 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderdetermined Blind Source Separation via Weighted Simplex Shrinkage Regularization and Quantum Deep Image Prior
Mar 26, 2026As most optical satellites remotely acquire multispectral images (MSIs) with limited spatial resolution, multispectral unmixing (MU) becomes a critical signal processing technology for analyzing the pure material spectra for high-precision classification and identification. Unlike the widely investigated hyperspectral unmixing (HU) problem, MU is much more challenging as it corresponds to the underdetermined blind source separation (BSS) problem, where the number of sources is larger than the number of available multispectral bands. In this article, we transform MU into its overdetermined counterpart (i.e., HU) by inventing a radically new quantum deep image prior (QDIP), which relies on the virtual band-splitting task conducted on the observed MSI for generating the virtual hyperspectral image (HSI). Then, we perform HU on the virtual HSI to obtain the virtual hyperspectral sources. Though HU is overdetermined, it still suffers from the ill-posed issue, for which we employ the convex geometry structure of the HSI pixels to customize a weighted simplex shrinkage (WSS) regularizer to mitigate the ill-posedness. Finally, the virtual hyperspectral sources are spectrally downsampled to obtain the desired multispectral sources. The proposed geometry/quantum-empowered MU (GQ-$μ$) algorithm can also effectively obtain the spatial abundance distribution map for each source, where the geometric WSS regularization is adaptively and automatically controlled based on the sparsity pattern of the abundance tensor. Simulation and real-world data experiments demonstrate the practicality of our unsupervised GQ-$μ$ algorithm for the challenging MU task. Ablation study demonstrates the strength of QDIP, not achieved by classical DIP, and validates the mechanics-inspired WSS geometry regularizer.
* Published in: IEEE Transactions on Image Processing ( Volume: 35)
Spectral Super-Resolution via Adversarial Unfolding and Data-Driven Spectrum Regularization: From Multispectral Satellite Data to NASA Hyperspectral Image
Mar 01, 2026The European Space Agency's Sentinel-2 satellite provides global multispectral coverage for remote sensing (RS) applications. However, limited spectral resolution (12 bands) and non-unified spatial resolution (60/20/10 m) restrict their practicality. In contrast, the high spectral-spatial resolution sensor (e.g., NASA's AVIRIS-NG) covers only the American region due to practical considerations. This raises a fundamental question: ``Can a global hyperspectral coverage be achieved by reconstructing Sentinel-2 data to NASA hyperspectral images?'' This study aims to achieve spectral super-resolution from 12-to-186 and unify the spatial resolution of Sentinel-2 data to 5 m. To enable a reliable and efficient reconstruction, we formulate a novel deep unfolding framework regularized by a data-driven spectrum prior from PriorNet, instead of relying on implicit deep priors as conventional deep unfolding does. Moreover, an adversarial term is integrated into the unfolded architecture, enabling the discriminator to guide the reconstruction in both the training and testing phases; we term this novel concept unfolding adversarial learning (UAL). Experiments show that our UALNet outperforms the next-best Transformer in PSNR, SSIM, and SAM, while requiring only 15% MACs and 20 times fewer parameters. The associated code will be publicly available at https://sites.google.com/view/chiahsianglin/software.
Deep Unfolding Real-Time Super-Resolution Using Subpixel-Shift Twin Image and Convex Self-Similarity Prior
Feb 25, 2026Multi-image super-resolution (MISR) is a critical technique for satellite remote sensing. In the perspective of information, twin-image super-resolution (TISR) is regarded as the most challenging MISR scenario, having crucial applications like the SPOT-5 supermode imaging. In TISR, an image is super-resolved by its subpixel-shift counterpart (i.e., twin image), where the two images are typically offset by half a pixel both horizontally and vertically. We formulate the less investigated TISR using a convex criterion, which is implemented using a novel deep unfolding network. In the unfolding, an embedded simple shift operator trickily addresses the coupled TISR data-fitting terms, and a transformer trained with a convex self-similarity loss function elegantly implements the proximal mapping induced by the TISR regularizer. The proposed convex self-similarity unfolding supermode super-resolution (COSUP) algorithm is interpretable and achieves state-of-the-art performance with very fast millisecond-level computational time. COSUP is also tested on real-world data, for which the subpixel shifts would not be spatially uniform, with results showing great superiority over the official CNES supermode imaging product in terms of credible metrics (e.g., natural image quality evaluator, NIQE). Source codes: https://github.com/IHCLab/COSUP.
