 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling of hardware-compatible perturbative training algorithms
Jan 26, 2025



In this work, we explore the capabilities of multiplexed gradient descent (MGD), a scalable and efficient perturbative zeroth-order training method for estimating the gradient of a loss function in hardware and training it via stochastic gradient descent. We extend the framework to include both weight and node perturbation, and discuss the advantages and disadvantages of each approach. We investigate the time to train networks using MGD as a function of network size and task complexity. Previous research has suggested that perturbative training methods do not scale well to large problems, since in these methods the time to estimate the gradient scales linearly with the number of network parameters. However, in this work we show that the time to reach a target accuracy--that is, actually solve the problem of interest--does not follow this undesirable linear scaling, and in fact often decreases with network size. Furthermore, we demonstrate that MGD can be used to calculate a drop-in replacement for the gradient in stochastic gradient descent, and therefore optimization accelerators such as momentum can be used alongside MGD, ensuring compatibility with existing machine learning practices. Our results indicate that MGD can efficiently train large networks on hardware, achieving accuracy comparable to backpropagation, thus presenting a practical solution for future neuromorphic computing systems.
Layer Ensemble Averaging for Improving Memristor-Based Artificial Neural Network Performance
Apr 24, 2024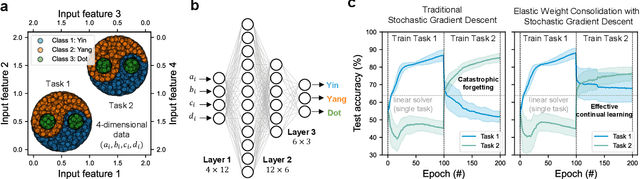
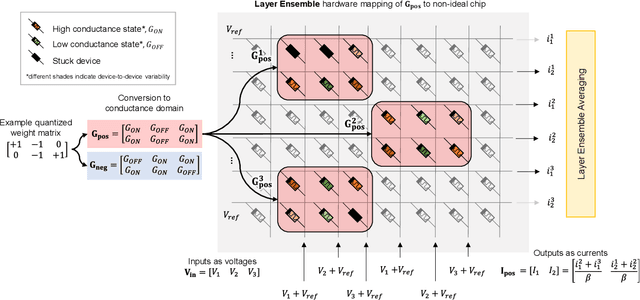
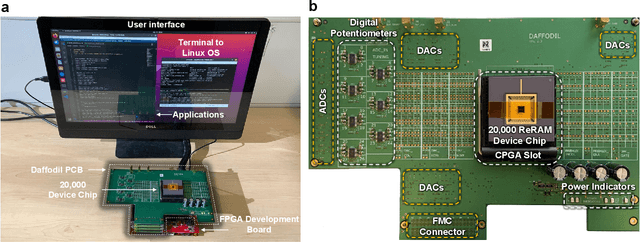
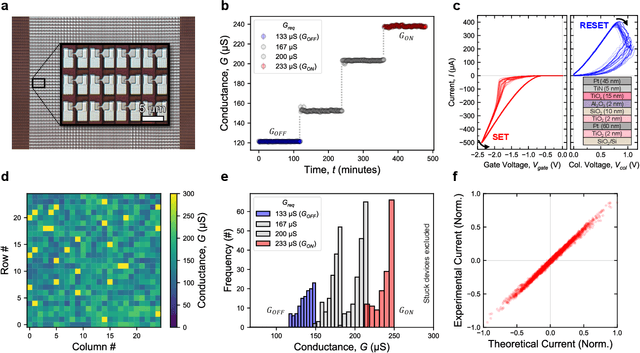
Artificial neural networks have advanced due to scaling dimensions, but conventional computing faces inefficiency due to the von Neumann bottleneck. In-memory computation architectures, like memristors, offer promise but face challenges due to hardware non-idealities. This work proposes and experimentally demonstrates layer ensemble averaging, a technique to map pre-trained neural network solutions from software to defective hardware crossbars of emerging memory devices and reliably attain near-software performance on inference. The approach is investigated using a custom 20,000-device hardware prototyping platform on a continual learning problem where a network must learn new tasks without catastrophically forgetting previously learned information. Results demonstrate that by trading off the number of devices required for layer mapping, layer ensemble averaging can reliably boost defective memristive network performance up to the software baseline. For the investigated problem, the average multi-task classification accuracy improves from 61 % to 72 % (< 1 % of software baseline) using the proposed approach.
