 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Visual Search in the Wild
Sep 20, 2022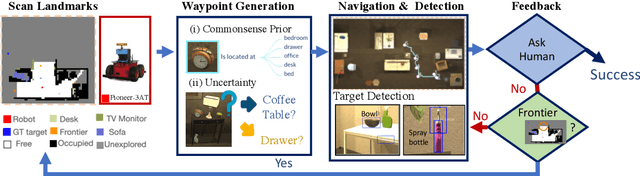
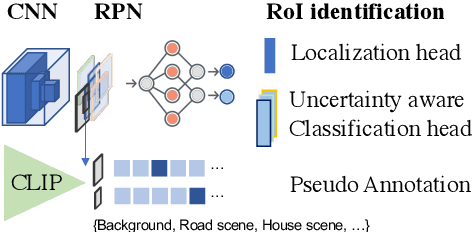

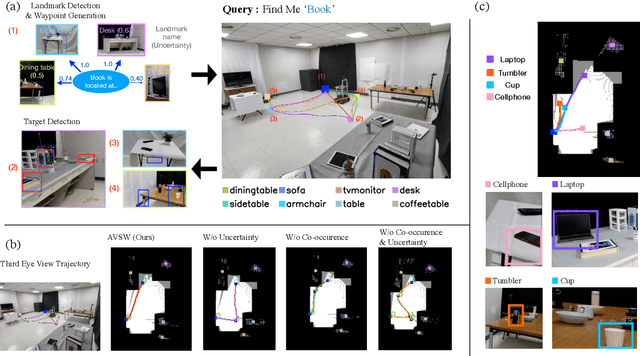
In this paper, we focus on the problem of efficiently locating a target object described with free-form language using a mobile robot equipped with vision sensors (e.g., an RGBD camera). Conventional active visual search predefines a set of objects to search for, rendering these techniques restrictive in practice. To provide added flexibility in active visual searching, we propose a system where a user can enter target commands using free-form language; we call this system Active Visual Search in the Wild (AVSW). AVSW detects and plans to search for a target object inputted by a user through a semantic grid map represented by static landmarks (e.g., desk or bed). For efficient planning of object search patterns, AVSW considers commonsense knowledge-based co-occurrence and predictive uncertainty while deciding which landmarks to visit first. We validate the proposed method with respect to SR (success rate) and SPL (success weighted by path length) in both simulated and real-world environments. The proposed method outperforms previous methods in terms of SPL in simulated scenarios with an average gap of 0.283. We further demonstrate AVSW with a Pioneer-3AT robot in real-world studies.