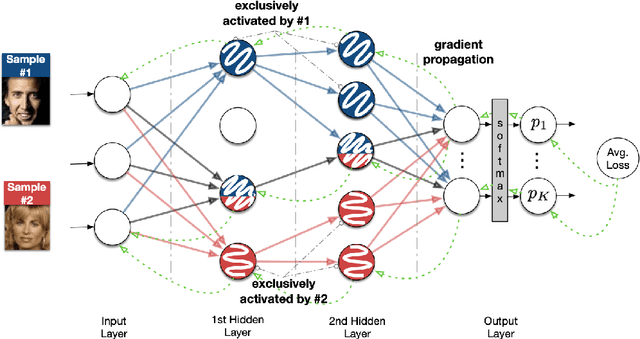
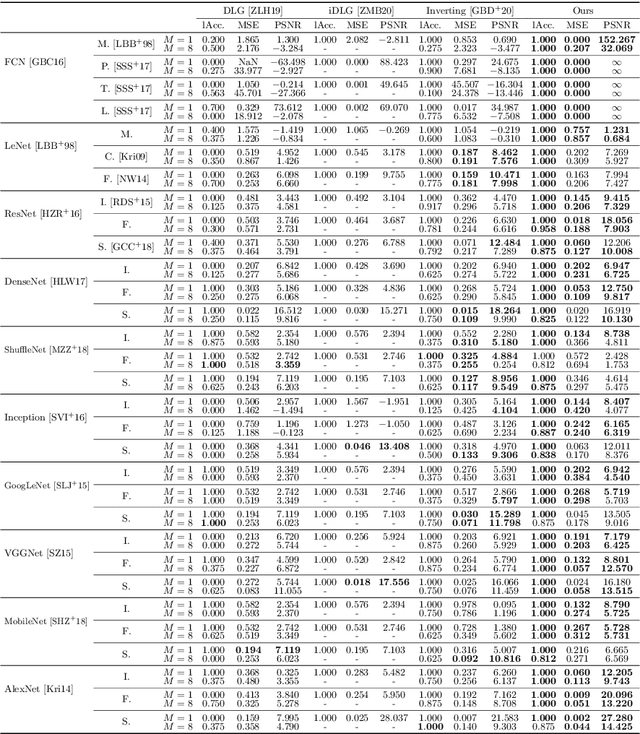
In this paper, we take a theory-oriented approach to systematically study the privacy properties of gradients from a broad class of neural networks with rectified linear units (ReLU), probably the most popular activation function used in current deep learning practices. By utilizing some intrinsic properties of neural networks with ReLU, we prove the existence of exclusively activated neurons is critical to the separability of the activation patterns of different samples. Intuitively, an activation pattern is like the fingerprint of the corresponding sample during the training process. With the separated activation patterns, we for the first time show the equivalence of data reconstruction attacks with a sparse linear equation system. In practice, we propose a novel data reconstruction attack on fully-connected neural networks and extend the attack to more commercial convolutional neural network architectures. Our systematic evaluations cover more than $10$ representative neural network architectures (e.g., GoogLeNet, VGGNet and $6$ more), on various real-world scenarios related with healthcare, medical imaging, location, face recognition and shopping behaviors. In the majority of test cases, our proposed attack is able to infer ground-truth labels in the training batch with near $100\%$ accuracy, reconstruct the input data to fully-connected neural networks with lower than $10^{-6}$ MSE error, and provide better reconstruction results on both shallow and deep convolutional neural networks than previous attacks.