 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIDER: Commonsense Inference for Dialogue Explanation and Reasoning
Paper and Code
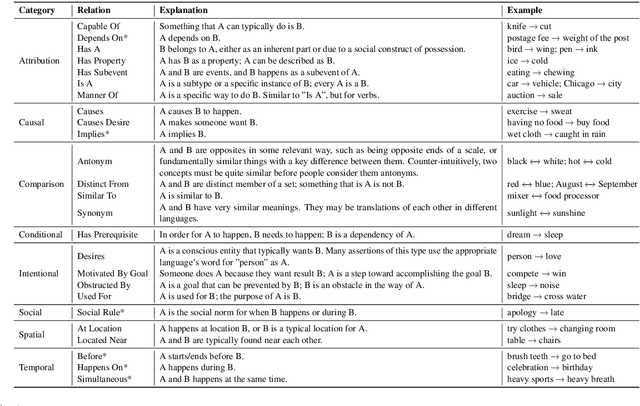

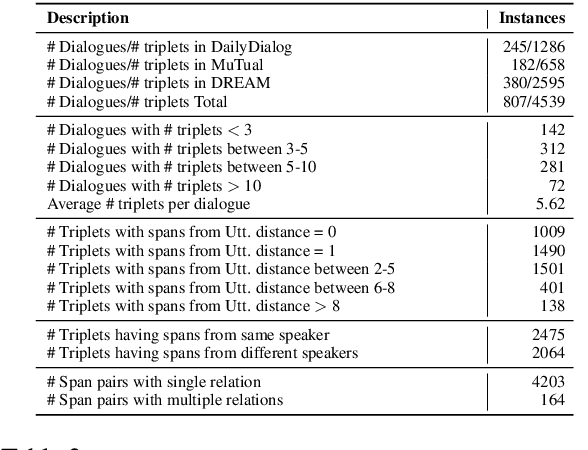

Commonsense inference to understand and explain human language is a fundamental research problem in natural language processing. Explaining human conversations poses a great challenge as it requires contextual understanding, planning, inference, and several aspects of reasoning including causal, temporal, and commonsense reasoning. In this work, we introduce CIDER -- a manually curated dataset that contains dyadic dialogue explanations in the form of implicit and explicit knowledge triplets inferred using contextual commonsense inference. Extracting such rich explanations from conversations can be conducive to improving several downstream applications. The annotated triplets are categorized by the type of commonsense knowledge present (e.g., causal, conditional, temporal). We set up three different tasks conditioned on the annotated dataset: Dialogue-level Natural Language Inference, Span Extraction, and Multi-choice Span Selection. Baseline results obtained with transformer-based models reveal that the tasks are difficult, paving the way for promising future research. The dataset and the baseline implementations are publicly available at https://github.com/declare-lab/CIDER.