COS2A: Conversion from Sentinel-2 to AVIRIS Hyperspectral Data Using Interpretable Algorithm With Spectral-Spatial Duality
Jul 09, 2025



The Sentinel-2 satellite, launched by the European Space Agency (ESA), offers extensive spatial coverage and has become indispensable in a wide range of remote sensing applications. However, it just has 12 spectral bands, making substances/objects identification less effective, not mentioning the varying spatial resolutions (10/20/60 m) across the 12 bands. If such a multi-resolution 12-band image can be computationally converted into a hyperspectral image with uniformly high resolution (i.e., 10 m), it significantly facilitates remote identification tasks. Though there are some spectral super-resolution methods, they did not address the multi-resolution issue on one hand, and, more seriously, they mostly focused on the CAVE-level hyperspectral image reconstruction (involving only 31 visible bands) on the other hand, greatly limiting their applicability in real-world remote sensing scenarios. We ambitiously aim to convert Sentinel-2 data directly into NASA's AVIRIS-level hyperspectral image (encompassing up to 172 visible and near-infrared (NIR) bands, after ignoring those absorption/corruption ones). For the first time, this paper solves this specific super-resolution problem (highly ill-posed), allowing all historical Sentinel-2 data to have their corresponding high-standard AVIRIS counterparts. We achieve so by customizing a novel algorithm that introduces deep unfolding regularization and Q-quadratic-norm regularization into the so-called convex/deep (CODE) small-data learning criterion. Based on the derived spectral-spatial duality, the proposed interpretable COS2A algorithm demonstrates superior spectral super-resolution results across diverse land cover types, as validated through extensive experiments.
Quantum-Driven Multihead Inland Waterbody Detection With Transformer-Encoded CYGNSS Delay-Doppler Map Data
May 22, 2025
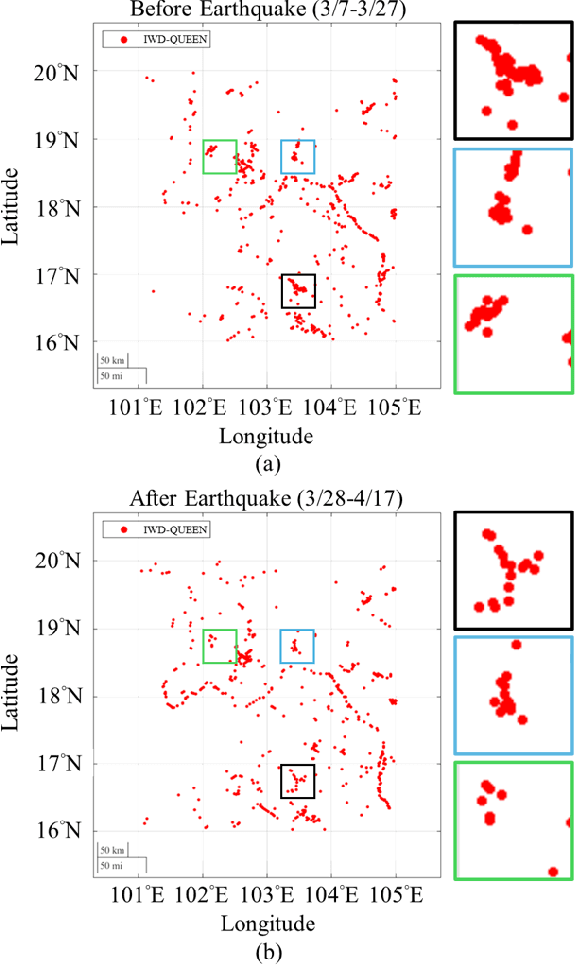
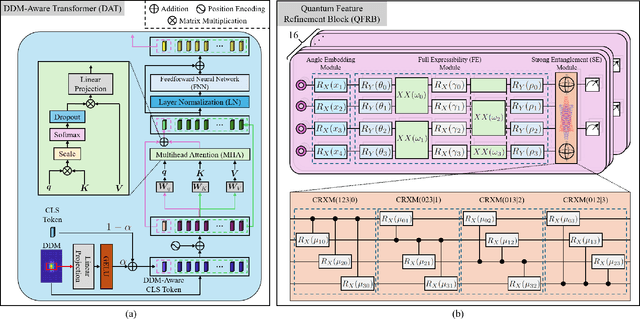
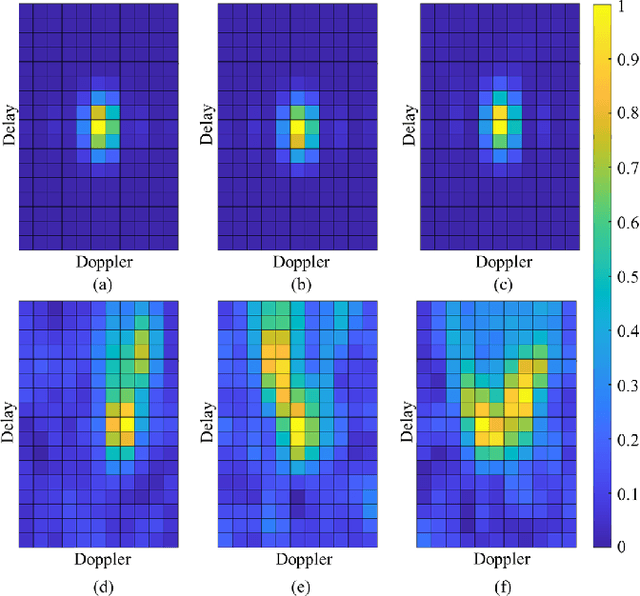
Inland waterbody detection (IWD) is critical for water resources management and agricultural planning. However, the development of high-fidelity IWD mapping technology remains unresolved. We aim to propose a practical solution based on the easily accessible data, i.e., the delay-Doppler map (DDM) provided by NASA's Cyclone Global Navigation Satellite System (CYGNSS), which facilitates effective estimation of physical parameters on the Earth's surface with high temporal resolution and wide spatial coverage. Specifically, as quantum deep network (QUEEN) has revealed its strong proficiency in addressing classification-like tasks, we encode the DDM using a customized transformer, followed by feeding the transformer-encoded DDM (tDDM) into a highly entangled QUEEN to distinguish whether the tDDM