 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXBTorch: A Unified Framework for Modeling and Co-Design of Crossbar-Based Deep Learning Accelerators
Jan 11, 2026Emerging memory technologies have gained significant attention as a promising pathway to overcome the limitations of conventional computing architectures in deep learning applications. By enabling computation directly within memory, these technologies - built on nanoscale devices with tunable and nonvolatile conductance - offer the potential to drastically reduce energy consumption and latency compared to traditional von Neumann systems. This paper introduces XBTorch (short for CrossBarTorch), a novel simulation framework that integrates seamlessly with PyTorch and provides specialized tools for accurately and efficiently modeling crossbar-based systems based on emerging memory technologies. Through detailed comparisons and case studies involving hardware-aware training and inference, we demonstrate how XBTorch offers a unified interface for key research areas such as device-level modeling, cross-layer co-design, and inference-time fault tolerance. While exemplar studies utilize ferroelectric field-effect transistor (FeFET) models, the framework remains technology-agnostic - supporting other emerging memories such as resistive RAM (ReRAM), as well as enabling user-defined custom device models. The code is publicly available at: https://github.com/ADAM-Lab-GW/xbtorch
Layer Ensemble Averaging for Improving Memristor-Based Artificial Neural Network Performance
Apr 24, 2024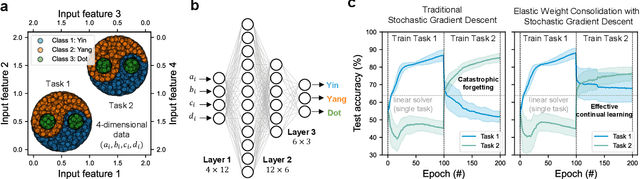
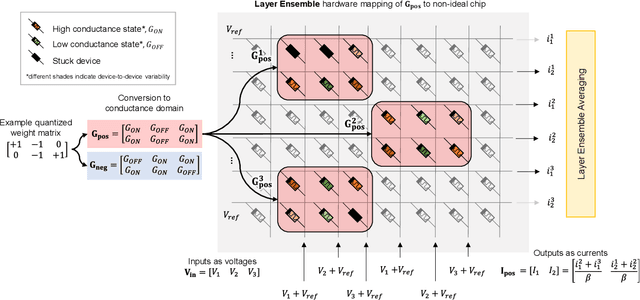
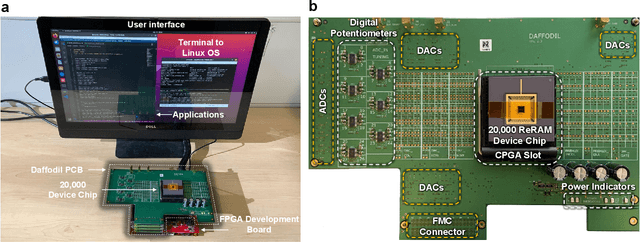
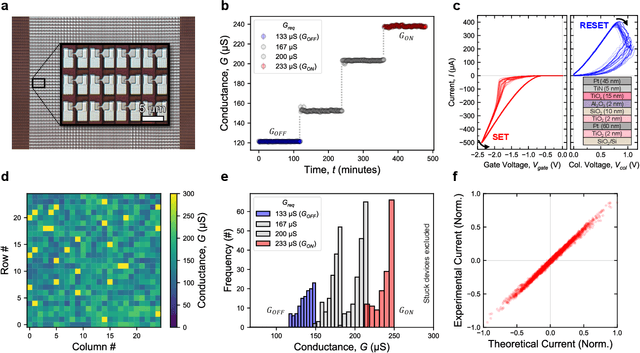
Artificial neural networks have advanced due to scaling dimensions, but conventional computing faces inefficiency due to the von Neumann bottleneck. In-memory computation architectures, like memristors, offer promise but face challenges due to hardware non-idealities. This work proposes and experimentally demonstrates layer ensemble averaging, a technique to map pre-trained neural network solutions from software to defective hardware crossbars of emerging memory devices and reliably attain near-software performance on inference. The approach is investigated using a custom 20,000-device hardware prototyping platform on a continual learning problem where a network must learn new tasks without catastrophically forgetting previously learned information. Results demonstrate that by trading off the number of devices required for layer mapping, layer ensemble averaging can reliably boost defective memristive network performance up to the software baseline. For the investigated problem, the average multi-task classification accuracy improves from 61 % to 72 % (< 1 % of software baseline) using the proposed approach.
