 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice Modeling Bias in ReRAM-based Neural Network Simulations
Paper and Code
Nov 29, 2022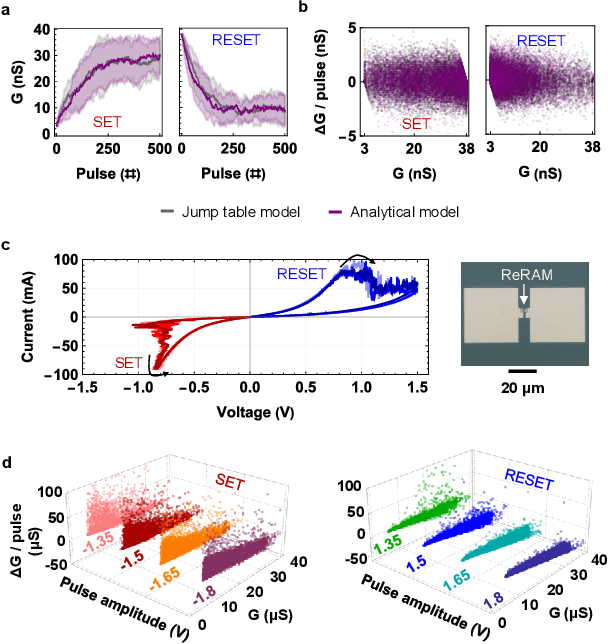
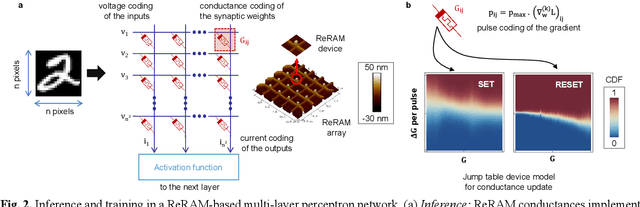
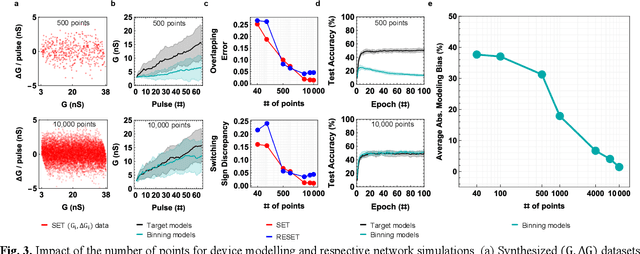
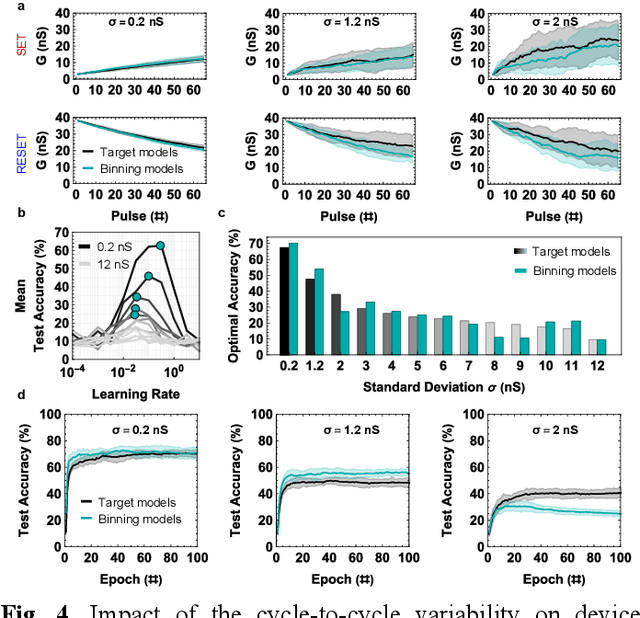
Data-driven modeling approaches such as jump tables are promising techniques to model populations of resistive random-access memory (ReRAM) or other emerging memory devices for hardware neural network simulations. As these tables rely on data interpolation, this work explores the open questions about their fidelity in relation to the stochastic device behavior they model. We study how various jump table device models impact the attained network performance estimates, a concept we define as modeling bias. Two methods of jump table device modeling, binning and Optuna-optimized binning, are explored using synthetic data with known distributions for benchmarking purposes, as well as experimental data obtained from TiOx ReRAM devices. Results on a multi-layer perceptron trained on MNIST show that device models based on binning can behave unpredictably particularly at low number of points in the device dataset, sometimes over-promising, sometimes under-promising target network accuracy. This paper also proposes device level metrics that indicate similar trends with the modeling bias metric at the network level. The proposed approach opens the possibility for future investigations into statistical device models with better performance, as well as experimentally verified modeling bias in different in-memory computing and neural network architectures.