 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisinformation Detection in Social Media Video Posts
Paper and Code
Feb 15, 2022
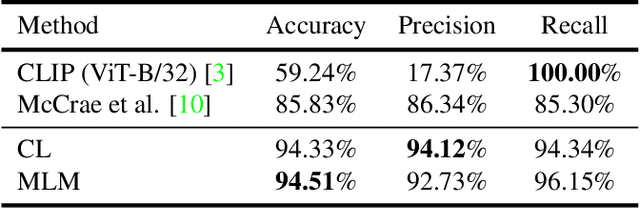
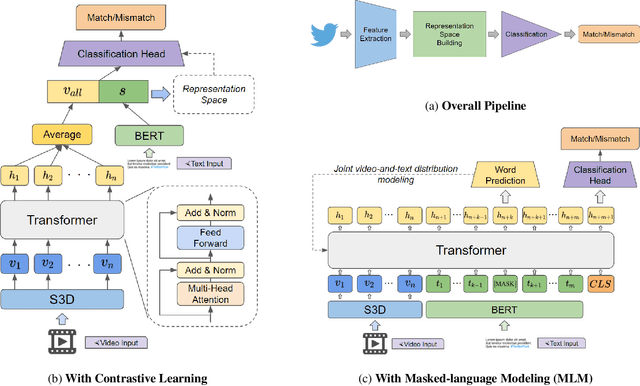
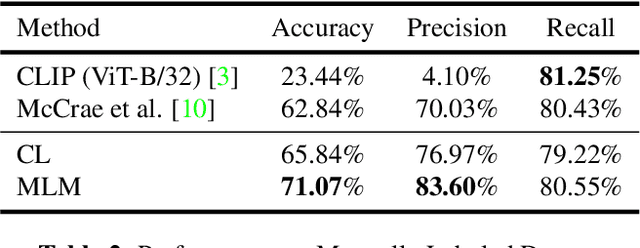
With the growing adoption of short-form video by social media platforms, reducing the spread of misinformation through video posts has become a critical challenge for social media providers. In this paper, we develop methods to detect misinformation in social media posts, exploiting modalities such as video and text. Due to the lack of large-scale public data for misinformation detection in multi-modal datasets, we collect 160,000 video posts from Twitter, and leverage self-supervised learning to learn expressive representations of joint visual and textual data. In this work, we propose two new methods for detecting semantic inconsistencies within short-form social media video posts, based on contrastive learning and masked language modeling. We demonstrate that our new approaches outperform current state-of-the-art methods on both artificial data generated by random-swapping of positive samples and in the wild on a new manually-labeled test set for semantic misinformation.