 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Experts Meets Decoupled Message Passing: Towards General and Adaptive Node Classification
Paper and Code
Dec 11, 2024
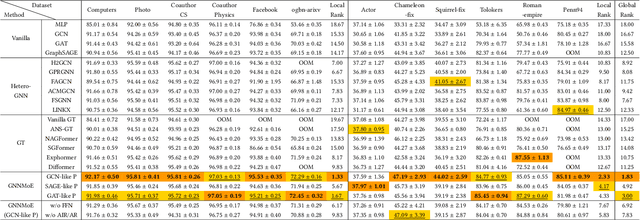


Graph neural networks excel at graph representation learning but struggle with heterophilous data and long-range dependencies. And graph transformers address these issues through self-attention, yet face scalability and noise challenges on large-scale graphs. To overcome these limitations, we propose GNNMoE, a universal model architecture for node classification. This architecture flexibly combines fine-grained message-passing operations with a mixture-of-experts mechanism to build feature encoding blocks. Furthermore, by incorporating soft and hard gating layers to assign the most suitable expert networks to each node, we enhance the model's expressive power and adaptability to different graph types. In addition, we introduce adaptive residual connections and an enhanced FFN module into GNNMoE, further improving the expressiveness of node representation. Extensive experimental results demonstrate that GNNMoE performs exceptionally well across various types of graph data, effectively alleviating the over-smoothing issue and global noise, enhancing model robustness and adaptability, while also ensuring computational efficiency on large-scale graphs.