Experimental demonstration of a robust training method for strongly defective neuromorphic hardware
Dec 11, 2023The increasing scale of neural networks needed to support more complex applications has led to an increasing requirement for area- and energy-efficient hardware. One route to meeting the budget for these applications is to circumvent the von Neumann bottleneck by performing computation in or near memory. An inevitability of transferring neural networks onto hardware is that non-idealities such as device-to-device variations or poor device yield impact performance. Methods such as hardware-aware training, where substrate non-idealities are incorporated during network training, are one way to recover performance at the cost of solution generality. In this work, we demonstrate inference on hardware neural networks consisting of 20,000 magnetic tunnel junction arrays integrated on a complementary metal-oxide-semiconductor chips that closely resembles market-ready spin transfer-torque magnetoresistive random access memory technology. Using 36 dies, each containing a crossbar array with its own non-idealities, we show that even a small number of defects in physically mapped networks significantly degrades the performance of networks trained without defects and show that, at the cost of generality, hardware-aware training accounting for specific defects on each die can recover to comparable performance with ideal networks. We then demonstrate a robust training method that extends hardware-aware training to statistics-aware training, producing network weights that perform well on most defective dies regardless of their specific defect locations. When evaluated on the 36 physical dies, statistics-aware trained solutions can achieve a mean misclassification error on the MNIST dataset that differs from the software-baseline by only 2 %. This statistics-aware training method could be generalized to networks with many layers that are mapped to hardware suited for industry-ready applications.
