 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Da Vinci Code: A Comparative Study of Transformer, LLM, and PPO-based Agents
Jun 15, 2025The Da Vinci Code, a game of logical deduction and imperfect information, presents unique challenges for artificial intelligence, demanding nuanced reasoning beyond simple pattern recognition. This paper investigates the efficacy of various AI paradigms in mastering this game. We develop and evaluate three distinct agent architectures: a Transformer-based baseline model with limited historical context, several Large Language Model (LLM) agents (including Gemini, DeepSeek, and GPT variants) guided by structured prompts, and an agent based on Proximal Policy Optimization (PPO) employing a Transformer encoder for comprehensive game history processing. Performance is benchmarked against the baseline, with the PPO-based agent demonstrating superior win rates ($58.5\% \pm 1.0\%$), significantly outperforming the LLM counterparts. Our analysis highlights the strengths of deep reinforcement learning in policy refinement for complex deductive tasks, particularly in learning implicit strategies from self-play. We also examine the capabilities and inherent limitations of current LLMs in maintaining strict logical consistency and strategic depth over extended gameplay, despite sophisticated prompting. This study contributes to the broader understanding of AI in recreational games involving hidden information and multi-step logical reasoning, offering insights into effective agent design and the comparative advantages of different AI approaches.
Geometric instability of graph neural networks on large graphs
Aug 19, 2023

We analyse the geometric instability of embeddings produced by graph neural networks (GNNs). Existing methods are only applicable for small graphs and lack context in the graph domain. We propose a simple, efficient and graph-native Graph Gram Index (GGI) to measure such instability which is invariant to permutation, orthogonal transformation, translation and order of evaluation. This allows us to study the varying instability behaviour of GNN embeddings on large graphs for both node classification and link prediction.
Collaborative Navigation and Manipulation of a Cable-towed Load by Multiple Quadrupedal Robots
Jun 29, 2022
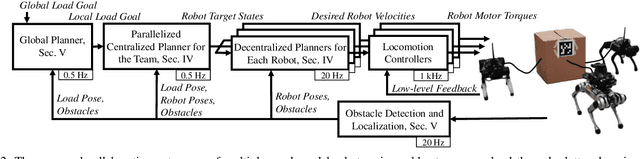
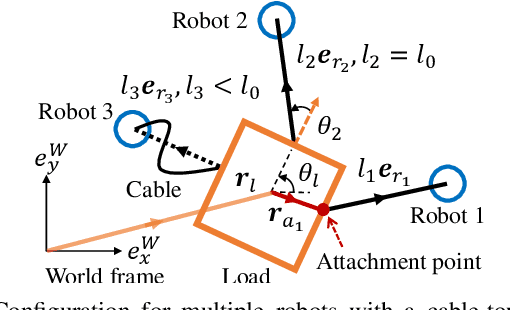
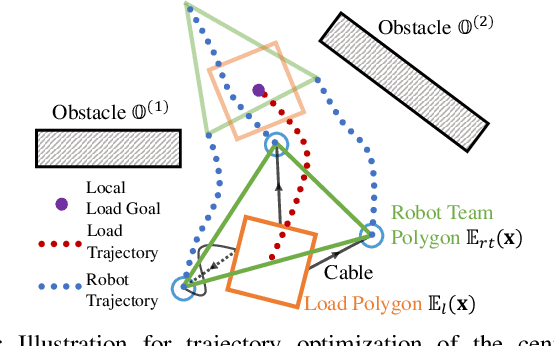
This paper tackles the problem of robots collaboratively towing a load with cables to a specified goal location while avoiding collisions in real time. The introduction of cables (as opposed to rigid links) enables the robotic team to travel through narrow spaces by changing its intrinsic dimensions through slack/taut switches of the cable. However, this is a challenging problem because of the hybrid mode switches and the dynamical coupling among multiple robots and the load. Previous attempts at addressing such a problem were performed offline and do not consider avoiding obstacles online. In this paper, we introduce a cascaded planning scheme with a parallelized centralized trajectory optimization that deals with hybrid mode switches. We additionally develop a set of decentralized planners per robot, which enables our approach to solve the problem of collaborative load manipulation online. We develop and demonstrate one of the first collaborative autonomy framework that is able to move a cable-towed load, which is too heavy to move by a single robot, through narrow spaces with real-time feedback and reactive planning in experiments.
