 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrozenDrive: Zero-Shot Text-Guided Driving Scene Generation and Data Augmentation with Parameter-Free Frozen Diffusion Model
Jun 18, 2026Synthetic data for autonomous driving is surging, powered by diffusion models that promise scalable scene generation. Yet key obstacles remain, as enforcing multi-view and temporal consistency often relies on backbone fine-tuning or added layers, which erodes pre-trained knowledge and weakens text alignment. Models also stay close to the training distribution, struggling under adverse weather and unseen configurations, and fidelity favors frequent over rare classes. We address these gaps with FrozenDrive, a controllable generative framework that preserves a pretrained diffusion models knowledge while achieving strong consistency. FrozenDrive conditions on rich driving-stack signals and text prompts, and introduces knowledge-preserving spatio-temporal attention to impose cross-view alignment and temporal coherence in a single pass within a parameter-free frozen diffusion backbone. An additional object-focused constraint improves per-object fidelity for rare categories. Without any weather- or scene-specific fine-tuning, our model synthesizes globally coherent multi-view driving scenes from text, particularly under adverse and rare conditions, and surpasses prior baselines. On nuScenes, FrozenDrive augmented data significantly improves AD models performance, especially at night and in rain, demonstrating stronger robustness when trained with our scenario-targeted data.
Synchronizing Task Behavior: Aligning Multiple Tasks during Test-Time Training
Jul 10, 2025



Generalizing neural networks to unseen target domains is a significant challenge in real-world deployments. Test-time training (TTT) addresses this by using an auxiliary self-supervised task to reduce the domain gap caused by distribution shifts between the source and target. However, we find that when models are required to perform multiple tasks under domain shifts, conventional TTT methods suffer from unsynchronized task behavior, where the adaptation steps needed for optimal performance in one task may not align with the requirements of other tasks. To address this, we propose a novel TTT approach called Synchronizing Tasks for Test-time Training (S4T), which enables the concurrent handling of multiple tasks. The core idea behind S4T is that predicting task relations across domain shifts is key to synchronizing tasks during test time. To validate our approach, we apply S4T to conventional multi-task benchmarks, integrating it with traditional TTT protocols. Our empirical results show that S4T outperforms state-of-the-art TTT methods across various benchmarks.
GMT: Enhancing Generalizable Neural Rendering via Geometry-Driven Multi-Reference Texture Transfer
Oct 01, 2024Novel view synthesis (NVS) aims to generate images at arbitrary viewpoints using multi-view images, and recent insights from neural radiance fields (NeRF) have contributed to remarkable improvements. Recently, studies on generalizable NeRF (G-NeRF) have addressed the challenge of per-scene optimization in NeRFs. The construction of radiance fields on-the-fly in G-NeRF simplifies the NVS process, making it well-suited for real-world applications. Meanwhile, G-NeRF still struggles in representing fine details for a specific scene due to the absence of per-scene optimization, even with texture-rich multi-view source inputs. As a remedy, we propose a Geometry-driven Multi-reference Texture transfer network (GMT) available as a plug-and-play module designed for G-NeRF. Specifically, we propose ray-imposed deformable convolution (RayDCN), which aligns input and reference features reflecting scene geometry. Additionally, the proposed texture preserving transformer (TP-Former) aggregates multi-view source features while preserving texture information. Consequently, our module enables direct interaction between adjacent pixels during the image enhancement process, which is deficient in G-NeRF models with an independent rendering process per pixel. This addresses constraints that hinder the ability to capture high-frequency details. Experiments show that our plug-and-play module consistently improves G-NeRF models on various benchmark datasets.
