 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXBTorch: A Unified Framework for Modeling and Co-Design of Crossbar-Based Deep Learning Accelerators
Jan 11, 2026Emerging memory technologies have gained significant attention as a promising pathway to overcome the limitations of conventional computing architectures in deep learning applications. By enabling computation directly within memory, these technologies - built on nanoscale devices with tunable and nonvolatile conductance - offer the potential to drastically reduce energy consumption and latency compared to traditional von Neumann systems. This paper introduces XBTorch (short for CrossBarTorch), a novel simulation framework that integrates seamlessly with PyTorch and provides specialized tools for accurately and efficiently modeling crossbar-based systems based on emerging memory technologies. Through detailed comparisons and case studies involving hardware-aware training and inference, we demonstrate how XBTorch offers a unified interface for key research areas such as device-level modeling, cross-layer co-design, and inference-time fault tolerance. While exemplar studies utilize ferroelectric field-effect transistor (FeFET) models, the framework remains technology-agnostic - supporting other emerging memories such as resistive RAM (ReRAM), as well as enabling user-defined custom device models. The code is publicly available at: https://github.com/ADAM-Lab-GW/xbtorch
Layer Ensemble Averaging for Improving Memristor-Based Artificial Neural Network Performance
Apr 24, 2024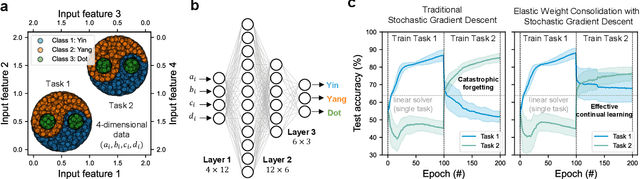
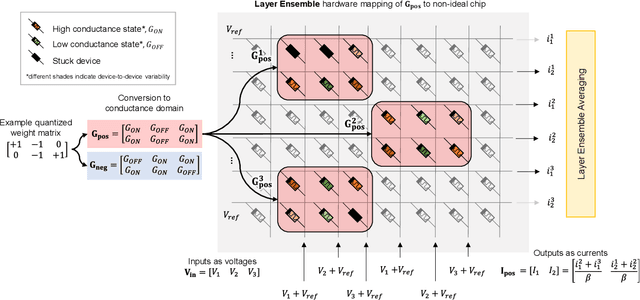
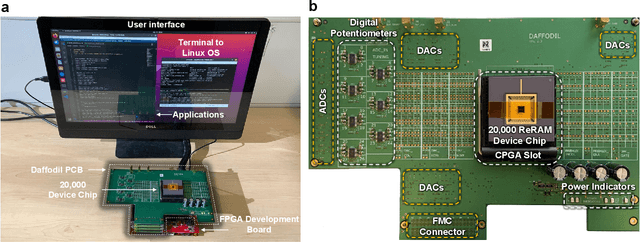
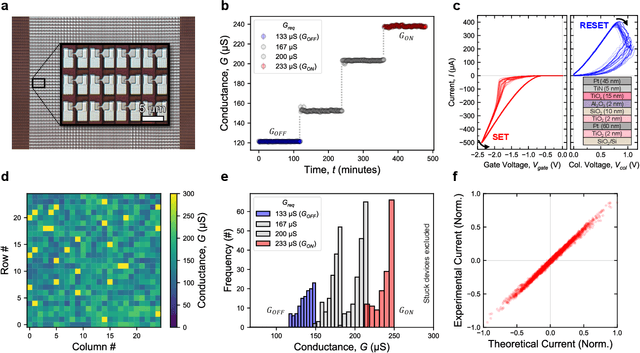
Artificial neural networks have advanced due to scaling dimensions, but conventional computing faces inefficiency due to the von Neumann bottleneck. In-memory computation architectures, like memristors, offer promise but face challenges due to hardware non-idealities. This work proposes and experimentally demonstrates layer ensemble averaging, a technique to map pre-trained neural network solutions from software to defective hardware crossbars of emerging memory devices and reliably attain near-software performance on inference. The approach is investigated using a custom 20,000-device hardware prototyping platform on a continual learning problem where a network must learn new tasks without catastrophically forgetting previously learned information. Results demonstrate that by trading off the number of devices required for layer mapping, layer ensemble averaging can reliably boost defective memristive network performance up to the software baseline. For the investigated problem, the average multi-task classification accuracy improves from 61 % to 72 % (< 1 % of software baseline) using the proposed approach.
