 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Language Vision Model Approach for Automated Tumor Contouring in Radiation Oncology
Mar 19, 2025



Background: Lung cancer ranks as the leading cause of cancer-related mortality worldwide. The complexity of tumor delineation, crucial for radiation therapy, requires expertise often unavailable in resource-limited settings. Artificial Intelligence(AI), particularly with advancements in deep learning (DL) and natural language processing (NLP), offers potential solutions yet is challenged by high false positive rates. Purpose: The Oncology Contouring Copilot (OCC) system is developed to leverage oncologist expertise for precise tumor contouring using textual descriptions, aiming to increase the efficiency of oncological workflows by combining the strengths of AI with human oversight. Methods: Our OCC system initially identifies nodule candidates from CT scans. Employing Language Vision Models (LVMs) like GPT-4V, OCC then effectively reduces false positives with clinical descriptive texts, merging textual and visual data to automate tumor delineation, designed to elevate the quality of oncology care by incorporating knowledge from experienced domain experts. Results: Deployments of the OCC system resulted in a significant reduction in the false discovery rate by 35.0%, a 72.4% decrease in false positives per scan, and an F1-score of 0.652 across our dataset for unbiased evaluation. Conclusions: OCC represents a significant advance in oncology care, particularly through the use of the latest LVMs to improve contouring results by (1) streamlining oncology treatment workflows by optimizing tumor delineation, reducing manual processes; (2) offering a scalable and intuitive framework to reduce false positives in radiotherapy planning using LVMs; (3) introducing novel medical language vision prompt techniques to minimize LVMs hallucinations with ablation study, and (4) conducting a comparative analysis of LVMs, highlighting their potential in addressing medical language vision challenges.
EXACT-Net:EHR-guided lung tumor auto-segmentation for non-small cell lung cancer radiotherapy
Feb 21, 2024



Lung cancer is a devastating disease with the highest mortality rate among cancer types. Over 60% of non-small cell lung cancer (NSCLC) patients, which accounts for 87% of diagnoses, require radiation therapy. Rapid treatment initiation significantly increases the patient's survival rate and reduces the mortality rate. Accurate tumor segmentation is a critical step in the diagnosis and treatment of NSCLC. Manual segmentation is time and labor-consuming and causes delays in treatment initiation. Although many lung nodule detection methods, including deep learning-based models, have been proposed, there is still a long-standing problem of high false positives (FPs) with most of these methods. Here, we developed an electronic health record (EHR) guided lung tumor auto-segmentation called EXACT-Net (EHR-enhanced eXACtitude in Tumor segmentation), where the extracted information from EHRs using a pre-trained large language model (LLM), was used to remove the FPs and keep the TP nodules only. The auto-segmentation model was trained on NSCLC patients' computed tomography (CT), and the pre-trained LLM was used with the zero-shot learning approach. Our approach resulted in a 250% boost in successful nodule detection using the data from ten NSCLC patients treated in our institution.
Enhanced Balancing GAN: Minority-class Image Generation
Oct 31, 2020
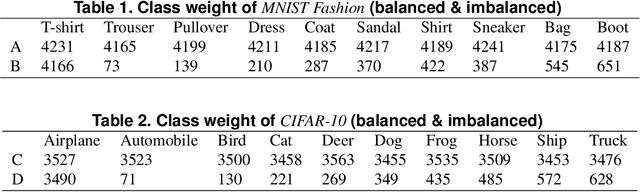
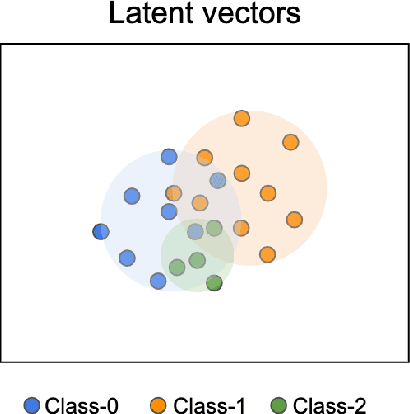
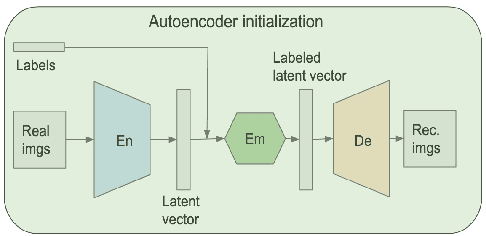
Generative adversarial networks (GANs) are one of the most powerful generative models, but always require a large and balanced dataset to train. Traditional GANs are not applicable to generate minority-class images in a highly imbalanced dataset. Balancing GAN (BAGAN) is proposed to mitigate this problem, but it is unstable when images in different classes look similar, e.g. flowers and cells. In this work, we propose a supervised autoencoder with an intermediate embedding model to disperse the labeled latent vectors. With the improved autoencoder initialization, we also build an architecture of BAGAN with gradient penalty (BAGAN-GP). Our proposed model overcomes the unstable issue in original BAGAN and converges faster to high quality generations. Our model achieves high performance on the imbalanced scale-down version of MNIST Fashion, CIFAR-10, and one small-scale medical image dataset.