Multiplexed gradient descent: Fast online training of modern datasets on hardware neural networks without backpropagation
Mar 05, 2023We present multiplexed gradient descent (MGD), a gradient descent framework designed to easily train analog or digital neural networks in hardware. MGD utilizes zero-order optimization techniques for online training of hardware neural networks. We demonstrate its ability to train neural networks on modern machine learning datasets, including CIFAR-10 and Fashion-MNIST, and compare its performance to backpropagation. Assuming realistic timescales and hardware parameters, our results indicate that these optimization techniques can train a network on emerging hardware platforms orders of magnitude faster than the wall-clock time of training via backpropagation on a standard GPU, even in the presence of imperfect weight updates or device-to-device variations in the hardware. We additionally describe how it can be applied to existing hardware as part of chip-in-the-loop training, or integrated directly at the hardware level. Crucially, the MGD framework is highly flexible, and its gradient descent process can be optimized to compensate for specific hardware limitations such as slow parameter-update speeds or limited input bandwidth.
Device Modeling Bias in ReRAM-based Neural Network Simulations
Nov 29, 2022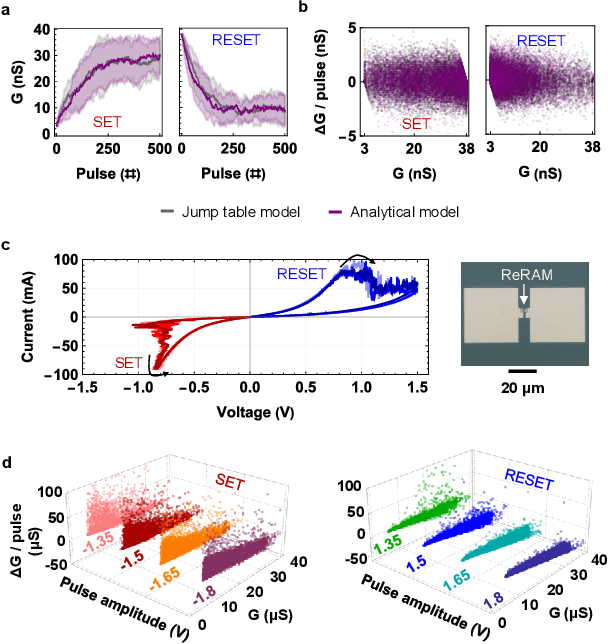
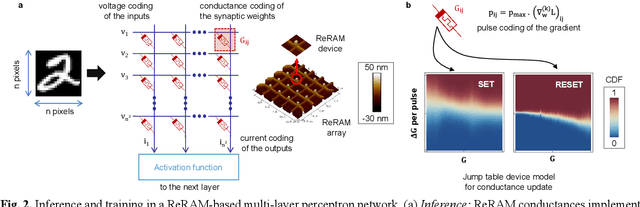
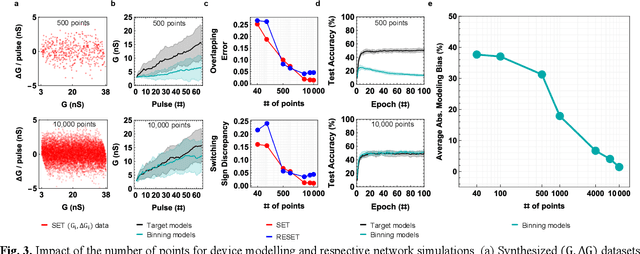
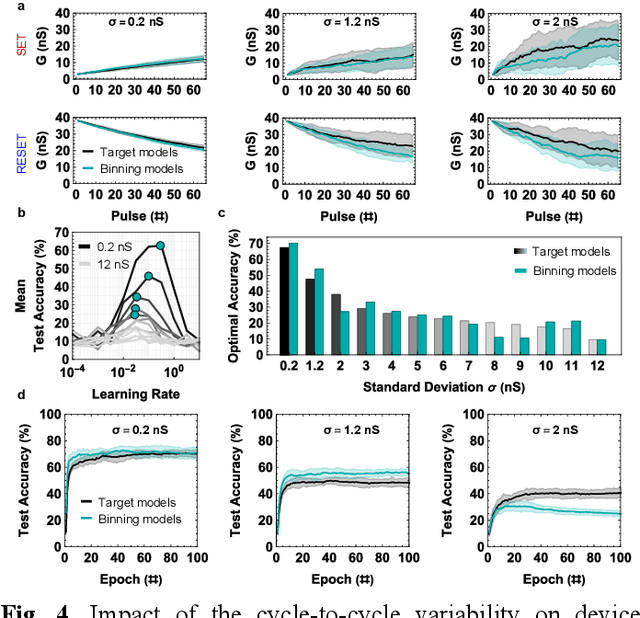
Data-driven modeling approaches such as jump tables are promising techniques to model populations of resistive random-access memory (ReRAM) or other emerging memory devices for hardware neural network simulations. As these tables rely on data interpolation, this work explores the open questions about their fidelity in relation to the stochastic device behavior they model. We study how various jump table device models impact the attained network performance estimates, a concept we define as modeling bias. Two methods of jump table device modeling, binning and Optuna-optimized binning, are explored using synthetic data with known distributions for benchmarking purposes, as well as experimental data obtained from TiOx ReRAM devices. Results on a multi-layer perceptron trained on MNIST show that device models based on binning can behave unpredictably particularly at low number of points in the device dataset, sometimes over-promising, sometimes under-promising target network accuracy. This paper also proposes device level metrics that indicate similar trends with the modeling bias metric at the network level. The proposed approach opens the possibility for future investigations into statistical device models with better performance, as well as experimentally verified modeling bias in different in-memory computing and neural network architectures.