Biologically-Informed Excitatory and Inhibitory Balance for Robust Spiking Neural Network Training
Apr 24, 2024Spiking neural networks drawing inspiration from biological constraints of the brain promise an energy-efficient paradigm for artificial intelligence. However, challenges exist in identifying guiding principles to train these networks in a robust fashion. In addition, training becomes an even more difficult problem when incorporating biological constraints of excitatory and inhibitory connections. In this work, we identify several key factors, such as low initial firing rates and diverse inhibitory spiking patterns, that determine the overall ability to train spiking networks with various ratios of excitatory to inhibitory neurons on AI-relevant datasets. The results indicate networks with the biologically realistic 80:20 excitatory:inhibitory balance can reliably train at low activity levels and in noisy environments. Additionally, the Van Rossum distance, a measure of spike train synchrony, provides insight into the importance of inhibitory neurons to increase network robustness to noise. This work supports further biologically-informed large-scale networks and energy efficient hardware implementations.
Device Modeling Bias in ReRAM-based Neural Network Simulations
Nov 29, 2022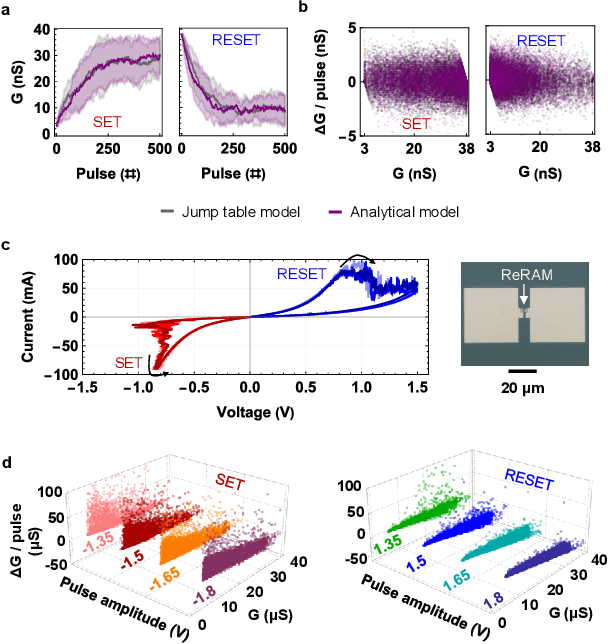
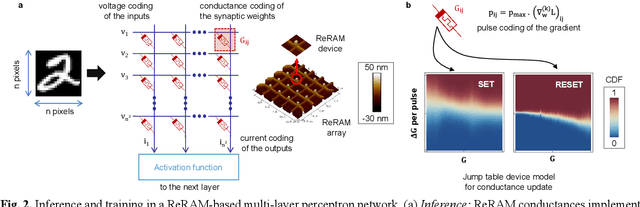
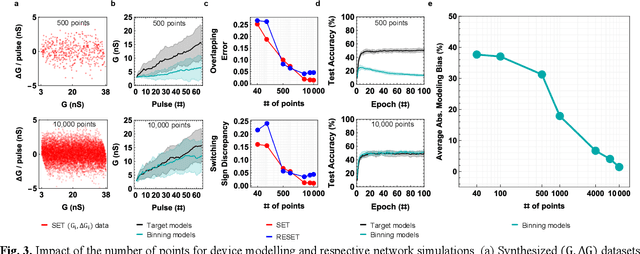
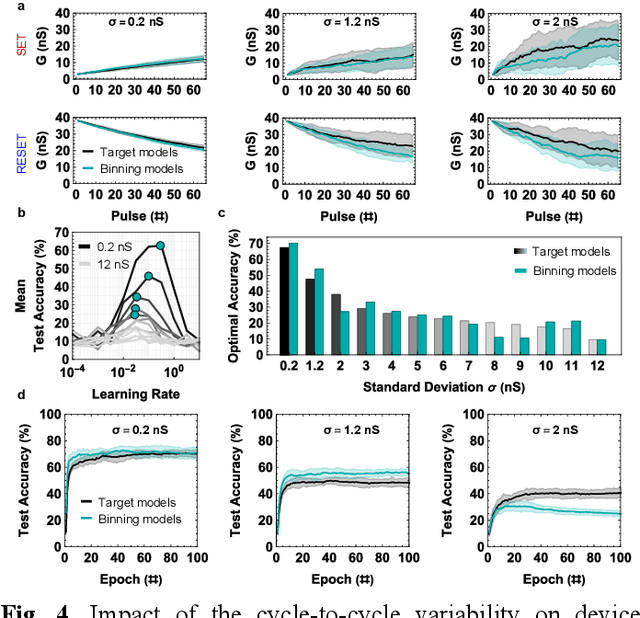
Data-driven modeling approaches such as jump tables are promising techniques to model populations of resistive random-access memory (ReRAM) or other emerging memory devices for hardware neural network simulations. As these tables rely on data interpolation, this work explores the open questions about their fidelity in relation to the stochastic device behavior they model. We study how various jump table device models impact the attained network performance estimates, a concept we define as modeling bias. Two methods of jump table device modeling, binning and Optuna-optimized binning, are explored using synthetic data with known distributions for benchmarking purposes, as well as experimental data obtained from TiOx ReRAM devices. Results on a multi-layer perceptron trained on MNIST show that device models based on binning can behave unpredictably particularly at low number of points in the device dataset, sometimes over-promising, sometimes under-promising target network accuracy. This paper also proposes device level metrics that indicate similar trends with the modeling bias metric at the network level. The proposed approach opens the possibility for future investigations into statistical device models with better performance, as well as experimentally verified modeling bias in different in-memory computing and neural network architectures.
