 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynaptogen: A cross-domain generative device model for large-scale neuromorphic circuit design
Apr 09, 2024



We present a fast generative modeling approach for resistive memories that reproduces the complex statistical properties of real-world devices. To enable efficient modeling of analog circuits, the model is implemented in Verilog-A. By training on extensive measurement data of integrated 1T1R arrays (6,000 cycles of 512 devices), an autoregressive stochastic process accurately accounts for the cross-correlations between the switching parameters, while non-linear transformations ensure agreement with both cycle-to-cycle (C2C) and device-to-device (D2D) variability. Benchmarks show that this statistically comprehensive model achieves read/write throughputs exceeding those of even highly simplified and deterministic compact models.
A Compact Model of Threshold Switching Devices for Efficient Circuit Simulations
Aug 03, 2023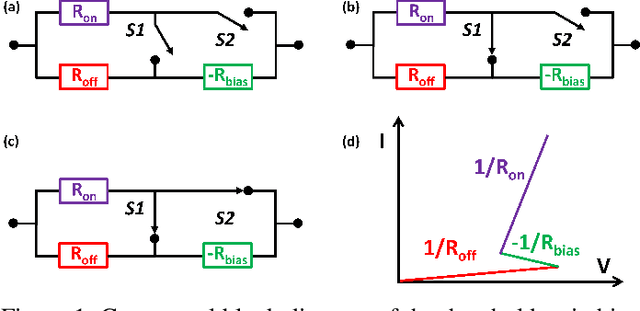
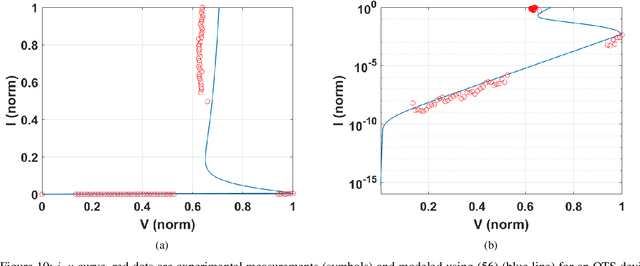
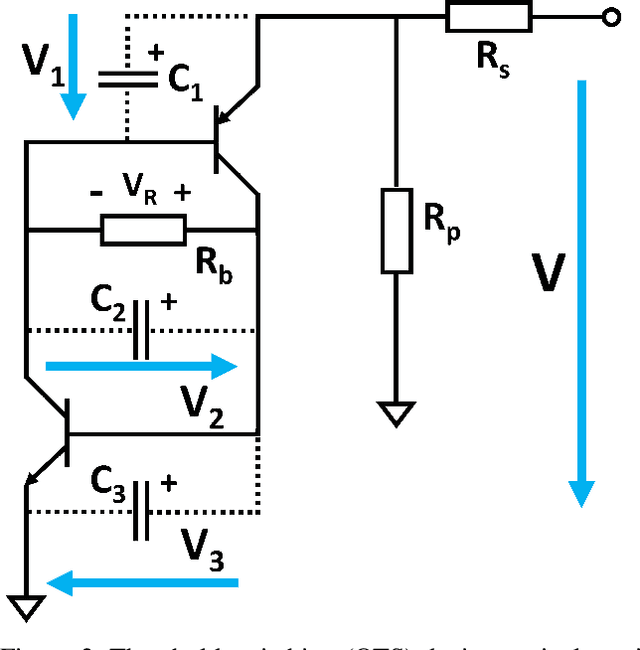
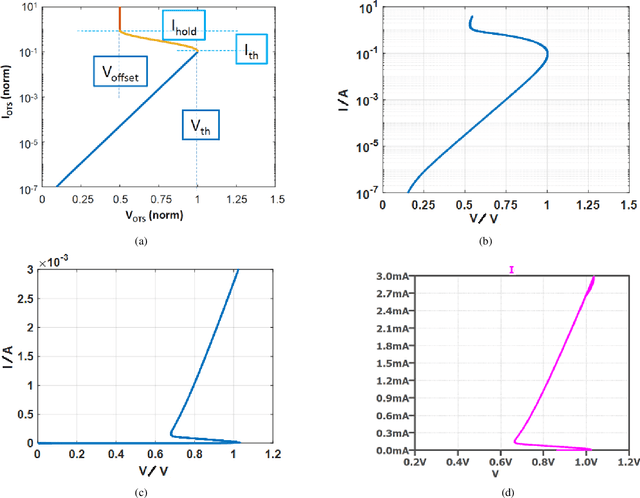
In this paper, we present a new compact model of threshold switching devices which is suitable for efficient circuit-level simulations. First, a macro model, based on a compact transistor based circuit, was implemented in LTSPICE. Then, a descriptive model was extracted and implemented in MATLAB, which is based on the macro model. This macro model was extended to develop a physical model that describes the processes that occur during the threshold switching. The physical model derived comprises a delay structure with few electrical components adjacent to the second junction. The delay model incorporates an internal state variable, which is crucial to transform the descriptive model into a compact model and to parameterize it in terms of electrical parameters that represent the component's behavior. Finally, we applied our model by fitting measured i-v data of an OTS device manufactured by Western Digital Research.
