 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Bandwidth Recovery of Optical Coherence Tomography Images using Deep Learning
Jan 02, 2023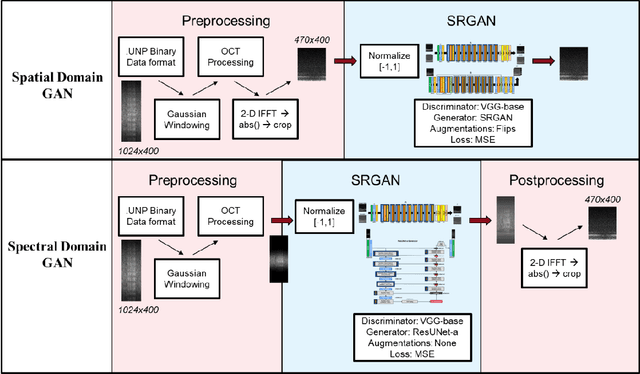

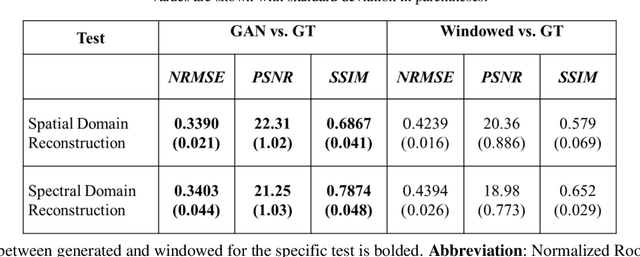
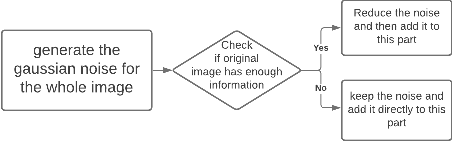
Optical coherence tomography (OCT) captures cross-sectional data and is used for the screening, monitoring, and treatment planning of retinal diseases. Technological developments to increase the speed of acquisition often results in systems with a narrower spectral bandwidth, and hence a lower axial resolution. Traditionally, image-processing-based techniques have been utilized to reconstruct subsampled OCT data and more recently, deep-learning-based methods have been explored. In this study, we simulate reduced axial scan (A-scan) resolution by Gaussian windowing in the spectral domain and investigate the use of a learning-based approach for image feature reconstruction. In anticipation of the reduced resolution that accompanies wide-field OCT systems, we build upon super-resolution techniques to explore methods to better aid clinicians in their decision-making to improve patient outcomes, by reconstructing lost features using a pixel-to-pixel approach with an altered super-resolution generative adversarial network (SRGAN) architecture.
Segmentation-guided Domain Adaptation and Data Harmonization of Multi-device Retinal Optical Coherence Tomography using Cycle-Consistent Generative Adversarial Networks
Aug 31, 2022
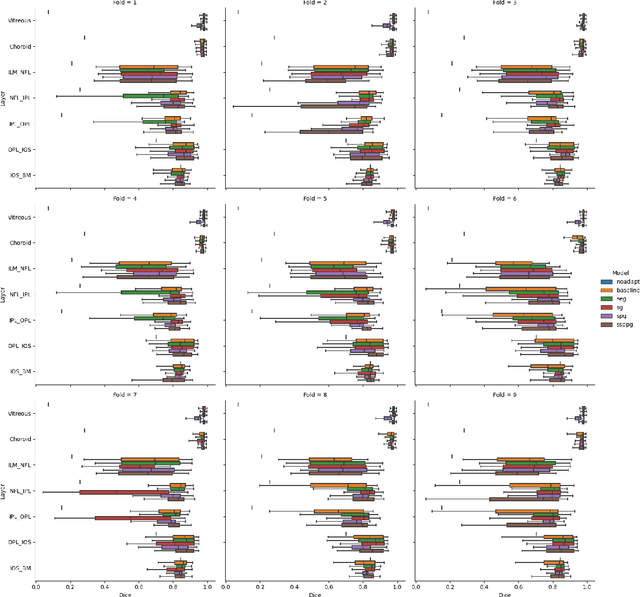
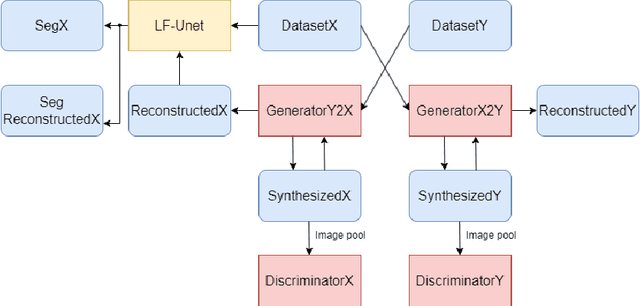
Optical Coherence Tomography(OCT) is a non-invasive technique capturing cross-sectional area of the retina in micro-meter resolutions. It has been widely used as a auxiliary imaging reference to detect eye-related pathology and predict longitudinal progression of the disease characteristics. Retina layer segmentation is one of the crucial feature extraction techniques, where the variations of retinal layer thicknesses and the retinal layer deformation due to the presence of the fluid are highly correlated with multiple epidemic eye diseases like Diabetic Retinopathy(DR) and Age-related Macular Degeneration (AMD). However, these images are acquired from different devices, which have