Memory-efficient training with streaming dimensionality reduction
Apr 25, 2020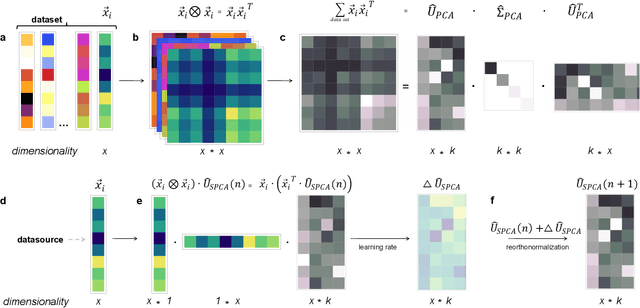
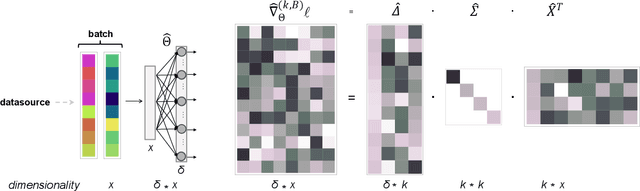
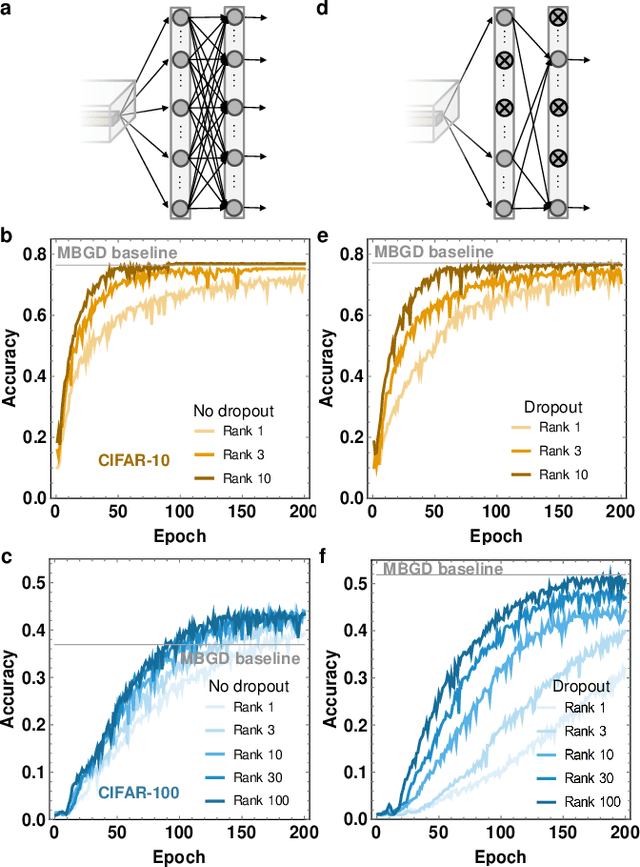
The movement of large quantities of data during the training of a Deep Neural Network presents immense challenges for machine learning workloads. To minimize this overhead, especially on the movement and calculation of gradient information, we introduce streaming batch principal component analysis as an update algorithm. Streaming batch principal component analysis uses stochastic power iterations to generate a stochastic k-rank approximation of the network gradient. We demonstrate that the low rank updates produced by streaming batch principal component analysis can effectively train convolutional neural networks on a variety of common datasets, with performance comparable to standard mini batch gradient descent. These results can lead to both improvements in the design of application specific integrated circuits for deep learning and in the speed of synchronization of machine learning models trained with data parallelism.