corresponds to a hydrological region. In recent literature, QUEEN has achieved outstanding performances in numerous challenging remote sensing tasks (e.g., hyperspectral restoration, change detection, and mixed noise removal, etc.), and its high effectiveness stems from the fundamentally different way it adopts to extract features (the so-called quantum unitary-computing features). The meticulously designed IWD-QUEEN retrieves high-precision river textures, such as those in Amazon River Basin in South America, demonstrating its superiority over traditional classification methods and existing global hydrography maps. IWD-QUEEN, together with its parallel quantum multihead scheme, works in a near-real-time manner (i.e., millisecond-level computing per DDM). To broaden accessibility for users of traditional computers, we also provide the non-quantum counterpart of our method, called IWD-Transformer, thereby increasing the impact of this work.
HyperKING: Quantum-Classical Generative Adversarial Networks for Hyperspectral Image Restoration
Apr 16, 2025



Quantum machine intelligence starts showing its impact on satellite remote sensing (SRS). Also, recent literature exhibits that quantum generative intelligences encompass superior potential than their classical counterpart, motivating us to develop quantum generative adversarial networks (GANs) for SRS. However, existing quantum GANs are restricted by the limited quantum bit (qubit) resources of current quantum computers and process merely a small 2x2 grayscale image, far from being applicable to SRS. Recently, the novel concept of hybrid quantum-classical GAN, a quantum generator with a classical discriminator, has upgraded the order to 28x28 (still grayscale), whereas it is still insufficient for SRS. This motivates us to design a radically new hybrid framework, where both generator and discriminator are hybrid architectures. We demonstrate this feasibility, leading to a breakthrough of processing 128x128 hyperspectral images for SRS. Specifically, we design the quantum part with mathematically provable quantum full expressibility (FE) to address core signal processing tasks, wherein the FE property allows the quantum network to realize any valid quantum operator with appropriate training. The classical part, composed of convolutional layers, treats the read-in (compressing the optical information into limited qubits) and read-out (addressing the quantum collapse effect) procedures. The proposed innovative hybrid quantum GAN, named Hyperspectral Knot-like IntelligeNt dIscrimiNator and Generator (HyperKING), where knot partly symbolizes the quantum entanglement and partly the compressed quantum domain in the central part of the network architecture. HyperKING significantly surpasses the classical approaches in hyperspectral tensor completion, mixed noise removal (about 3dB improvement), and blind source separation results.