different intensity distribution, or in other words, belong to different imaging domains. This paper proposes a segmentation-guided domain-adaptation method to adapt images from multiple devices into single image domain, where the state-of-art pre-trained segmentation model is available. It avoids the time consumption of manual labelling for the upcoming new dataset and the re-training of the existing network. The semantic consistency and global feature consistency of the network will minimize the hallucination effect that many researchers reported regarding Cycle-Consistent Generative Adversarial Networks(CycleGAN) architecture.
Domain Adaptation via CycleGAN for Retina Segmentation in Optical Coherence Tomography
Jul 06, 2021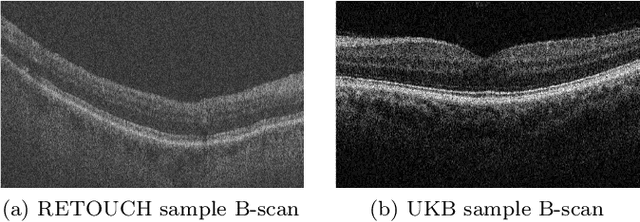
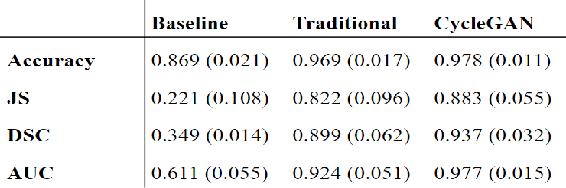
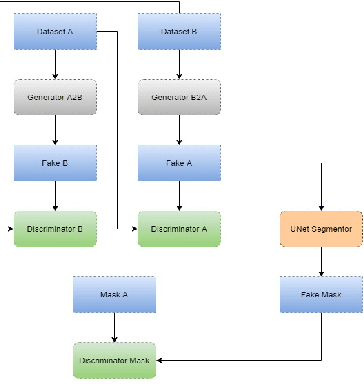
With the FDA approval of Artificial Intelligence (AI) for point-of-care clinical diagnoses, model generalizability is of the utmost importance as clinical decision-making must be domain-agnostic. A method of tackling the problem is to increase the dataset to include images from a multitude of domains; while this technique is ideal, the security requirements of medical data is a major limitation. Additionally, researchers with developed tools benefit from the addition of open-sourced data, but are limited by the difference in domains. Herewith, we investigated the implementation of a Cycle-Consistent Generative Adversarial Networks (CycleGAN) for the domain adaptation of Optical Coherence Tomography (OCT) volumes. This study was done in collaboration with the Biomedical Optics Research Group and Functional & Anatomical Imaging & Shape Analysis Lab at Simon Fraser University. In this study, we investigated a learning-based approach of adapting the domain of a publicly available dataset, UK Biobank dataset (UKB). To evaluate the performance of domain adaptation, we utilized pre-existing retinal layer segmentation tools developed on a different set of RETOUCH OCT data. This study provides insight on state-of-the-art tools for domain adaptation compared to traditional processing techniques as well as a pipeline for adapting publicly available retinal data to the domains previously used by our collaborators.
