 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExo-Plore: Exploring Exoskeleton Control Space through Human-aligned Simulation
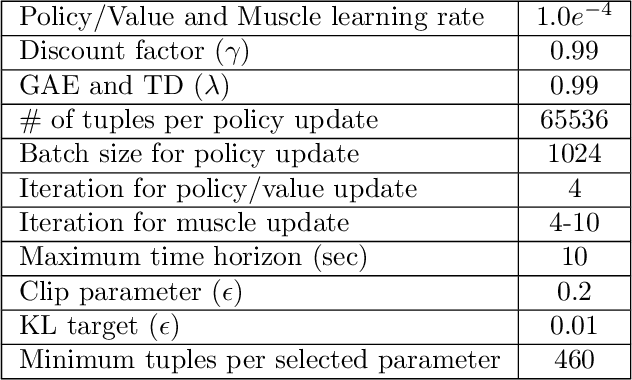
Jan 30, 2026Exoskeletons show great promise for enhancing mobility, but providing appropriate assistance remains challenging due to the complexity of human adaptation to external forces. Current state-of-the-art approaches for optimizing exoskeleton controllers require extensive human experiments in which participants must walk for hours, creating a paradox: those who could benefit most from exoskeleton assistance, such as individuals with mobility impairments, are rarely able to participate in such demanding procedures. We present Exo-plore, a simulation framework that combines neuromechanical simulation with deep reinforcement learning to optimize hip exoskeleton assistance without requiring real human experiments. Exo-plore can (1) generate realistic gait data that captures human adaptation to assistive forces, (2) produce reliable optimization results despite the stochastic nature of human gait, and (3) generalize to pathological gaits, showing strong linear relationships between pathology severity and optimal assistance.
Bidirectional GaitNet: A Bidirectional Prediction Model of Human Gait and Anatomical Conditions
Jun 07, 2023
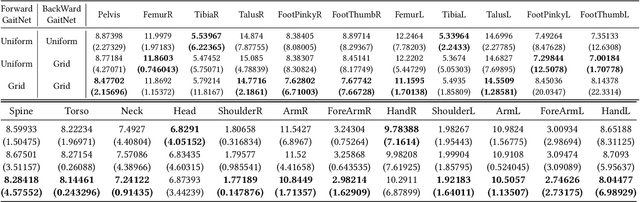
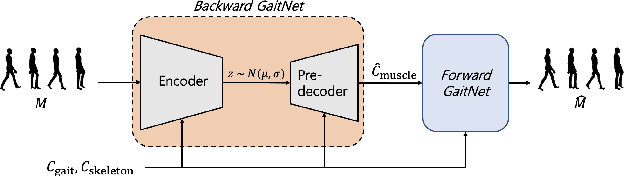
We present a novel generative model, called Bidirectional GaitNet, that learns the relationship between human anatomy and its gait. The simulation model of human anatomy is a comprehensive, full-body, simulation-ready, musculoskeletal model with 304 Hill-type musculotendon units. The Bidirectional GaitNet consists of forward and backward models. The forward model predicts a gait pattern of a person with specific physical conditions, while the backward model estimates the physical conditions of a person when his/her gait pattern is provided. Our simulation-based approach first learns the forward model by distilling the simulation data generated by a state-of-the-art predictive gait simulator and then constructs a Variational Autoencoder (VAE) with the learned forward model as its decoder. Once it is learned its encoder serves as the backward model. We demonstrate our model on a variety of healthy/impaired gaits and validate it in comparison with physical examination data of real patients.
Human Motion Control of Quadrupedal Robots using Deep Reinforcement Learning
Apr 28, 2022
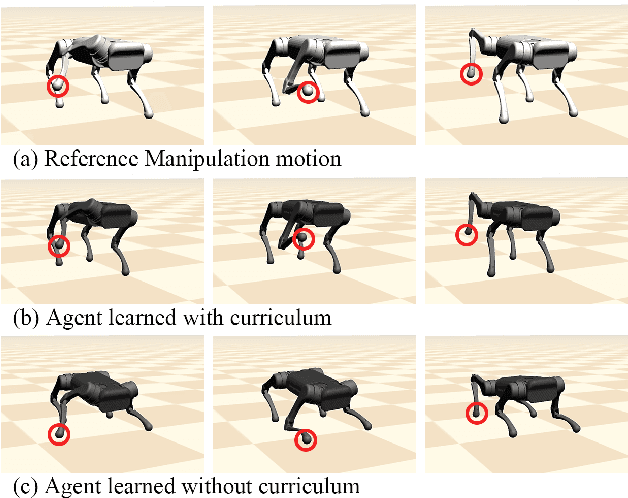


A motion-based control interface promises flexible robot operations in dangerous environments by combining user intuitions with the robot's motor capabilities. However, designing a motion interface for non-humanoid robots, such as quadrupeds or hexapods, is not straightforward because different dynamics and control strategies govern their movements. We propose a novel motion control system that allows a human user to operate various motor tasks seamlessly on a quadrupedal robot. We first retarget the captured human motion into the corresponding robot motion with proper semantics using supervised learning and post-processing techniques. Then we apply the motion imitation learning with curriculum learning to develop a control policy that can track the given retargeted reference. We further improve the performance of both motion retargeting and motion imitation by training a set of experts. As we demonstrate, a user can execute various motor tasks using our system, including standing, sitting, tilting, manipulating, walking, and turning, on simulated and real quadrupeds. We also conduct a set of studies to analyze the performance gain induced by each component.