Evolving Agents for the Hanabi 2018 CIG Competition
Sep 26, 2018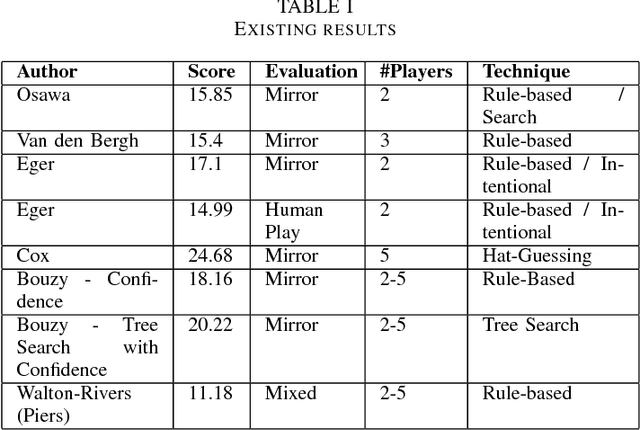
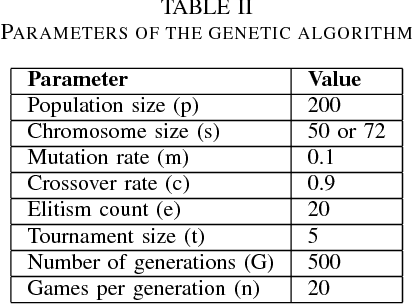

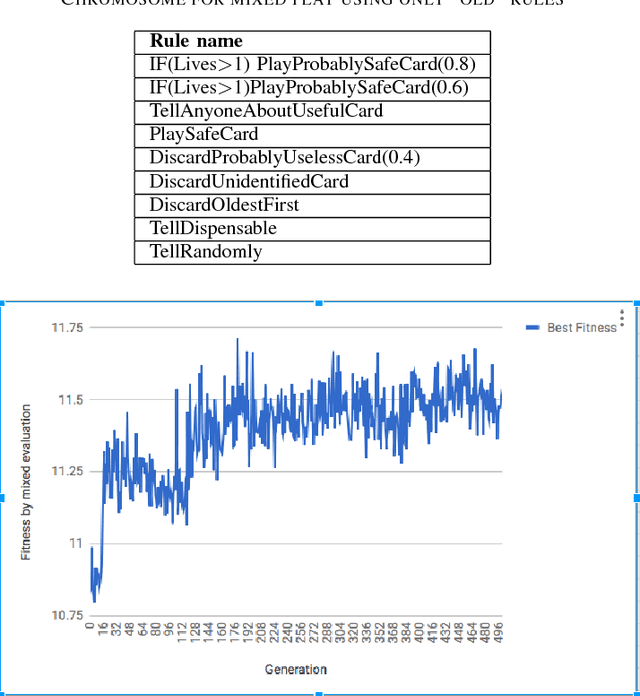
Hanabi is a cooperative card game with hidden information that has won important awards in the industry and received some recent academic attention. A two-track competition of agents for the game will take place in the 2018 CIG conference. In this paper, we develop a genetic algorithm that builds rule-based agents by determining the best sequence of rules from a fixed rule set to use as strategy. In three separate experiments, we remove human assumptions regarding the ordering of rules, add new, more expressive rules to the rule set and independently evolve agents specialized at specific game sizes. As result, we achieve scores superior to previously published research for the mirror and mixed evaluation of agents.