Device Modeling Bias in ReRAM-based Neural Network Simulations
Nov 29, 2022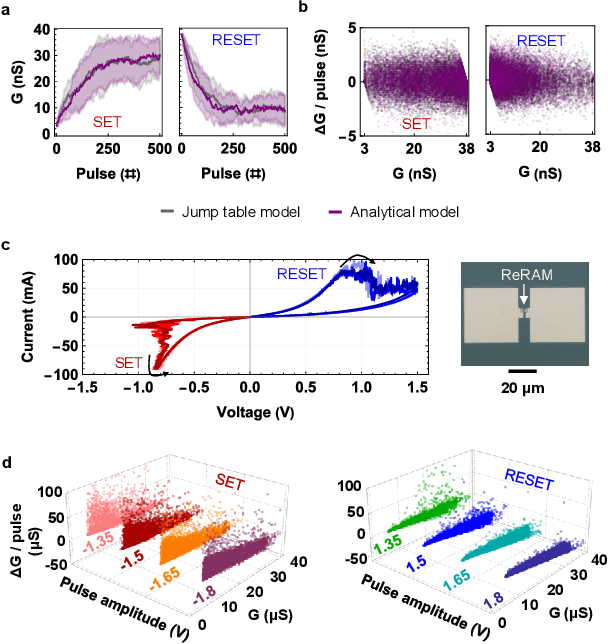
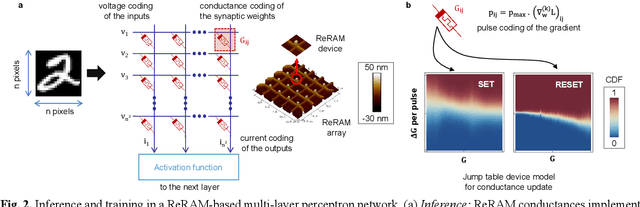
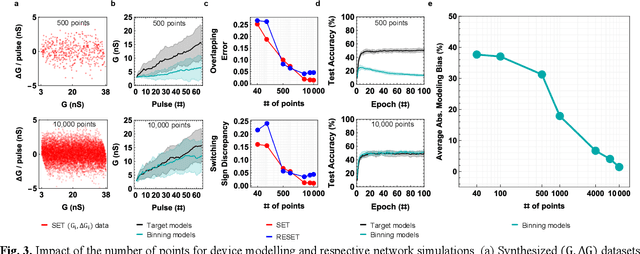
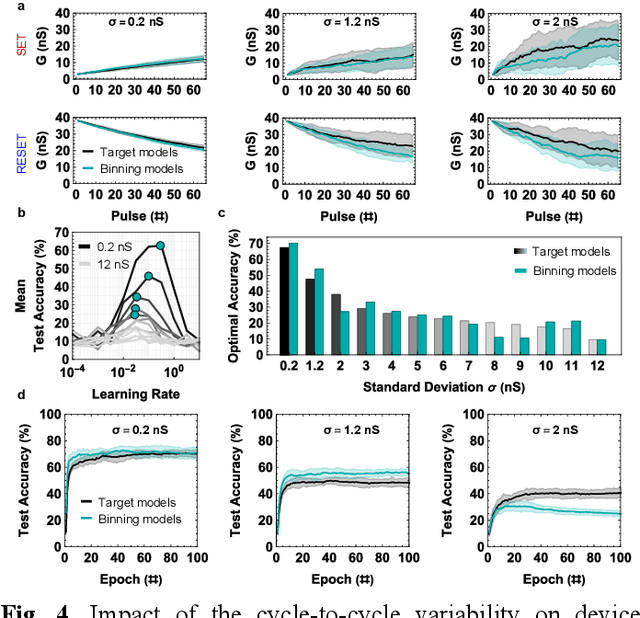
Data-driven modeling approaches such as jump tables are promising techniques to model populations of resistive random-access memory (ReRAM) or other emerging memory devices for hardware neural network simulations. As these tables rely on data interpolation, this work explores the open questions about their fidelity in relation to the stochastic device behavior they model. We study how various jump table device models impact the attained network performance estimates, a concept we define as modeling bias. Two methods of jump table device modeling, binning and Optuna-optimized binning, are explored using synthetic data with known distributions for benchmarking purposes, as well as experimental data obtained from TiOx ReRAM devices. Results on a multi-layer perceptron trained on MNIST show that device models based on binning can behave unpredictably particularly at low number of points in the device dataset, sometimes over-promising, sometimes under-promising target network accuracy. This paper also proposes device level metrics that indicate similar trends with the modeling bias metric at the network level. The proposed approach opens the possibility for future investigations into statistical device models with better performance, as well as experimentally verified modeling bias in different in-memory computing and neural network architectures.
