 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-Reflection: Empowering Multimodal GUI Models with Self-Reflection Behavior
Jun 09, 2025



Multimodal Large Language Models (MLLMs) have shown great potential in revolutionizing Graphical User Interface (GUI) automation. However, existing GUI models mostly rely on learning from nearly error-free offline trajectories, thus lacking reflection and error recovery capabilities. To bridge this gap, we propose GUI-Reflection, a novel framework that explicitly integrates self-reflection and error correction capabilities into end-to-end multimodal GUI models throughout dedicated training stages: GUI-specific pre-training, offline supervised fine-tuning (SFT), and online reflection tuning. GUI-reflection enables self-reflection behavior emergence with fully automated data generation and learning processes without requiring any human annotation. Specifically, 1) we first propose scalable data pipelines to automatically construct reflection and error correction data from existing successful trajectories. While existing GUI models mainly focus on grounding and UI understanding ability, we propose the GUI-Reflection Task Suite to learn and evaluate reflection-oriented abilities explicitly. 2) Furthermore, we built a diverse and efficient environment for online training and data collection of GUI models on mobile devices. 3) We also present an iterative online reflection tuning algorithm leveraging the proposed environment, enabling the model to continuously enhance its reflection and error correction abilities. Our framework equips GUI agents with self-reflection and correction capabilities, paving the way for more robust, adaptable, and intelligent GUI automation, with all data, models, environments, and tools to be released publicly.
LogoDet-3K: A Large-Scale Image Dataset for Logo Detection
Aug 12, 2020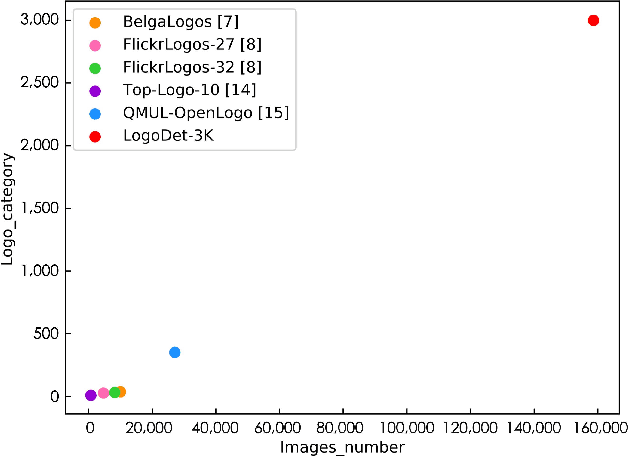
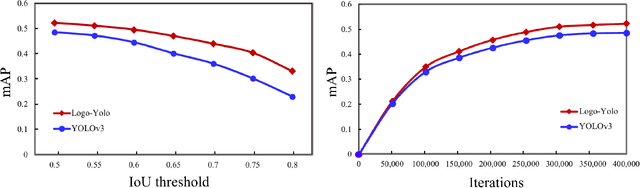


Logo detection has been gaining considerable attention because of its wide range of applications in the multimedia field, such as copyright infringement detection, brand visibility monitoring, and product brand management on social media. In this paper, we introduce LogoDet-3K, the largest logo detection dataset with full annotation, which has 3,000 logo categories, about 200,000 manually annotated logo objects and 158,652 images. LogoDet-3K creates a more challenging benchmark for logo detection, for its higher comprehensive coverage and wider variety in both logo categories and annotated objects compared with existing datasets. We describe the collection and annotation process of our dataset, analyze its scale and diversity in comparison to other datasets for logo detection. We further propose a strong baseline method Logo-Yolo, which incorporates Focal loss and CIoU loss into the state-of-the-art YOLOv3 framework for large-scale logo detection. Logo-Yolo can solve the problems of multi-scale objects, logo sample imbalance and inconsistent bounding-box regression. It obtains about 4% improvement on the average performance compared with YOLOv3, and greater improvements compared with reported several deep detection models on LogoDet-3K. The evaluations on other three existing datasets further verify the effectiveness of our method, and demonstrate better generalization ability of LogoDet-3K on logo detection and retrieval tasks. The LogoDet-3K dataset is used to promote large-scale logo-related research and it can be found at https://github.com/Wangjing1551/LogoDet-3K-Dataset.
