 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Gated Recurrent Fusion for Semantic Scene Completion
Paper and Code
Feb 17, 2020
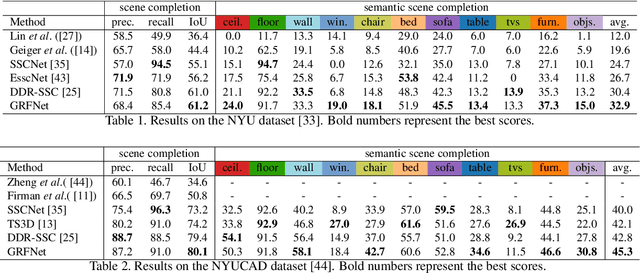


This paper tackles the problem of data fusion in the semantic scene completion (SSC) task, which can simultaneously deal with semantic labeling and scene completion. RGB images contain texture details of the object(s) which are vital for semantic scene understanding. Meanwhile, depth images capture geometric clues of high relevance for shape completion. Using both RGB and depth images can further boost the accuracy of SSC over employing one modality in isolation. We propose a 3D gated recurrent fusion network (GRFNet), which learns to adaptively select and fuse the relevant information from depth and RGB by making use of the gate and memory modules. Based on the single-stage fusion, we further propose a multi-stage fusion strategy, which could model the correlations among different stages within the network. Extensive experiments on two benchmark datasets demonstrate the superior performance and the effectiveness of the proposed GRFNet for data fusion in SSC. Code will be made available.