 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Free Cross-Task LoRA Merging with Null-Space Compression
Mar 27, 2026Model merging combines independently fine-tuned checkpoints without joint multi-task training. In the era of foundation-model, fine-tuning with Low-Rank Adaptation (LoRA) is prevalent, making LoRA merging a promising target. Existing approaches can work in homogeneous settings where all target tasks are classification but often fail when tasks span classification and regression. Approaches using entropy-based surrogates do not apply to regression and are costly for large language models due to long token sequences. We introduce Null-Space Compression (NSC) Merging, a label-free, output-agnostic method that sets merge weights from adapter geometry. Our key observation is that during LoRA finetuning the down-projection factor $A$ in $ΔW = BA$ compresses its null space, and the compression correlates with performance. NSC uses this as an optimization signal for merging that can generalize across classification, regression, and sequence generation. NSC achieves state-of-the-art performance across twenty heterogeneous vision tasks with balanced gains where prior methods overfit subsets of tasks. It also outperforms baselines on six NLI benchmarks and on vision-language evaluations for VQA and image captioning, demonstrating scalability and effectiveness.
Preference-Aligned LoRA Merging: Preserving Subspace Coverage and Addressing Directional Anisotropy
Mar 27, 2026Merging multiple Low-Rank Adaptation (LoRA) modules is promising for constructing general-purpose systems, yet challenging because LoRA update directions span different subspaces and contribute unevenly. When merged naively, such mismatches can weaken the directions most critical to certain task losses while overemphasizing relatively less important ones, ultimately reducing the model's ability to represent all tasks faithfully. We revisit this problem through two perspectives: subspace coverage, which captures how broadly LoRA directions cover diverse representational directions, and anisotropy, which reflects the imbalance of influence across those directions. We propose TARA-Merging (Task-Rank Anisotropy Alignment), which aligns merging weights using a preference-weighted cross-entropy pseudo-loss while preserving task-relevant LoRA subspaces. This ensures broad subspace coverage and mitigates anisotropy via direction-wise reweighting. Across eight vision and six NLI benchmarks, TARA-Merging consistently outperforms vanilla and LoRA-aware baselines, demonstrating strong robustness and generalization, and highlighting the importance of addressing both subspace coverage and anisotropy in LoRA merging.
Resolving Token-Space Gradient Conflicts: Token Space Manipulation for Transformer-Based Multi-Task Learning
Jul 10, 2025Multi-Task Learning (MTL) enables multiple tasks to be learned within a shared network, but differences in objectives across tasks can cause negative transfer, where the learning of one task degrades another task's performance. While pre-trained transformers significantly improve MTL performance, their fixed network capacity and rigid structure limit adaptability. Previous dynamic network architectures attempt to address this but are inefficient as they directly convert shared parameters into task-specific ones. We propose Dynamic Token Modulation and Expansion (DTME-MTL), a framework applicable to any transformer-based MTL architecture. DTME-MTL enhances adaptability and reduces overfitting by identifying gradient conflicts in token space and applying adaptive solutions based on conflict type. Unlike prior methods that mitigate negative transfer by duplicating network parameters, DTME-MTL operates entirely in token space, enabling efficient adaptation without excessive parameter growth. Extensive experiments demonstrate that DTME-MTL consistently improves multi-task performance with minimal computational overhead, offering a scalable and effective solution for enhancing transformer-based MTL models.
Synchronizing Task Behavior: Aligning Multiple Tasks during Test-Time Training
Jul 10, 2025



Generalizing neural networks to unseen target domains is a significant challenge in real-world deployments. Test-time training (TTT) addresses this by using an auxiliary self-supervised task to reduce the domain gap caused by distribution shifts between the source and target. However, we find that when models are required to perform multiple tasks under domain shifts, conventional TTT methods suffer from unsynchronized task behavior, where the adaptation steps needed for optimal performance in one task may not align with the requirements of other tasks. To address this, we propose a novel TTT approach called Synchronizing Tasks for Test-time Training (S4T), which enables the concurrent handling of multiple tasks. The core idea behind S4T is that predicting task relations across domain shifts is key to synchronizing tasks during test time. To validate our approach, we apply S4T to conventional multi-task benchmarks, integrating it with traditional TTT protocols. Our empirical results show that S4T outperforms state-of-the-art TTT methods across various benchmarks.