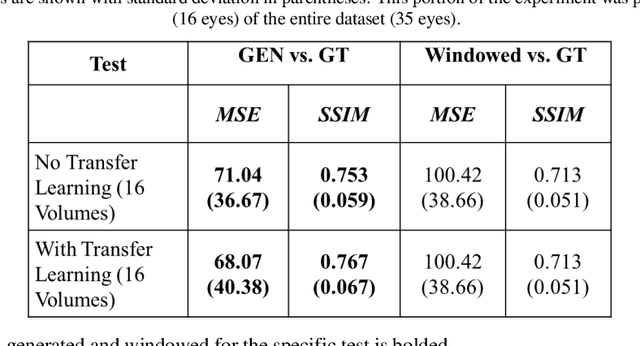
Microvasculature Segmentation and Inter-capillary Area Quantification of the Deep Vascular Complex using Transfer Learning
Mar 19, 2020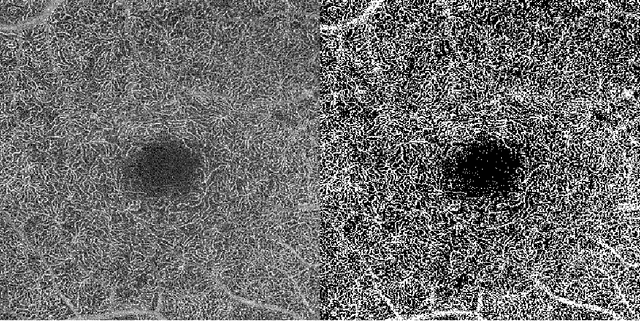
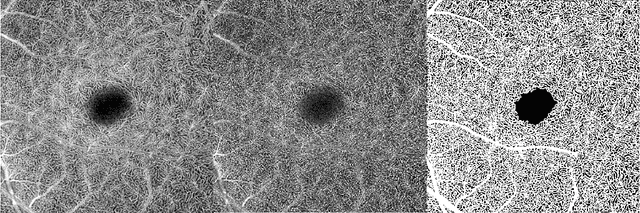

Purpose: Optical Coherence Tomography Angiography (OCT-A) permits visualization of the changes to the retinal circulation due to diabetic retinopathy (DR), a microvascular complication of diabetes. We demonstrate accurate segmentation of the vascular morphology for the superficial capillary plexus and deep vascular complex (SCP and DVC) using a convolutional neural network (CNN) for quantitative analysis. Methods: Retinal OCT-A with a 6x6mm field of view (FOV) were acquired using a Zeiss PlexElite. Multiple-volume acquisition and averaging enhanced the vessel network contrast used for training the CNN. We used transfer learning from a CNN trained on 76 images from smaller FOVs of the SCP acquired using different OCT systems. Quantitative analysis of perfusion was performed on the automated vessel segmentations in representative patients with DR. Results: The automated segmentations of the OCT-A images maintained the hierarchical branching and lobular morphologies of the SCP and DVC, respectively. The network segmented the SCP with an accuracy of 0.8599, and a Dice index of 0.8618. For the DVC, the accuracy was 0.7986, and the Dice index was 0.8139. The inter-rater comparisons for the SCP had an accuracy and Dice index of 0.8300 and 0.6700, respectively, and 0.6874 and 0.7416 for the DVC. Conclusions: Transfer learning reduces the amount of manually-annotated images required, while producing high quality automatic segmentations of the SCP and DVC. Using high quality training data preserves the characteristic appearance of the capillary networks in each layer. Translational Relevance: Accurate retinal microvasculature segmentation with the CNN results in improved perfusion analysis in diabetic retinopathy.