Non-Volatile Memory Array Based Quantization- and Noise-Resilient LSTM Neural Networks
Feb 25, 2020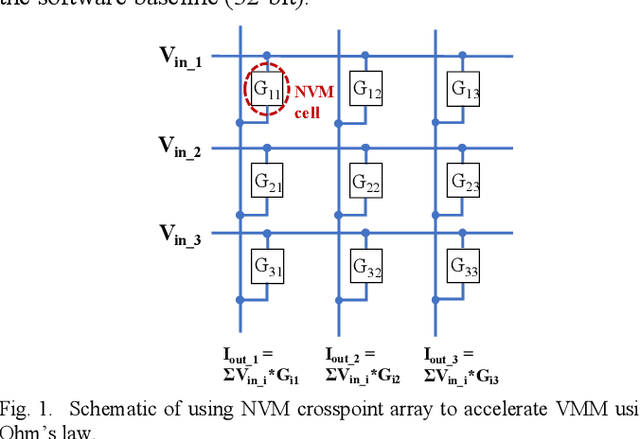
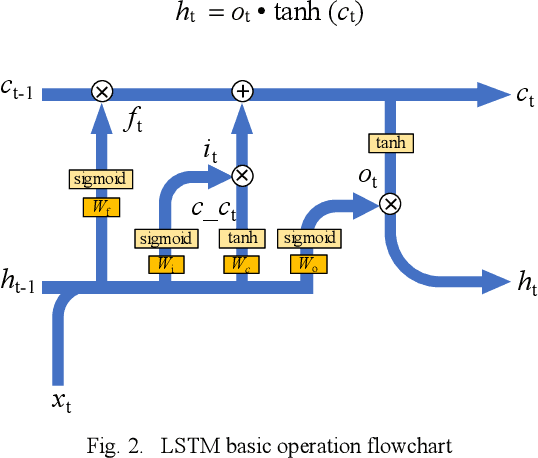
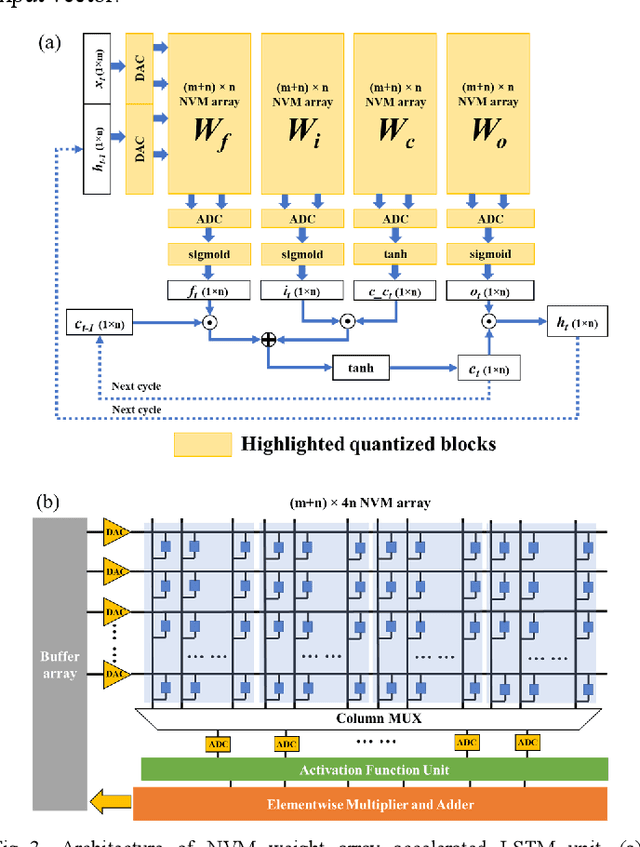
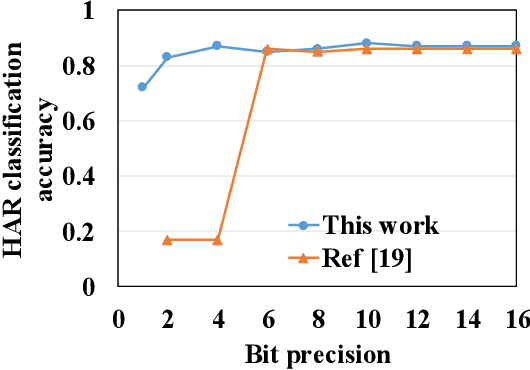
In cloud and edge computing models, it is important that compute devices at the edge be as power efficient as possible. Long short-term memory (LSTM) neural networks have been widely used for natural language processing, time series prediction and many other sequential data tasks. Thus, for these applications there is increasing need for low-power accelerators for LSTM model inference at the edge. In order to reduce power dissipation due to data transfers within inference devices, there has been significant interest in accelerating vector-matrix multiplication (VMM) operations using non-volatile memory (NVM) weight arrays. In NVM array-based hardware, reduced bit-widths also significantly increases the power efficiency. In this paper, we focus on the application of quantization-aware training algorithm to LSTM models, and the benefits these models bring in terms of resilience against both quantization error and analog device noise. We have shown that only 4-bit NVM weights and 4-bit ADC/DACs are needed to produce equivalent LSTM network performance as floating-point baseline. Reasonable levels of ADC quantization noise and weight noise can be naturally tolerated within our NVMbased quantized LSTM network. Benchmark analysis of our proposed LSTM accelerator for inference has shown at least 2.4x better computing efficiency and 40x higher area efficiency than traditional digital approaches (GPU, FPGA, and ASIC). Some other novel approaches based on NVM promise to deliver higher computing efficiency (up to 4.7x) but require larger arrays with potential higher error rates.