 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi'an: A Bilingual Benchmark and Model for Hallucination Detection in Retrieval-Augmented Generation
Feb 26, 2025Retrieval-Augmented Generation (RAG) effectively reduces hallucinations in Large Language Models (LLMs) but can still produce inconsistent or unsupported content. Although LLM-as-a-Judge is widely used for RAG hallucination detection due to its implementation simplicity, it faces two main challenges: the absence of comprehensive evaluation benchmarks and the lack of domain-optimized judge models. To bridge these gaps, we introduce \textbf{Bi'an}, a novel framework featuring a bilingual benchmark dataset and lightweight judge models. The dataset supports rigorous evaluation across multiple RAG scenarios, while the judge models are fine-tuned from compact open-source LLMs. Extensive experimental evaluations on Bi'anBench show our 14B model outperforms baseline models with over five times larger parameter scales and rivals state-of-the-art closed-source LLMs. We will release our data and models soon at https://github.com/OpenSPG/KAG.
Retrieve, Summarize, Plan: Advancing Multi-hop Question Answering with an Iterative Approach
Jul 18, 2024



Multi-hop question answering is a challenging task with distinct industrial relevance, and Retrieval-Augmented Generation (RAG) methods based on large language models (LLMs) have become a popular approach to tackle this task. Owing to the potential inability to retrieve all necessary information in a single iteration, a series of iterative RAG methods has been recently developed, showing significant performance improvements. However, existing methods still face two critical challenges: context overload resulting from multiple rounds of retrieval, and over-planning and repetitive planning due to the lack of a recorded retrieval trajectory. In this paper, we propose a novel iterative RAG method called ReSP, equipped with a dual-function summarizer. This summarizer compresses information from retrieved documents, targeting both the overarching question and the current sub-question concurrently. Experimental results on the multi-hop question-answering datasets HotpotQA and 2WikiMultihopQA demonstrate that our method significantly outperforms the state-of-the-art, and exhibits excellent robustness concerning context length.
Efficient Knowledge Infusion via KG-LLM Alignment
Jun 06, 2024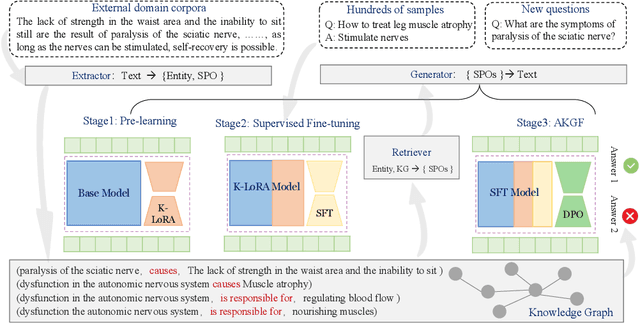
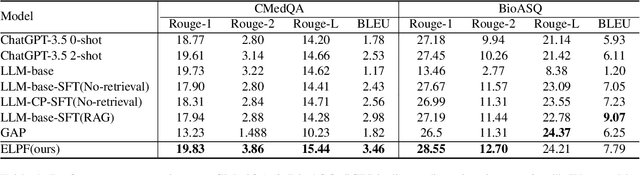
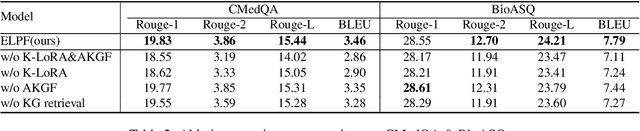
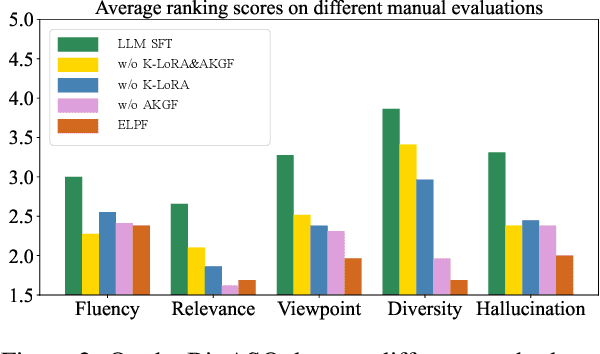
To tackle the problem of domain-specific knowledge scarcity within large language models (LLMs), knowledge graph-retrievalaugmented method has been proven to be an effective and efficient technique for knowledge infusion. However, existing approaches face two primary challenges: knowledge mismatch between public available knowledge graphs and the specific domain of the task at hand, and poor information compliance of LLMs with knowledge graphs. In this paper, we leverage a small set of labeled samples and a large-scale corpus to efficiently construct domain-specific knowledge graphs by an LLM, addressing the issue of knowledge mismatch. Additionally, we propose a three-stage KG-LLM alignment strategyto enhance the LLM's capability to utilize information from knowledge graphs. We conduct experiments with a limited-sample setting on two biomedical question-answering datasets, and the results demonstrate that our approach outperforms existing baselines.