 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Making the Most of BERT in Neural Machine Translation
Paper and Code


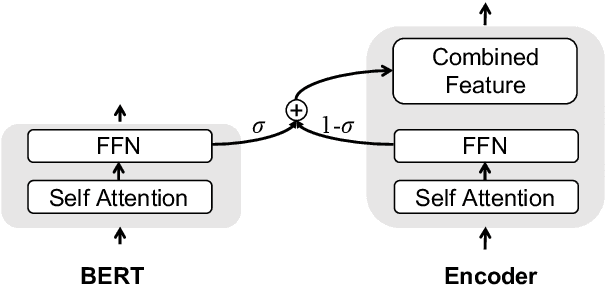
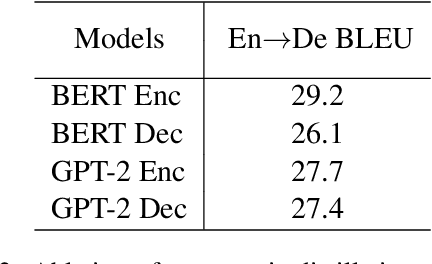
GPT-2 and BERT demonstrate the effectiveness of using pre-trained language models (LMs) on various natural language processing tasks. However, LM fine-tuning often suffers from catastrophic forgetting when applied to resource-rich tasks. In this work, we introduce a concerted training framework (\method) that is the key to integrate the pre-trained LMs to neural machine translation (NMT). Our proposed Cnmt consists of three techniques: a) asymptotic distillation to ensure that the NMT model can retain the previous pre-trained knowledge; \item a dynamic switching gate to avoid catastrophic forgetting of pre-trained knowledge; and b)a strategy to adjust the learning paces according to a scheduled policy. Our experiments in machine translation show \method gains of up to 3 BLEU score on the WMT14 English-German language pair which even surpasses the previous state-of-the-art pre-training aided NMT by 1.4 BLEU score. While for the large WMT14 English-French task with 40 millions of sentence-pairs, our base model still significantly improves upon the state-of-the-art Transformer big model by more than 1 BLEU score.