Streaming Batch Eigenupdates for Hardware Neuromorphic Networks
Mar 05, 2019
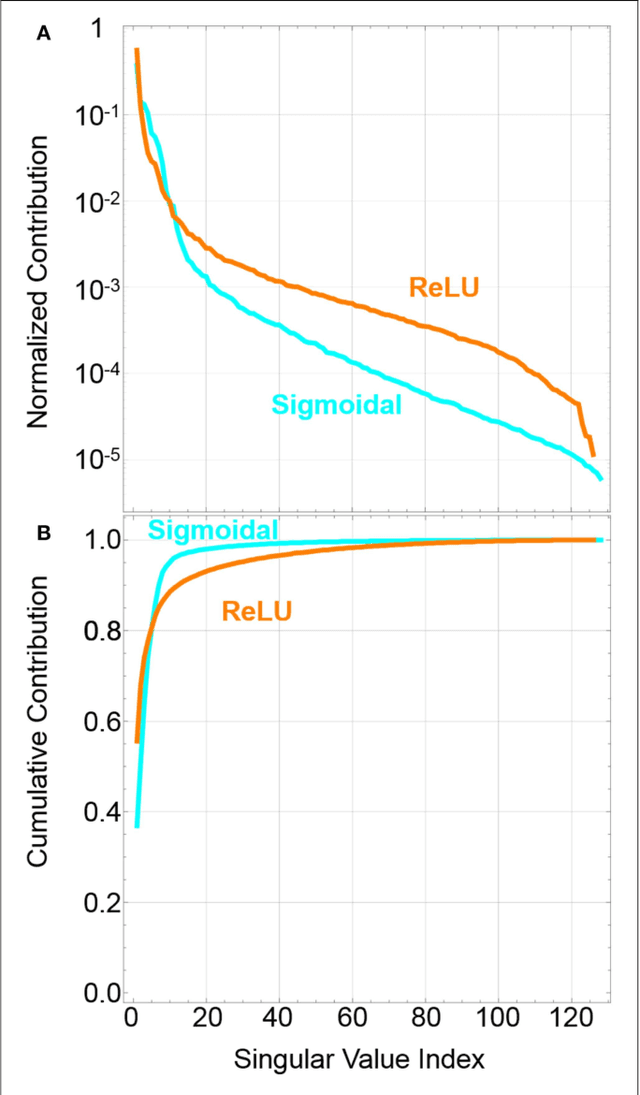
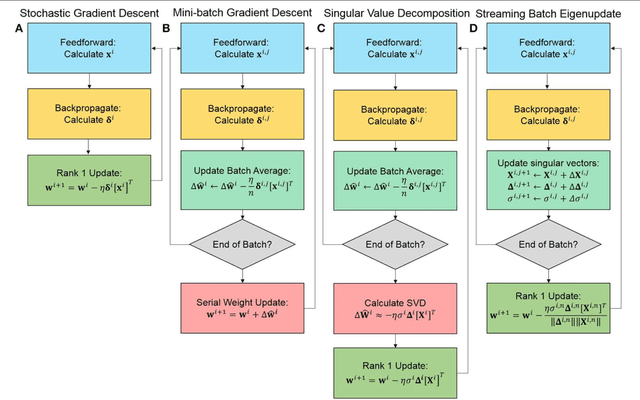
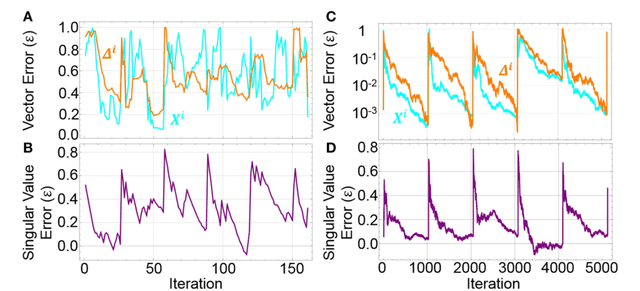
Neuromorphic networks based on nanodevices, such as metal oxide memristors, phase change memories, and flash memory cells, have generated considerable interest for their increased energy efficiency and density in comparison to graphics processing units (GPUs) and central processing units (CPUs). Though immense acceleration of the training process can be achieved by leveraging the fact that the time complexity of training does not scale with the network size, it is limited by the space complexity of stochastic gradient descent, which grows quadratically. The main objective of this work is to reduce this space complexity by using low-rank approximations of stochastic gradient descent. This low spatial complexity combined with streaming methods allows for significant reductions in memory and compute overhead, opening the doors for improvements in area, time and energy efficiency of training. We refer to this algorithm and architecture to implement it as the streaming batch eigenupdate (SBE) approach.