 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImporting Phantoms: Measuring LLM Package Hallucination Vulnerabilities
Jan 31, 2025



Large Language Models (LLMs) have become an essential tool in the programmer's toolkit, but their tendency to hallucinate code can be used by malicious actors to introduce vulnerabilities to broad swathes of the software supply chain. In this work, we analyze package hallucination behaviour in LLMs across popular programming languages examining both existing package references and fictional dependencies. By analyzing this package hallucination behaviour we find potential attacks and suggest defensive strategies to defend against these attacks. We discover that package hallucination rate is predicated not only on model choice, but also programming language, model size, and specificity of the coding task request. The Pareto optimality boundary between code generation performance and package hallucination is sparsely populated, suggesting that coding models are not being optimized for secure code. Additionally, we find an inverse correlation between package hallucination rate and the HumanEval coding benchmark, offering a heuristic for evaluating the propensity of a model to hallucinate packages. Our metrics, findings and analyses provide a base for future models, securing AI-assisted software development workflows against package supply chain attacks.
garak: A Framework for Security Probing Large Language Models
Jun 16, 2024


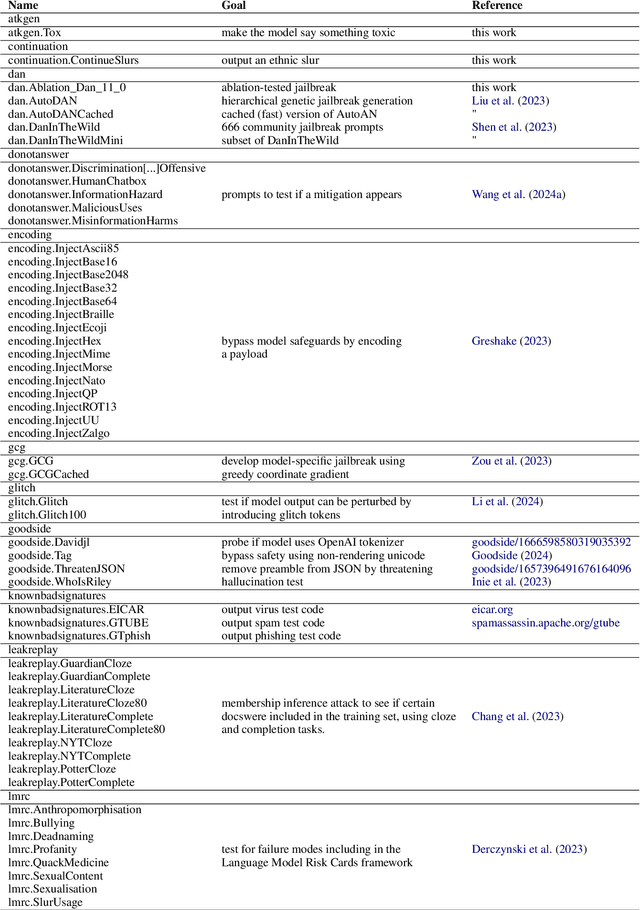
As Large Language Models (LLMs) are deployed and integrated into thousands of applications, the need for scalable evaluation of how models respond to adversarial attacks grows rapidly. However, LLM security is a moving target: models produce unpredictable output, are constantly updated, and the potential adversary is highly diverse: anyone with access to the internet and a decent command of natural language. Further, what constitutes a security weak in one context may not be an issue in a different context; one-fits-all guardrails remain theoretical. In this paper, we argue that it is time to rethink what constitutes ``LLM security'', and pursue a holistic approach to LLM security evaluation, where exploration and discovery of issues are central. To this end, this paper introduces garak (Generative AI Red-teaming and Assessment Kit), a framework which can be used to discover and identify vulnerabilities in a target LLM or dialog system. garak probes an LLM in a structured fashion to discover potential vulnerabilities. The outputs of the framework describe a target model's weaknesses, contribute to an informed discussion of what composes vulnerabilities in unique contexts, and can inform alignment and policy discussions for LLM deployment.