 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-RCNet: Learning from Transformer to Build a 3D Relational ConvNet for Hyperspectral Image Classification
Aug 25, 2024Recently, the Vision Transformer (ViT) model has replaced the classical Convolutional Neural Network (ConvNet) in various computer vision tasks due to its superior performance. Even in hyperspectral image (HSI) classification field, ViT-based methods also show promising potential. Nevertheless, ViT encounters notable difficulties in processing HSI data. Its self-attention mechanism, which exhibits quadratic complexity, escalates computational costs. Additionally, ViT's substantial demand for training samples does not align with the practical constraints posed by the expensive labeling of HSI data. To overcome these challenges, we propose a 3D relational ConvNet named 3D-RCNet, which inherits both strengths of ConvNet and ViT, resulting in high performance in HSI classification. We embed the self-attention mechanism of Transformer into the convolutional operation of ConvNet to design 3D relational convolutional operation and use it to build the final 3D-RCNet. The proposed 3D-RCNet maintains the high computational efficiency of ConvNet while enjoying the flexibility of ViT. Additionally, the proposed 3D relational convolutional operation is a plug-and-play operation, which can be inserted into previous ConvNet-based HSI classification methods seamlessly. Empirical evaluations on three representative benchmark HSI datasets show that the proposed model outperforms previous ConvNet-based and ViT-based HSI approaches.
Bridging Sensor Gaps via Single-Direction Tuning for Hyperspectral Image Classification
Sep 22, 2023

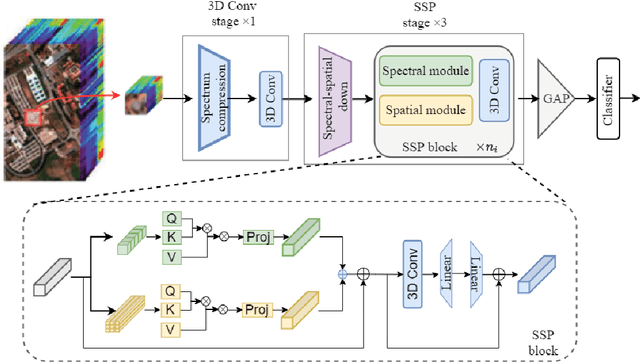

Recently, some researchers started exploring the use of ViTs in tackling HSI classification and achieved remarkable results. However, the training of ViT models requires a considerable number of training samples, while hyperspectral data, due to its high annotation costs, typically has a relatively small number of training samples. This contradiction has not been effectively addressed. In this paper, aiming to solve this problem, we propose the single-direction tuning (SDT) strategy, which serves as a bridge, allowing us to leverage existing labeled HSI datasets even RGB datasets to enhance the performance on new HSI datasets with limited samples. The proposed SDT inherits the idea of prompt tuning, aiming to reuse pre-trained models with minimal modifications for adaptation to new tasks. But unlike prompt tuning, SDT is custom-designed to accommodate the characteristics of HSIs. The proposed SDT utilizes a parallel architecture, an asynchronous cold-hot gradient update strategy, and unidirectional interaction. It aims to fully harness the potent representation learning capabilities derived from training on heterologous, even cross-modal datasets. In addition, we also introduce a novel Triplet-structured transformer (Tri-Former), where spectral attention and spatial attention modules are merged in parallel to construct the token mixing component for reducing computation cost and a 3D convolution-based channel mixer module is integrated to enhance stability and keep structure information. Comparison experiments conducted on three representative HSI datasets captured by different sensors demonstrate the proposed Tri-Former achieves better performance compared to several state-of-the-art methods. Homologous, heterologous and cross-modal tuning experiments verified the effectiveness of the proposed SDT.