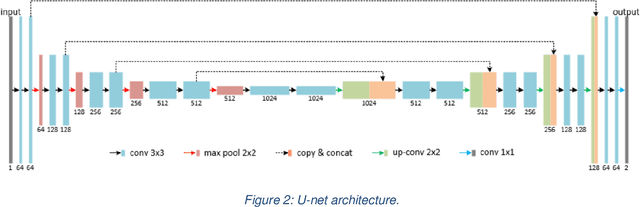
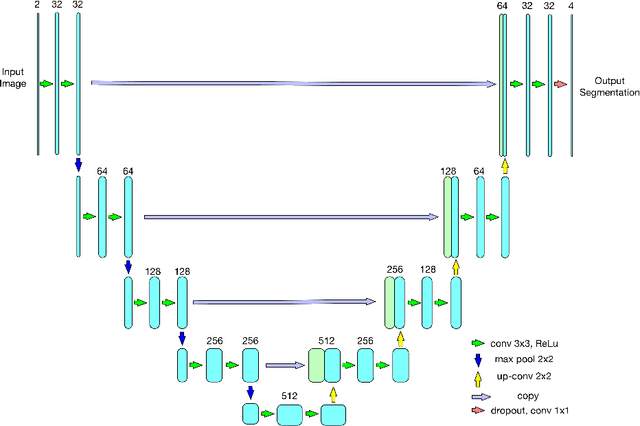
Cascaded Deep Neural Networks for Retinal Layer Segmentation of Optical Coherence Tomography with Fluid Presence
Dec 07, 2019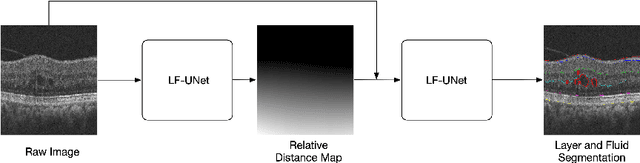
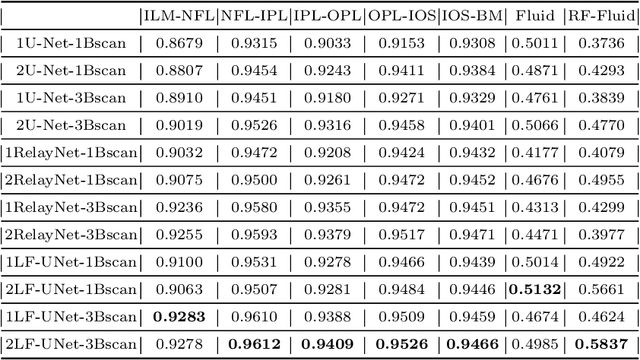
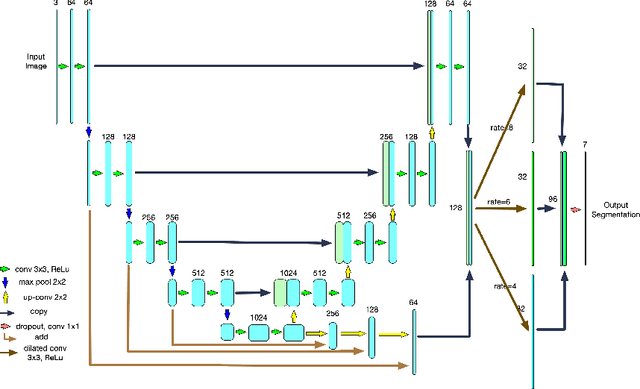
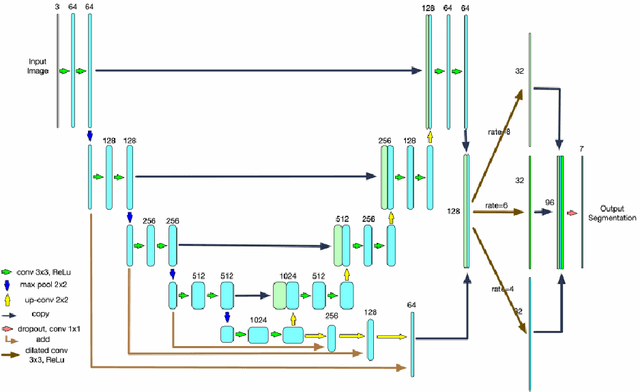
Optical coherence tomography (OCT) is a non-invasive imaging technology which can provide micrometer-resolution cross-sectional images of the inner structures of the eye. It is widely used for the diagnosis of ophthalmic diseases with retinal alteration, such as layer deformation and fluid accumulation. In this paper, a novel framework was proposed to segment retinal layers with fluid presence. The main contribution of this study is two folds: 1) we developed a cascaded network framework to incorporate the prior structural knowledge; 2) we proposed a novel deep neural network based on U-Net and fully convolutional network, termed LF-UNet. Cross validation experiments proved that the proposed LF-UNet has superior performance comparing with the state-of-the-art methods, and incorporating the relative distance map structural prior information could further improve the performance regardless the network.
