 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery and Response Augmentation Cannot Help Out-of-domain Math Reasoning Generalization
Paper and Code

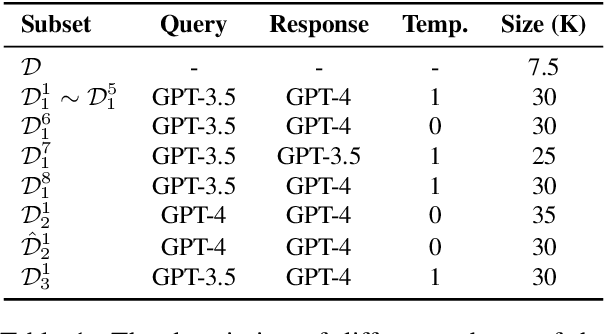
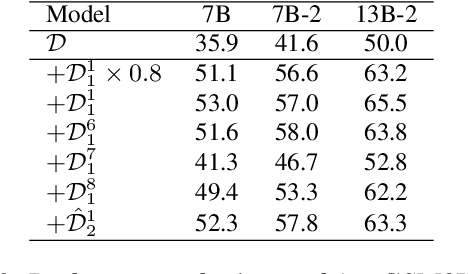
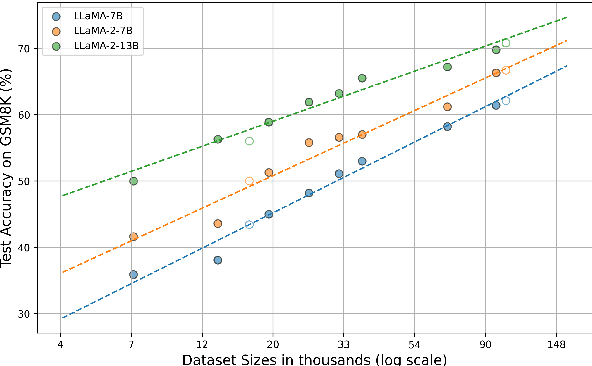
In math reasoning with large language models (LLMs), fine-tuning data augmentation by query evolution and diverse reasoning paths is empirically verified effective, profoundly narrowing the gap between open-sourced LLMs and cutting-edge proprietary LLMs. In this paper, we conduct an investigation for such data augmentation in math reasoning and are intended to answer: (1) What strategies of data augmentation are more effective; (2) What is the scaling relationship between the amount of augmented data and model performance; and (3) Can data augmentation incentivize generalization to out-of-domain mathematical reasoning tasks? To this end, we create a new dataset, AugGSM8K, by complicating and diversifying the queries from GSM8K and sampling multiple reasoning paths. We obtained a series of LLMs called MuggleMath by fine-tuning on subsets of AugGSM8K. MuggleMath substantially achieves new state-of-the-art on GSM8K (from 54% to 68.4% at the scale of 7B, and from 63.9% to 74.0% at the scale of 13B). A log-linear relationship is presented between MuggleMath's performance and the amount of augmented data. We also find that MuggleMath is weak in out-of-domain math reasoning generalization to MATH. This is attributed to the differences in query distribution between AugGSM8K and MATH which suggest that augmentation on a single benchmark could not help with overall math reasoning performance. Codes and AugGSM8K will be uploaded to https://github.com/OFA-Sys/gsm8k-ScRel.