 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Vision-Language Models and their Performance on the Hateful Memes Challenge
May 09, 2023
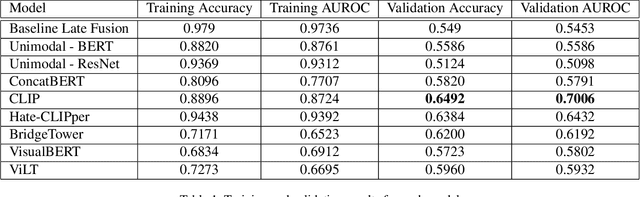
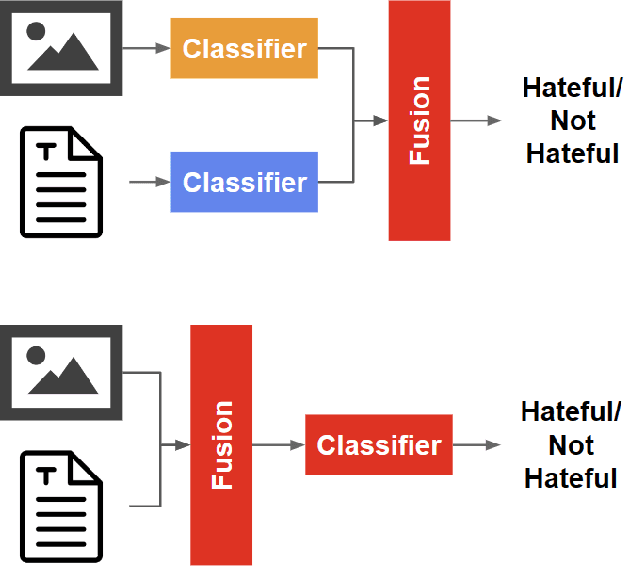
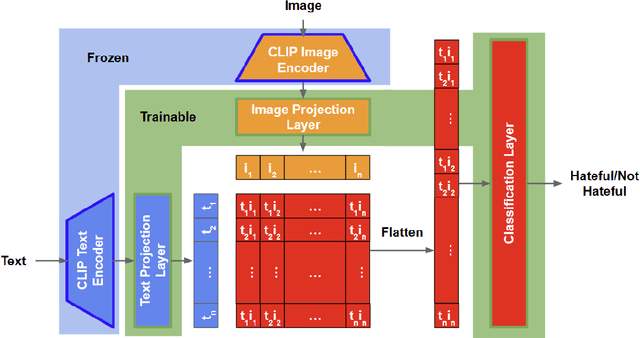
Moderation of social media content is currently a highly manual task, yet there is too much content posted daily to do so effectively. With the advent of a number of multimodal models, there is the potential to reduce the amount of manual labor for this task. In this work, we aim to explore different models and determine what is most effective for the Hateful Memes Challenge, a challenge by Meta designed to further machine learning research in content moderation. Specifically, we explore the differences between early fusion and late fusion models in classifying multimodal memes containing text and images. We first implement a baseline using unimodal models for text and images separately using BERT and ResNet-152, respectively. The outputs from these unimodal models were then concatenated together to create a late fusion model. In terms of early fusion models, we implement ConcatBERT, VisualBERT, ViLT, CLIP, and BridgeTower. It was found that late fusion performed significantly worse than early fusion models, with the best performing model being CLIP which achieved an AUROC of 70.06. The code for this work is available at https://github.com/bzhao18/CS-7643-Project.