 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Semantic Inconsistency Detection in Social Media News Posts
May 26, 2021
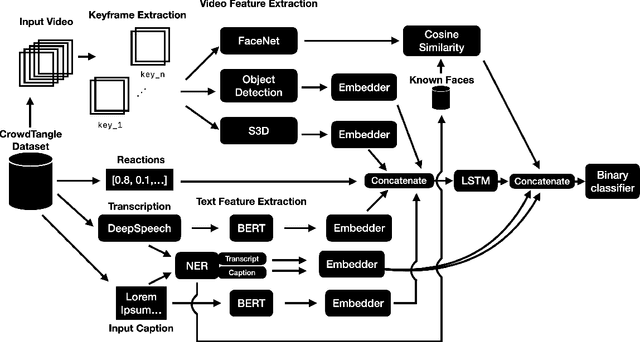
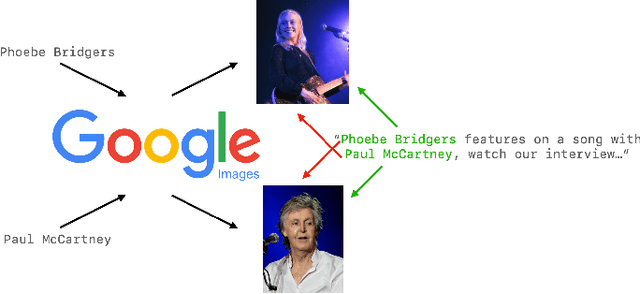

As computer-generated content and deepfakes make steady improvements, semantic approaches to multimedia forensics will become more important. In this paper, we introduce a novel classification architecture for identifying semantic inconsistencies between video appearance and text caption in social media news posts. We develop a multi-modal fusion framework to identify mismatches between videos and captions in social media posts by leveraging an ensemble method based on textual analysis of the caption, automatic audio transcription, semantic video analysis, object detection, named entity consistency, and facial verification. To train and test our approach, we curate a new video-based dataset of 4,000 real-world Facebook news posts for analysis. Our multi-modal approach achieves 60.5% classification accuracy on random mismatches between caption and appearance, compared to accuracy below 50% for uni-modal models. Further ablation studies confirm the necessity of fusion across modalities for correctly identifying semantic inconsistencies.