Multi-Criteria Radio Spectrum Sharing With Subspace-Based Pareto Tracing
Aug 23, 2021
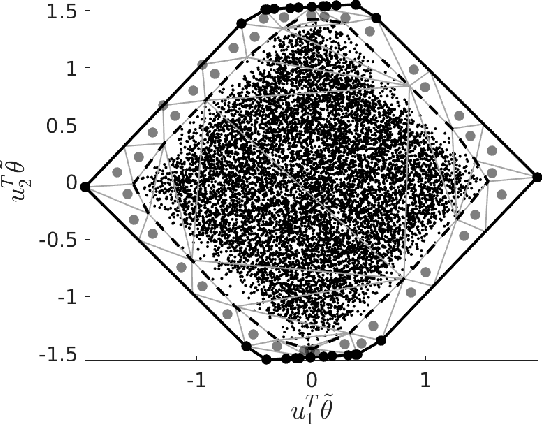
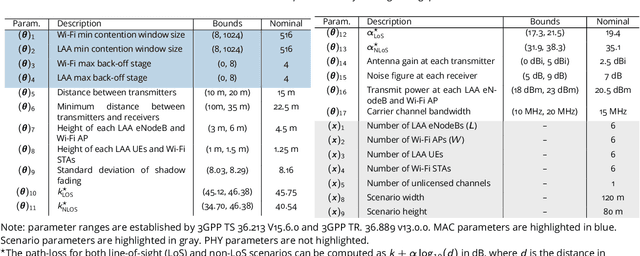
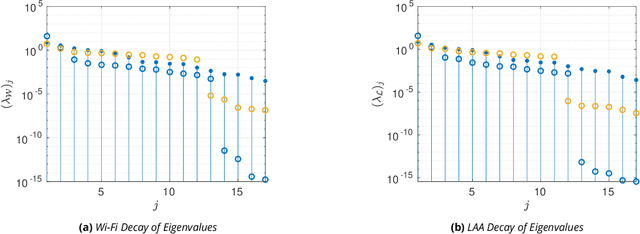
Radio spectrum is a high-demand finite resource. To meet growing demands of data throughput for forthcoming and deployed wireless networks, new wireless technologies must operate in shared spectrum over unlicensed bands (coexist). As an example application, we consider a model of Long-Term Evolution (LTE) License-Assisted Access (LAA) with incumbent IEEE 802.11 wireless-fidelity (Wi-Fi) systems in a coexistence scenario. This scenario considers multiple LAA and Wi-Fi links sharing an unlicensed band; however, a multitude of other scenarios could be applicable to our general approach. We aim to improve coexistence by maximizing the key performance indicators (KPIs) of two networks simultaneously via dimension reduction and multi-criteria optimization. These KPIs are network throughputs as a function of medium access control (MAC) protocols and physical layer parameters. We perform an exploratory analysis of coexistence behavior by approximating active subspaces to identify low-dimensional structure in the optimization criteria, i.e., few linear combinations of parameters for simultaneously maximizing LAA and Wi-Fi throughputs. We take advantage of an aggregate low-dimensional subspace parametrized by approximate active subspaces of both throughputs to regularize a multi-criteria optimization. Additionally, a choice of two-dimensional subspace enables visualizations augmenting interpretability and explainability of the results. The visualizations and approximations suggest a predominantly convex set of KPIs over active coordinates leading to a regularized manifold of approximately Pareto optimal solutions. Subsequent geodesics lead to continuous traces through parameter space constituting non-dominated solutions in contrast to random grid search.