A Quantum-Empowered SPEI Drought Forecasting Algorithm Using Spatially-Aware Mamba Network
Feb 28, 2025

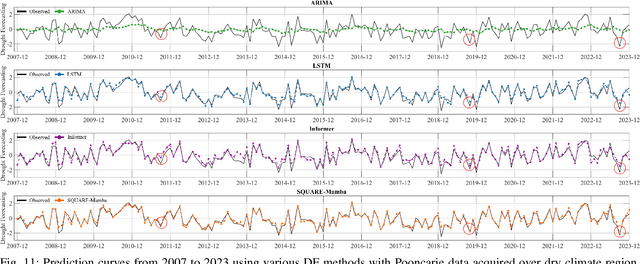

Due to the intensifying impacts of extreme climate changes, drought forecasting (DF), which aims to predict droughts from historical meteorological data, has become increasingly critical for monitoring and managing water resources. Though drought conditions often exhibit spatial climatic coherence among neighboring regions, benchmark deep learning-based DF methods overlook this fact and predict the conditions on a region-by-region basis. Using the Standardized Precipitation Evapotranspiration Index (SPEI), we designed and trained a novel and transformative spatially-aware DF neural network, which effectively captures local interactions among neighboring regions, resulting in enhanced spatial coherence and prediction accuracy. As DF also requires sophisticated temporal analysis, the Mamba network, recognized as the most accurate and efficient existing time-sequence modeling, was adopted to extract temporal features from short-term time frames. We also adopted quantum neural networks (QNN) to entangle the spatial features of different time instances, leading to refined spatiotemporal features of seven different meteorological variables for effectively identifying short-term climate fluctuations. In the last stage of our proposed SPEI-driven quantum spatially-aware Mamba network (SQUARE-Mamba), the extracted spatiotemporal features of seven different meteorological variables were fused to achieve more accurate DF. Validation experiments across El Ni\~no, La Ni\~na, and normal years demonstrated the superiority of the proposed SQUARE-Mamba, remarkably achieving an average improvement of more than 9.8% in the coefficient of determination index (R^2) compared to baseline methods, thereby illustrating the promising roles of the temporal quantum entanglement and Mamba temporal analysis to achieve more accurate DF.
Quantum Feature-Empowered Deep Classification for Fast Mangrove Mapping
Jan 06, 2025



A mangrove mapping (MM) algorithm is an essential classification tool for environmental monitoring. The recent literature shows that compared with other index-based MM methods that treat pixels as spatially independent, convolutional neural networks (CNNs) are crucial for leveraging spatial continuity information, leading to improved classification performance. In this work, we go a step further to show that quantum features provide radically new information for CNN to further upgrade the classification results. Simply speaking, CNN computes affine-mapping features, while quantum neural network (QNN) offers unitary-computing features, thereby offering a fresh perspective in the final decision-making (classification). To address the challenging MM problem, we design an entangled spatial-spectral quantum feature extraction module. Notably, to ensure that the quantum features contribute genuinely novel information (unaffected by traditional CNN features), we design a separate network track consisting solely of quantum neurons with built-in interpretability. The extracted pure quantum information is then fused with traditional feature information to jointly make the final decision. The proposed quantum-empowered deep network (QEDNet) is very lightweight, so the improvement does come from the cooperation between CNN and QNN (rather than parameter augmentation). Extensive experiments will be conducted to demonstrate the superiority of QEDNet.
