 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Knowledge Infusion via KG-LLM Alignment
Jun 06, 2024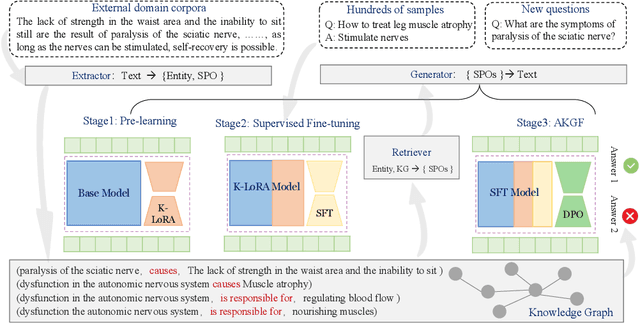
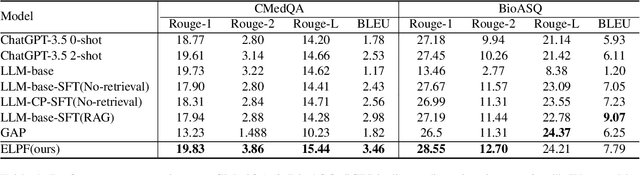
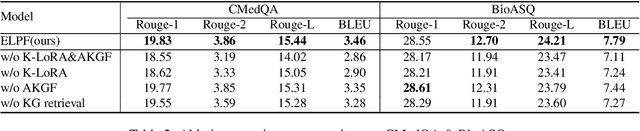
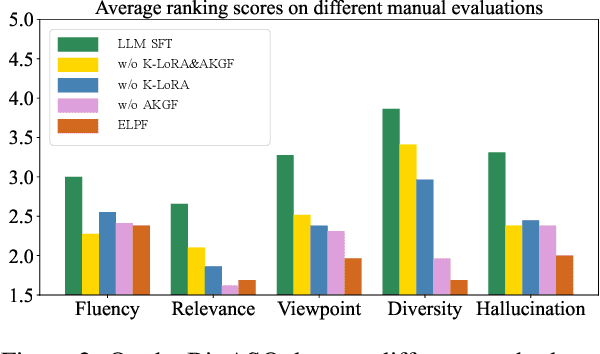
To tackle the problem of domain-specific knowledge scarcity within large language models (LLMs), knowledge graph-retrievalaugmented method has been proven to be an effective and efficient technique for knowledge infusion. However, existing approaches face two primary challenges: knowledge mismatch between public available knowledge graphs and the specific domain of the task at hand, and poor information compliance of LLMs with knowledge graphs. In this paper, we leverage a small set of labeled samples and a large-scale corpus to efficiently construct domain-specific knowledge graphs by an LLM, addressing the issue of knowledge mismatch. Additionally, we propose a three-stage KG-LLM alignment strategyto enhance the LLM's capability to utilize information from knowledge graphs. We conduct experiments with a limited-sample setting on two biomedical question-answering datasets, and the results demonstrate that our approach outperforms existing baselines.