 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing-In-Memory Neural Network Accelerators for Safety-Critical Systems: Can Small Device Variations Be Disastrous?
Paper and Code
Jul 15, 2022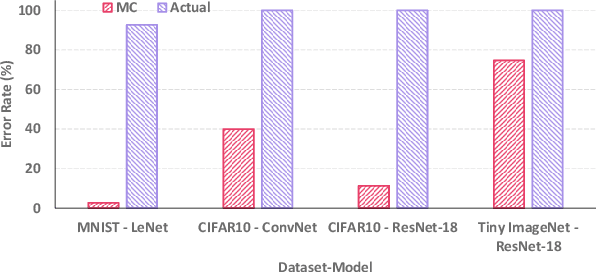

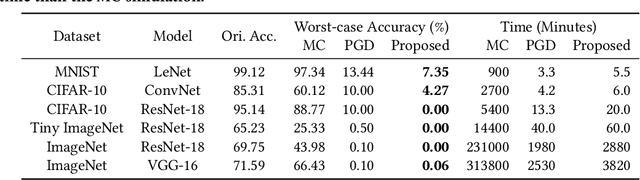
Computing-in-Memory (CiM) architectures based on emerging non-volatile memory (NVM) devices have demonstrated great potential for deep neural network (DNN) acceleration thanks to their high energy efficiency. However, NVM devices suffer from various non-idealities, especially device-to-device variations due to fabrication defects and cycle-to-cycle variations due to the stochastic behavior of devices. As such, the DNN weights actually mapped to NVM devices could deviate significantly from the expected values, leading to large performance degradation. To address this issue, most existing works focus on maximizing average performance under device variations. This objective would work well for general-purpose scenarios. But for safety-critical applications, the worst-case performance must also be considered. Unfortunately, this has been rarely explored in the literature. In this work, we formulate the problem of determining the worst-case performance of CiM DNN accelerators under the impact of device variations. We further propose a method to effectively find the specific combination of device variation in the high-dimensional space that leads to the worst-case performance. We find that even with very small device variations, the accuracy of a DNN can drop drastically, causing concerns when deploying CiM accelerators in safety-critical applications. Finally, we show that surprisingly none of the existing methods used to enhance average DNN performance in CiM accelerators are very effective when extended to enhance the worst-case performance, and further research down the road is needed to address this problem.