Generative GaitNet
Jan 28, 2022
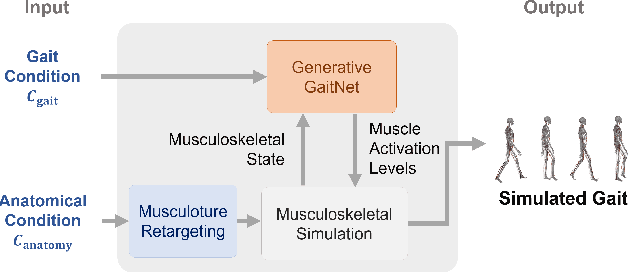
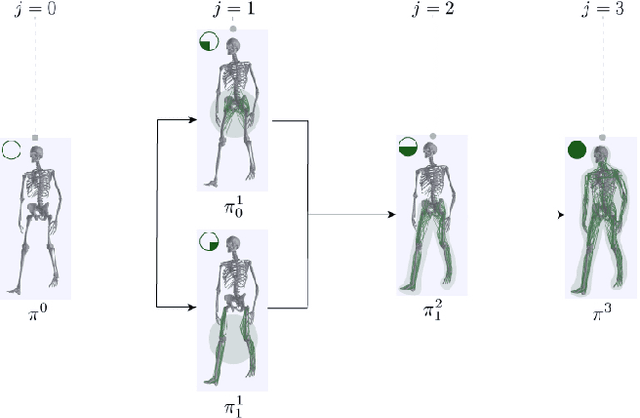
Understanding the relation between anatomy andgait is key to successful predictive gait simulation. Inthis paper, we present Generative GaitNet, which isa novel network architecture based on deep reinforce-ment learning for controlling a comprehensive, full-body, musculoskeletal model with 304 Hill-type mus-culotendons. The Generative Gait is a pre-trained, in-tegrated system of artificial neural networks learnedin a 618-dimensional continuous domain of anatomyconditions (e.g., mass distribution, body proportion,bone deformity, and muscle deficits) and gait condi-tions (e.g., stride and cadence). The pre-trained Gait-Net takes anatomy and gait conditions as input andgenerates a series of gait cycles appropriate to theconditions through physics-based simulation. We willdemonstrate the efficacy and expressive power of Gen-erative GaitNet to generate a variety of healthy andpathologic human gaits in real-time physics-based sim-ulation.
Understanding the Stability of Deep Control Policies for Biped Locomotion
Jul 30, 2020

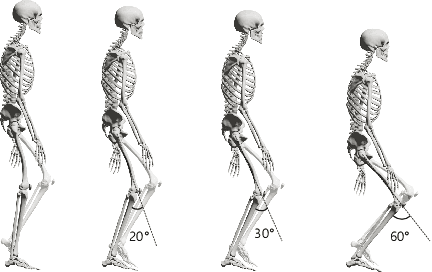
Achieving stability and robustness is the primary goal of biped locomotion control. Recently, deep reinforce learning (DRL) has attracted great attention as a general methodology for constructing biped control policies and demonstrated significant improvements over the previous state-of-the-art. Although deep control policies have advantages over previous controller design approaches, many questions remain unanswered. Are deep control policies as robust as human walking? Does simulated walking use similar strategies as human walking to maintain balance? Does a particular gait pattern similarly affect human and simulated walking? What do deep policies learn to achieve improved gait stability? The goal of this study is to answer these questions by evaluating the push-recovery stability of deep policies compared to human subjects and a previous feedback controller. We also conducted experiments to evaluate the effectiveness of variants of DRL algorithms.