Transformer-Driven Inverse Problem Transform for Fast Blind Hyperspectral Image Dehazing
Jan 03, 2025



Hyperspectral dehazing (HyDHZ) has become a crucial signal processing technology to facilitate the subsequent identification and classification tasks, as the airborne visible/infrared imaging spectrometer (AVIRIS) data portal reports a massive portion of haze-corrupted areas in typical hyperspectral remote sensing images. The idea of inverse problem transform (IPT) has been proposed in recent remote sensing literature in order to reformulate a hardly tractable inverse problem (e.g., HyDHZ) into a relatively simple one. Considering the emerging spectral super-resolution (SSR) technique, which spectrally upsamples multispectral data to hyperspectral data, we aim to solve the challenging HyDHZ problem by reformulating it as an SSR problem. Roughly speaking, the proposed algorithm first automatically selects some uncorrupted/informative spectral bands, from which SSR is applied to spectrally upsample the selected bands in the feature space, thereby obtaining a clean hyperspectral image (HSI). The clean HSI is then further refined by a deep transformer network to obtain the final dehazed HSI, where a global attention mechanism is designed to capture nonlocal information. There are very few HyDHZ works in existing literature, and this article introduces the powerful spatial-spectral transformer into HyDHZ for the first time. Remarkably, the proposed transformer-driven IPT-based HyDHZ (T2HyDHZ) is a blind algorithm without requiring the user to manually select the corrupted region. Extensive experiments demonstrate the superiority of T2HyDHZ with less color distortion.
Quantum Information-Empowered Graph Neural Network for Hyperspectral Change Detection
Nov 12, 2024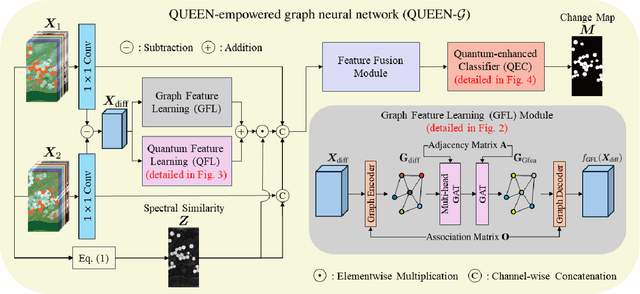

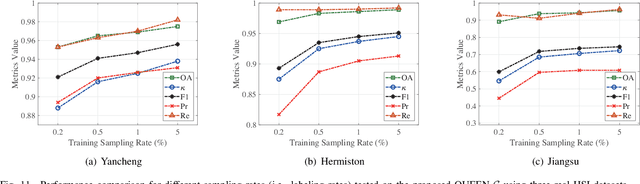
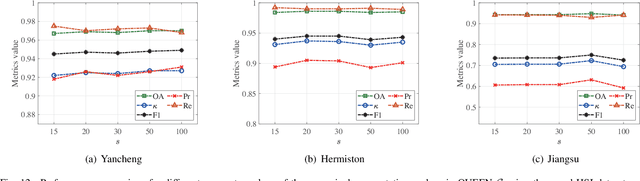
Change detection (CD) is a critical remote sensing technique for identifying changes in the Earth's surface over time. The outstanding substance identifiability of hyperspectral images (HSIs) has significantly enhanced the detection accuracy, making hyperspectral change detection (HCD) an essential technology. The detection accuracy can be further upgraded by leveraging the graph structure of HSIs, motivating us to adopt the graph neural networks (GNNs) in solving HCD. For the first time, this work introduces quantum deep network (QUEEN) into HCD. Unlike GNN and CNN, both extracting the affine-computing features, QUEEN provides fundamentally different unitary-computing features. We demonstrate that through the unitary feature extraction procedure, QUEEN provides radically new information for deciding whether there is a change or not. Hierarchically, a graph feature learning (GFL) module exploits the graph structure of the bitemporal HSIs at the superpixel level, while a quantum feature learning (QFL) module learns the quantum features at the pixel level, as a complementary to GFL by preserving pixel-level detailed spatial information not retained in the superpixels. In the final classification stage, a quantum classifier is designed to cooperate with a traditional fully connected classifier. The superior HCD performance of the proposed QUEEN-empowered GNN (i.e., QUEEN-G) will be experimentally demonstrated on real hyperspectral datasets.