 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliced Recurrent Neural Networks
Paper and Code
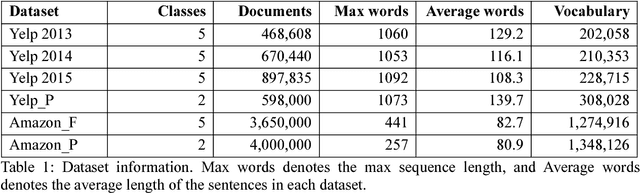
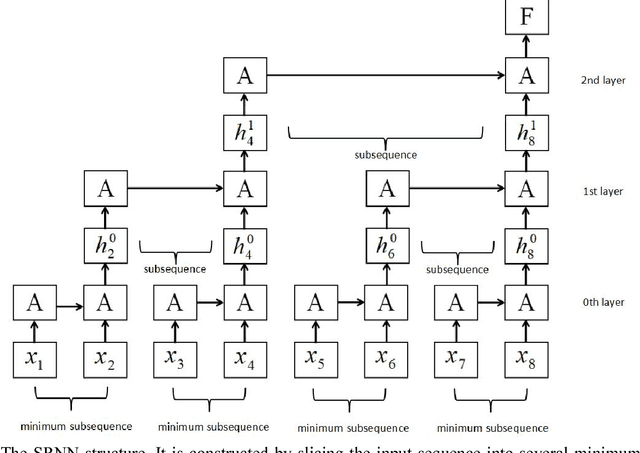
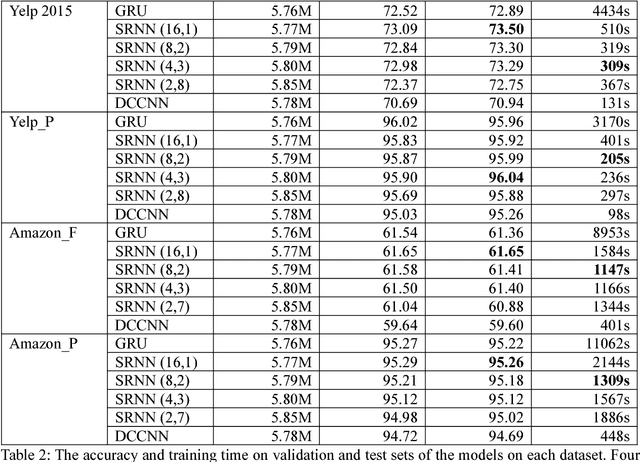
Recurrent neural networks have achieved great success in many NLP tasks. However, they have difficulty in parallelization because of the recurrent structure, so it takes much time to train RNNs. In this paper, we introduce sliced recurrent neural networks (SRNNs), which could be parallelized by slicing the sequences into many subsequences. SRNNs have the ability to obtain high-level information through multiple layers with few extra parameters. We prove that the standard RNN is a special case of the SRNN when we use linear activation functions. Without changing the recurrent units, SRNNs are 136 times as fast as standard RNNs and could be even faster when we train longer sequences. Experiments on six largescale sentiment analysis datasets show that SRNNs achieve better performance than standard RNNs.