Non-Volatile Memory Array Based Quantization- and Noise-Resilient LSTM Neural Networks
Feb 25, 2020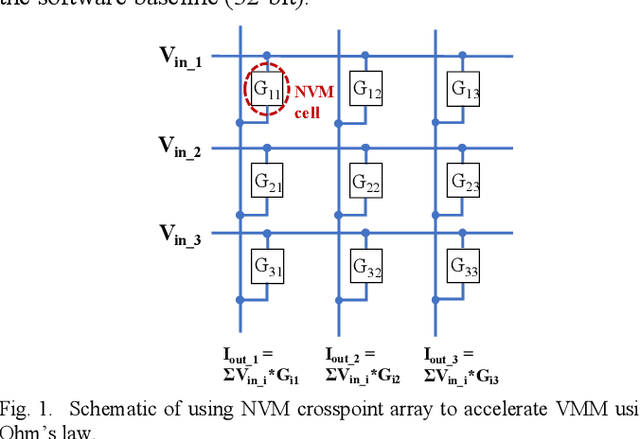
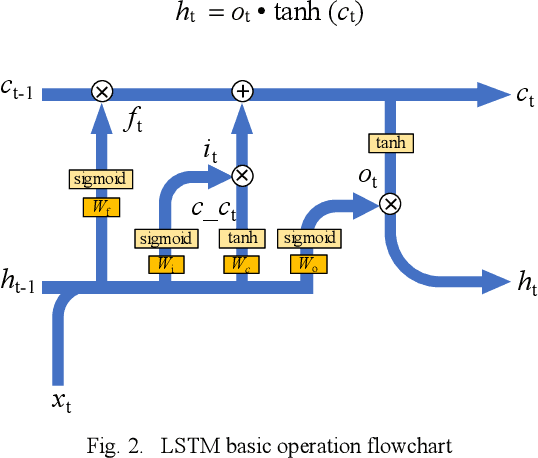
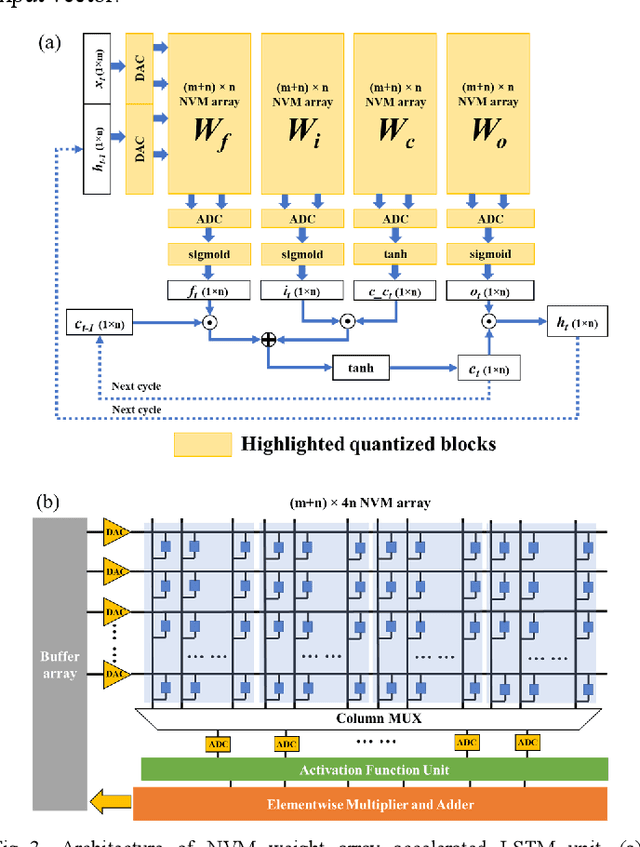
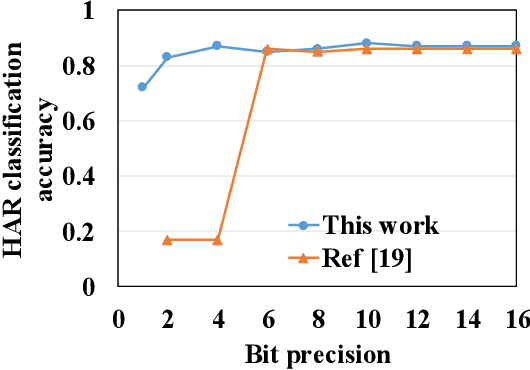
In cloud and edge computing models, it is important that compute devices at the edge be as power efficient as possible. Long short-term memory (LSTM) neural networks have been widely used for natural language processing, time series prediction and many other sequential data tasks. Thus, for these applications there is increasing need for low-power accelerators for LSTM model inference at the edge. In order to reduce power dissipation due to data transfers within inference devices, there has been significant interest in accelerating vector-matrix multiplication (VMM) operations using non-volatile memory (NVM) weight arrays. In NVM array-based hardware, reduced bit-widths also significantly increases the power efficiency. In this paper, we focus on the application of quantization-aware training algorithm to LSTM models, and the benefits these models bring in terms of resilience against both quantization error and analog device noise. We have shown that only 4-bit NVM weights and 4-bit ADC/DACs are needed to produce equivalent LSTM network performance as floating-point baseline. Reasonable levels of ADC quantization noise and weight noise can be naturally tolerated within our NVMbased quantized LSTM network. Benchmark analysis of our proposed LSTM accelerator for inference has shown at least 2.4x better computing efficiency and 40x higher area efficiency than traditional digital approaches (GPU, FPGA, and ASIC). Some other novel approaches based on NVM promise to deliver higher computing efficiency (up to 4.7x) but require larger arrays with potential higher error rates.