 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA dual-branch model with inter- and intra-branch contrastive loss for long-tailed recognition
Sep 28, 2023Real-world data often exhibits a long-tailed distribution, in which head classes occupy most of the data, while tail classes only have very few samples. Models trained on long-tailed datasets have poor adaptability to tail classes and the decision boundaries are ambiguous. Therefore, in this paper, we propose a simple yet effective model, named Dual-Branch Long-Tailed Recognition (DB-LTR), which includes an imbalanced learning branch and a Contrastive Learning Branch (CoLB). The imbalanced learning branch, which consists of a shared backbone and a linear classifier, leverages common imbalanced learning approaches to tackle the data imbalance issue. In CoLB, we learn a prototype for each tail class, and calculate an inter-branch contrastive loss, an intra-branch contrastive loss and a metric loss. CoLB can improve the capability of the model in adapting to tail classes and assist the imbalanced learning branch to learn a well-represented feature space and discriminative decision boundary. Extensive experiments on three long-tailed benchmark datasets, i.e., CIFAR100-LT, ImageNet-LT and Places-LT, show that our DB-LTR is competitive and superior to the comparative methods.
* Published at Neural Networks
Deep Reinforcement Learning for Imbalanced Classification
Jan 05, 2019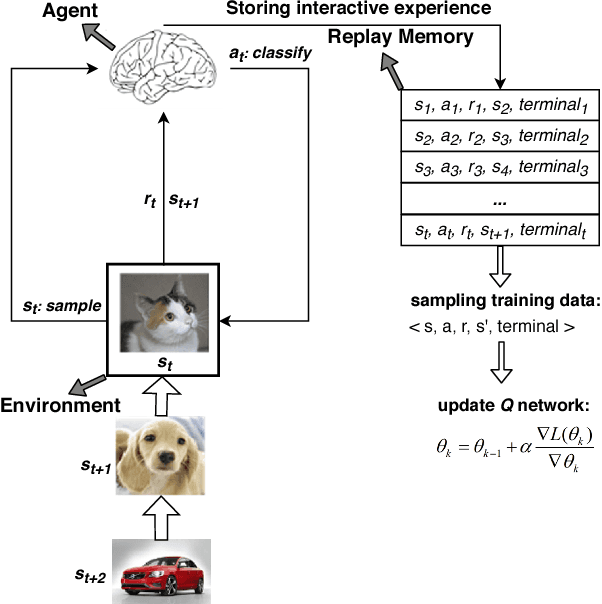

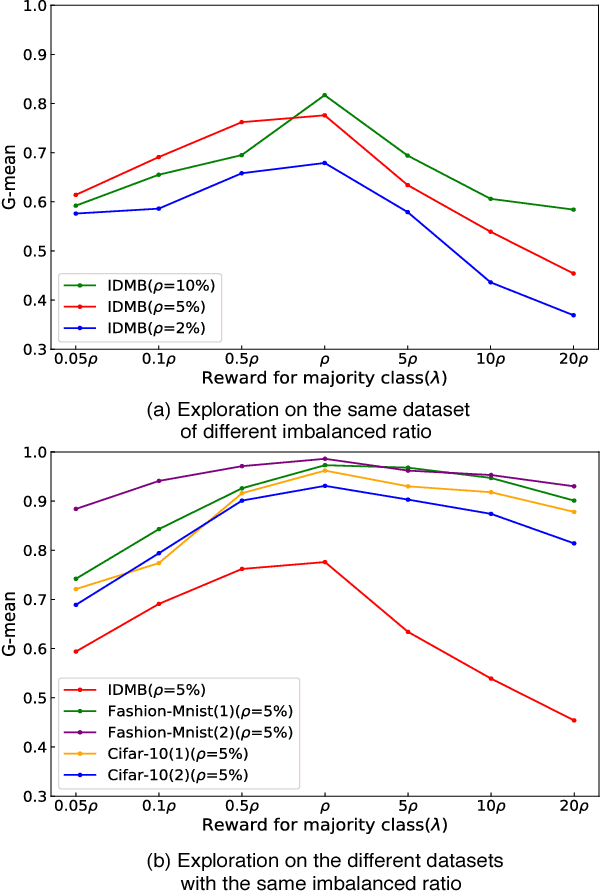
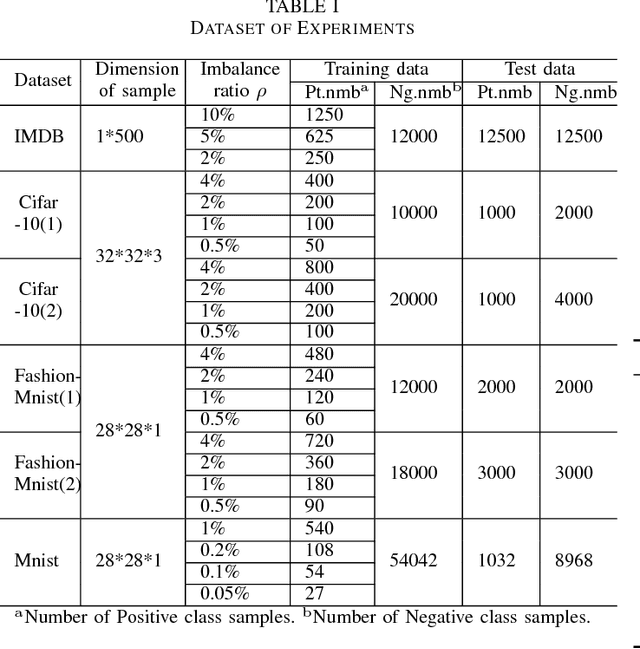
Data in real-world application often exhibit skewed class distribution which poses an intense challenge for machine learning. Conventional classification algorithms are not effective in the case of imbalanced data distribution, and may fail when the data distribution is highly imbalanced. To address this issue, we propose a general imbalanced classification model based on deep reinforcement learning. We formulate the classification problem as a sequential decision-making process and solve it by deep Q-learning network. The agent performs a classification action on one sample at each time step, and the environment evaluates the classification action and returns a reward to the agent. The reward from minority class sample is larger so the agent is more sensitive to the minority class. The agent finally finds an optimal classification policy in imbalanced data under the guidance of specific reward function and beneficial learning environment. Experiments show that our proposed model outperforms the other imbalanced classification algorithms, and it can identify more minority samples and has great classification performance.