SphereSR: 360° Image Super-Resolution with Arbitrary Projection via Continuous Spherical Image Representation
Dec 14, 2021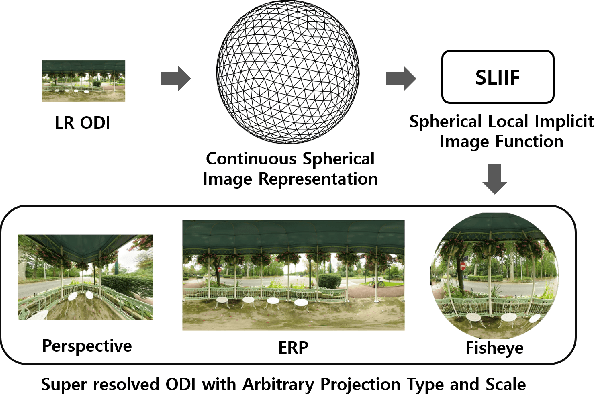
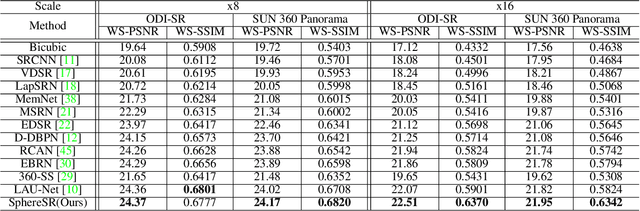
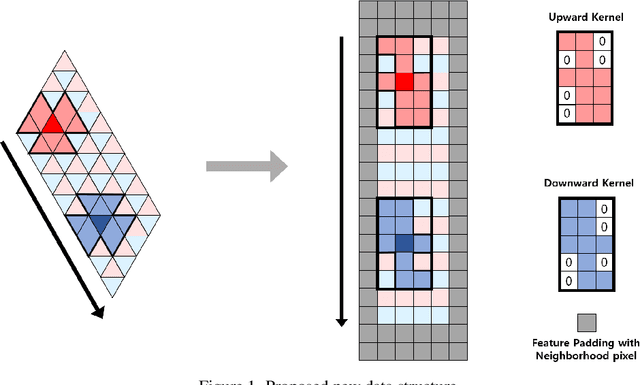
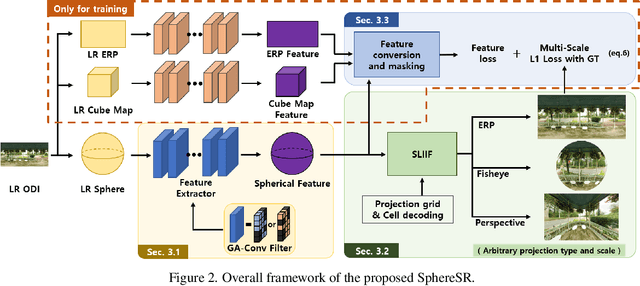
The 360{\deg}imaging has recently gained great attention; however, its angular resolution is relatively lower than that of a narrow field-of-view (FOV) perspective image as it is captured by using fisheye lenses with the same sensor size. Therefore, it is beneficial to super-resolve a 360{\deg}image. Some attempts have been made but mostly considered the equirectangular projection (ERP) as one of the way for 360{\deg}image representation despite of latitude-dependent distortions. In that case, as the output high-resolution(HR) image is always in the same ERP format as the low-resolution (LR) input, another information loss may occur when transforming the HR image to other projection types. In this paper, we propose SphereSR, a novel framework to generate a continuous spherical image representation from an LR 360{\deg}image, aiming at predicting the RGB values at given spherical coordinates for super-resolution with an arbitrary 360{\deg}image projection. Specifically, we first propose a feature extraction module that represents the spherical data based on icosahedron and efficiently extracts features on the spherical surface. We then propose a spherical local implicit image function (SLIIF) to predict RGB values at the spherical coordinates. As such, SphereSR flexibly reconstructs an HR image under an arbitrary projection type. Experiments on various benchmark datasets show that our method significantly surpasses existing methods.
Pixel-wise Deep Image Stitching
Dec 12, 2021
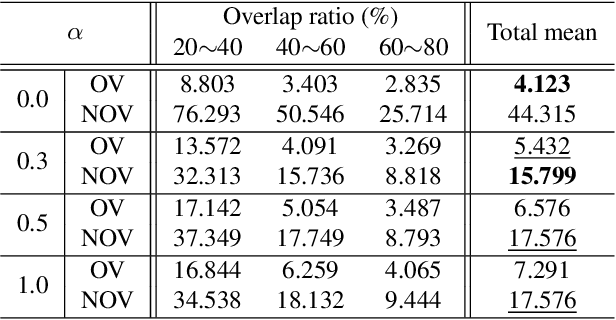
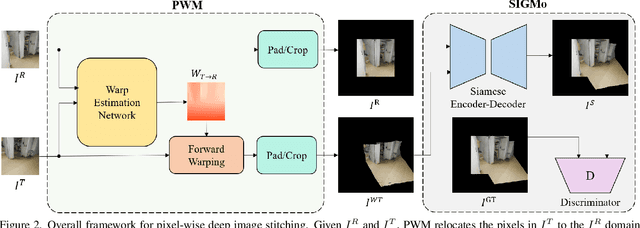
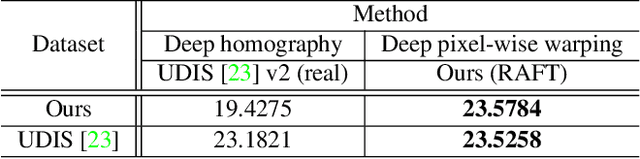
Image stitching aims at stitching the images taken from different viewpoints into an image with a wider field of view. Existing methods warp the target image to the reference image using the estimated warp function, and a homography is one of the most commonly used warping functions. However, when images have large parallax due to non-planar scenes and translational motion of a camera, the homography cannot fully describe the mapping between two images. Existing approaches based on global or local homography estimation are not free from this problem and suffer from undesired artifacts due to parallax. In this paper, instead of relying on the homography-based warp, we propose a novel deep image stitching framework exploiting the pixel-wise warp field to handle the large-parallax problem. The proposed deep image stitching framework consists of two modules: Pixel-wise Warping Module (PWM) and Stitched Image Generating Module (SIGMo). PWM employs an optical flow estimation model to obtain pixel-wise warp of the whole image, and relocates the pixels of the target image with the obtained warp field. SIGMo blends the warped target image and the reference image while eliminating unwanted artifacts such as misalignments, seams, and holes that harm the plausibility of the stitched result. For training and evaluating the proposed framework, we build a large-scale dataset that includes image pairs with corresponding pixel-wise ground truth warp and sample stitched result images. We show that the results of the proposed framework are qualitatively superior to those of the conventional methods, especially when the images have large parallax. The code and the proposed dataset will be publicly available soon.