Selective Task Group Updates for Multi-Task Optimization
Feb 17, 2025


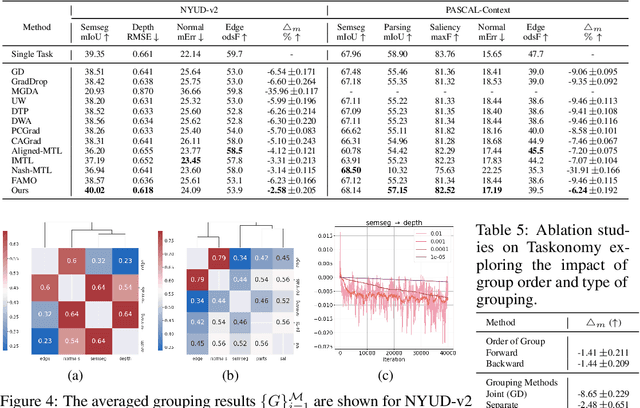
Multi-task learning enables the acquisition of task-generic knowledge by training multiple tasks within a unified architecture. However, training all tasks together in a single architecture can lead to performance degradation, known as negative transfer, which is a main concern in multi-task learning. Previous works have addressed this issue by optimizing the multi-task network through gradient manipulation or weighted loss adjustments. However, their optimization strategy focuses on addressing task imbalance in shared parameters, neglecting the learning of task-specific parameters. As a result, they show limitations in mitigating negative transfer, since the learning of shared space and task-specific information influences each other during optimization. To address this, we propose a different approach to enhance multi-task performance by selectively grouping tasks and updating them for each batch during optimization. We introduce an algorithm that adaptively determines how to effectively group tasks and update them during the learning process. To track inter-task relations and optimize multi-task networks simultaneously, we propose proximal inter-task affinity, which can be measured during the optimization process. We provide a theoretical analysis on how dividing tasks into multiple groups and updating them sequentially significantly affects multi-task performance by enhancing the learning of task-specific parameters. Our methods substantially outperform previous multi-task optimization approaches and are scalable to different architectures and various numbers of tasks.
Quantifying Task Priority for Multi-Task Optimization
Jun 05, 2024The goal of multi-task learning is to learn diverse tasks within a single unified network. As each task has its own unique objective function, conflicts emerge during training, resulting in negative transfer among them. Earlier research identified these conflicting gradients in shared parameters between tasks and attempted to realign them in the same direction. However, we prove that such optimization strategies lead to sub-optimal Pareto solutions due to their inability to accurately determine the individual contributions of each parameter across various tasks. In this paper, we propose the concept of task priority to evaluate parameter contributions across different tasks. To learn task priority, we identify the type of connections related to links between parameters influenced by task-specific losses during backpropagation. The strength of connections is gauged by the magnitude of parameters to determine task priority. Based on these, we present a new method named connection strength-based optimization for multi-task learning which consists of two phases. The first phase learns the task priority within the network, while the second phase modifies the gradients while upholding this priority. This ultimately leads to finding new Pareto optimal solutions for multiple tasks. Through extensive experiments, we show that our approach greatly enhances multi-task performance in comparison to earlier gradient manipulation methods.
Pixel-wise Deep Image Stitching
Dec 12, 2021
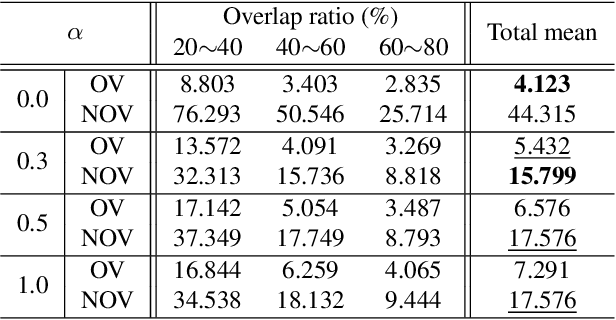
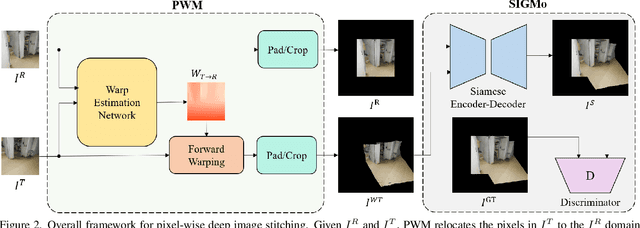
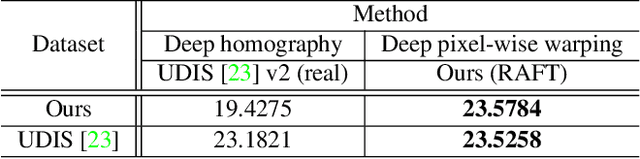
Image stitching aims at stitching the images taken from different viewpoints into an image with a wider field of view. Existing methods warp the target image to the reference image using the estimated warp function, and a homography is one of the most commonly used warping functions. However, when images have large parallax due to non-planar scenes and translational motion of a camera, the homography cannot fully describe the mapping between two images. Existing approaches based on global or local homography estimation are not free from this problem and suffer from undesired artifacts due to parallax. In this paper, instead of relying on the homography-based warp, we propose a novel deep image stitching framework exploiting the pixel-wise warp field to handle the large-parallax problem. The proposed deep image stitching framework consists of two modules: Pixel-wise Warping Module (PWM) and Stitched Image Generating Module (SIGMo). PWM employs an optical flow estimation model to obtain pixel-wise warp of the whole image, and relocates the pixels of the target image with the obtained warp field. SIGMo blends the warped target image and the reference image while eliminating unwanted artifacts such as misalignments, seams, and holes that harm the plausibility of the stitched result. For training and evaluating the proposed framework, we build a large-scale dataset that includes image pairs with corresponding pixel-wise ground truth warp and sample stitched result images. We show that the results of the proposed framework are qualitatively superior to those of the conventional methods, especially when the images have large parallax. The code and the proposed dataset will be publicly available soon.