 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCracking White-box DNN Watermarks via Invariant Neuron Transforms
Paper and Code
May 19, 2022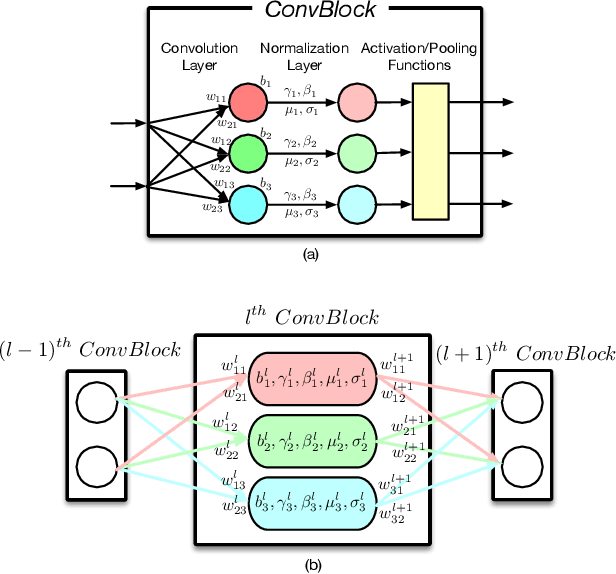
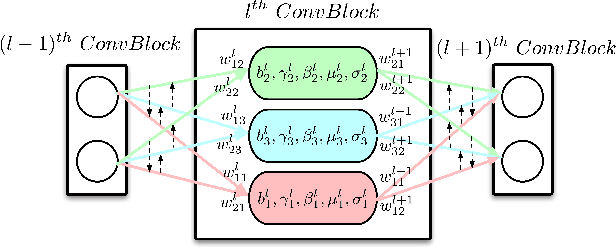
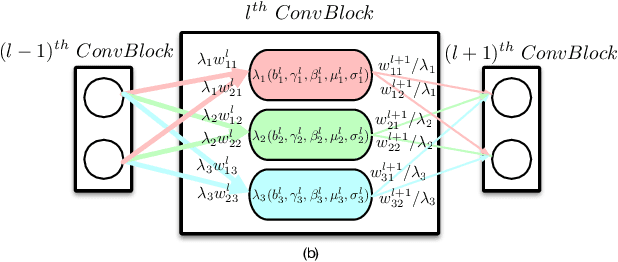
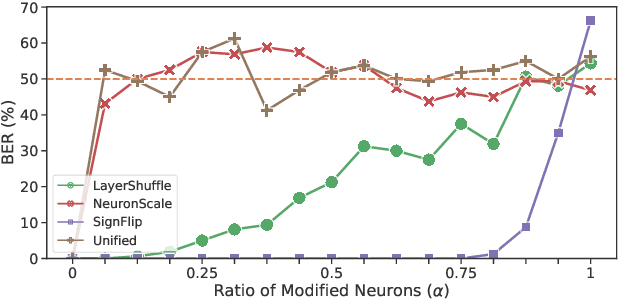
Recently, how to protect the Intellectual Property (IP) of deep neural networks (DNN) becomes a major concern for the AI industry. To combat potential model piracy, recent works explore various watermarking strategies to embed secret identity messages into the prediction behaviors or the internals (e.g., weights and neuron activation) of the target model. Sacrificing less functionality and involving more knowledge about the target model, the latter branch of watermarking schemes (i.e., white-box model watermarking) is claimed to be accurate, credible and secure against most known watermark removal attacks, with emerging research efforts and applications in the industry. In this paper, we present the first effective removal attack which cracks almost all the existing white-box watermarking schemes with provably no performance overhead and no required prior knowledge. By analyzing these IP protection mechanisms at the granularity of neurons, we for the first time discover their common dependence on a set of fragile features of a local neuron group, all of which can be arbitrarily tampered by our proposed chain of invariant neuron transforms. On $9$ state-of-the-art white-box watermarking schemes and a broad set of industry-level DNN architectures, our attack for the first time reduces the embedded identity message in the protected models to be almost random. Meanwhile, unlike known removal attacks, our attack requires no prior knowledge on the training data distribution or the adopted watermark algorithms, and leaves model functionality intact.