 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproxTrain: Fast Simulation of Approximate Multipliers for DNN Training and Inference
Paper and Code


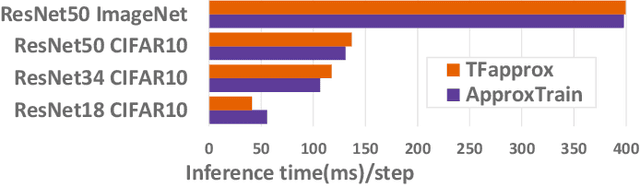
Edge training of Deep Neural Networks (DNNs) is a desirable goal for continuous learning; however, it is hindered by the enormous computational power required by training. Hardware approximate multipliers have shown their effectiveness for gaining resource-efficiency in DNN inference accelerators; however, training with approximate multipliers is largely unexplored. To build resource efficient accelerators with approximate multipliers supporting DNN training, a thorough evaluation of training convergence and accuracy for different DNN architectures and different approximate multipliers is needed. This paper presents ApproxTrain, an open-source framework that allows fast evaluation of DNN training and inference using simulated approximate multipliers. ApproxTrain is as user-friendly as TensorFlow (TF) and requires only a high-level description of a DNN architecture along with C/C++ functional models of the approximate multiplier. We improve the speed of the simulation at the multiplier level by using a novel LUT-based approximate floating-point (FP) multiplier simulator on GPU (AMSim). ApproxTrain leverages CUDA and efficiently integrates AMSim into the TensorFlow library, in order to overcome the absence of native hardware approximate multiplier in commercial GPUs. We use ApproxTrain to evaluate the convergence and accuracy of DNN training with approximate multipliers for small and large datasets (including ImageNet) using LeNets and ResNets architectures. The evaluations demonstrate similar convergence behavior and negligible change in test accuracy compared to FP32 and bfloat16 multipliers. Compared to CPU-based approximate multiplier simulations in training and inference, the GPU-accelerated ApproxTrain is more than 2500x faster. Based on highly optimized closed-source cuDNN/cuBLAS libraries with native hardware multipliers, the original TensorFlow is only 8x faster than ApproxTrain.