Logo-2K+: A Large-Scale Logo Dataset for Scalable Logo Classification
Nov 11, 2019
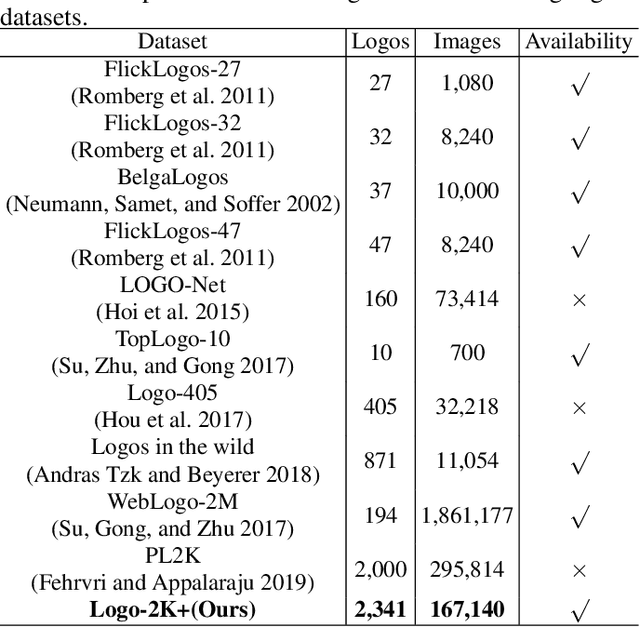
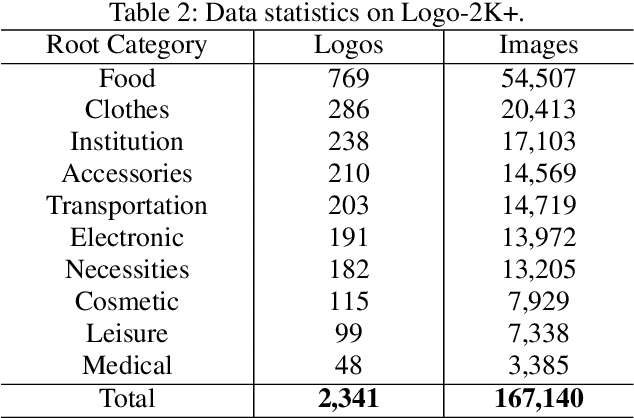
Logo classification has gained increasing attention for its various applications, such as copyright infringement detection, product recommendation and contextual advertising. Compared with other types of object images, the real-world logo images have larger variety in logo appearance and more complexity in their background. Therefore, recognizing the logo from images is challenging. To support efforts towards scalable logo classification task, we have curated a dataset, Logo-2K+, a new large-scale publicly available real-world logo dataset with 2,341 categories and 167,140 images. Compared with existing popular logo datasets, such as FlickrLogos-32 and LOGO-Net, Logo-2K+ has more comprehensive coverage of logo categories and larger quantity of logo images. Moreover, we propose a Discriminative Region Navigation and Augmentation Network (DRNA-Net), which is capable of discovering more informative logo regions and augmenting these image regions for logo classification. DRNA-Net consists of four sub-networks: the navigator sub-network first selected informative logo-relevant regions guided by the teacher sub-network, which can evaluate its confidence belonging to the ground-truth logo class. The data augmentation sub-network then augments the selected regions via both region cropping and region dropping. Finally, the scrutinizer sub-network fuses features from augmented regions and the whole image for logo classification. Comprehensive experiments on Logo-2K+ and other three existing benchmark datasets demonstrate the effectiveness of proposed method. Logo-2K+ and the proposed strong baseline DRNA-Net are expected to further the development of scalable logo image recognition, and the Logo-2K+ dataset can be found at https://github.com/msn199959/Logo-2k-plus-Dataset.