 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Stability of Deep Control Policies for Biped Locomotion
Paper and Code
Jul 30, 2020

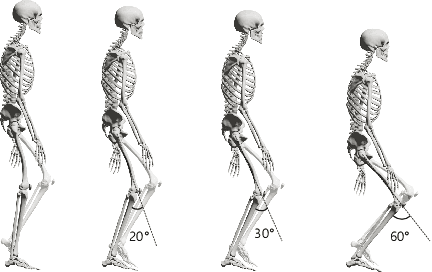
Achieving stability and robustness is the primary goal of biped locomotion control. Recently, deep reinforce learning (DRL) has attracted great attention as a general methodology for constructing biped control policies and demonstrated significant improvements over the previous state-of-the-art. Although deep control policies have advantages over previous controller design approaches, many questions remain unanswered. Are deep control policies as robust as human walking? Does simulated walking use similar strategies as human walking to maintain balance? Does a particular gait pattern similarly affect human and simulated walking? What do deep policies learn to achieve improved gait stability? The goal of this study is to answer these questions by evaluating the push-recovery stability of deep policies compared to human subjects and a previous feedback controller. We also conducted experiments to evaluate the effectiveness of variants of DRL algorithms.