Deep learning vessel segmentation and quantification of the foveal avascular zone using commercial and prototype OCT-A platforms
Sep 25, 2019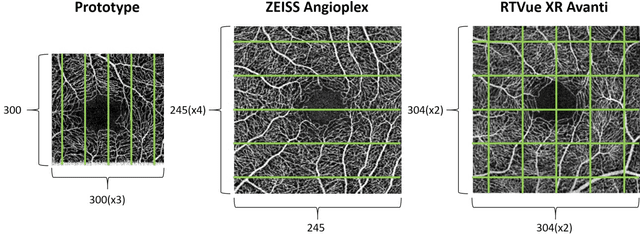


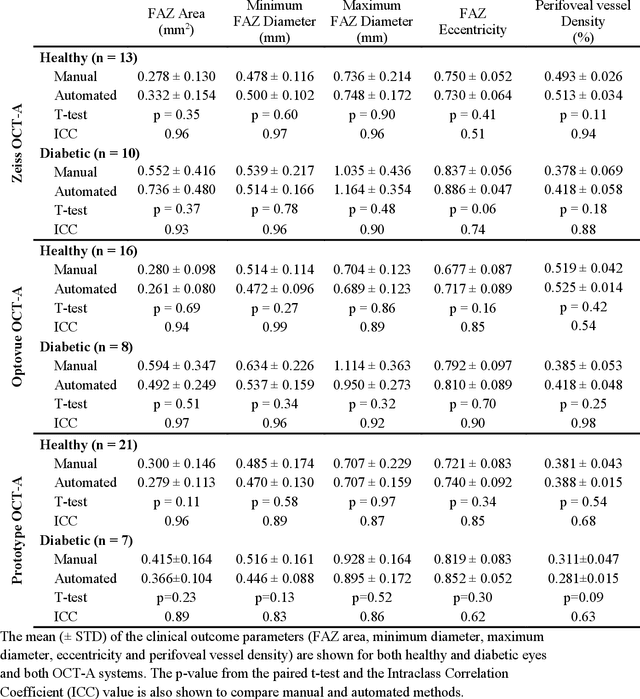
Automatic quantification of perifoveal vessel densities in optical coherence tomography angiography (OCT-A) images face challenges such as variable intra- and inter-image signal to noise ratios, projection artefacts from outer vasculature layers, and motion artefacts. This study demonstrates the utility of deep neural networks for automatic quantification of foveal avascular zone (FAZ) parameters and perifoveal vessel density of OCT-A images in healthy and diabetic eyes. OCT-A images of the foveal region were acquired using three OCT-A systems: a 1060nm Swept Source (SS)-OCT prototype, RTVue XR Avanti (Optovue Inc., Fremont, CA), and the ZEISS Angioplex (Carl Zeiss Meditec, Dublin, CA). Automated segmentation was then performed using a deep neural network. Four FAZ morphometric parameters (area, min/max diameter, and eccentricity) and perifoveal vessel density were used as outcome measures. The accuracy, sensitivity and specificity of the DNN vessel segmentations were comparable across all three device platforms. No significant difference between the means of the measurements from automated and manual segmentations were found for any of the outcome measures on any system. The intraclass correlation coefficient (ICC) was also good (> 0.51) for all measurements. Automated deep learning vessel segmentation of OCT-A may be suitable for both commercial and research purposes for better quantification of the retinal circulation.
Retinal Fluid Segmentation and Detection in Optical Coherence Tomography Images using Fully Convolutional Neural Network
Oct 13, 2017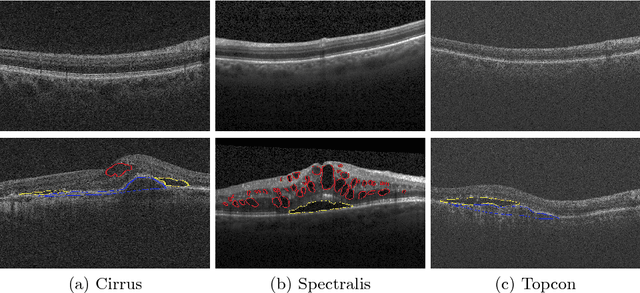

As a non-invasive imaging modality, optical coherence tomography (OCT) can provide micrometer-resolution 3D images of retinal structures. Therefore it is commonly used in the diagnosis of retinal diseases associated with edema in and under the retinal layers. In this paper, a new framework is proposed for the task of fluid segmentation and detection in retinal OCT images. Based on the raw images and layers segmented by a graph-cut algorithm, a fully convolutional neural network was trained to recognize and label the fluid pixels. Random forest classification was performed on the segmented fluid regions to detect and reject the falsely labeled fluid regions. The leave-one-out cross validation experiments on the RETOUCH database show that our method performs well in both segmentation (mean Dice: 0.7317) and detection (mean AUC: 0.985) tasks.