 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Imitation Learning for Autonomous Driving with Feedback Synthesizer and Differentiable Rasterization
Mar 02, 2021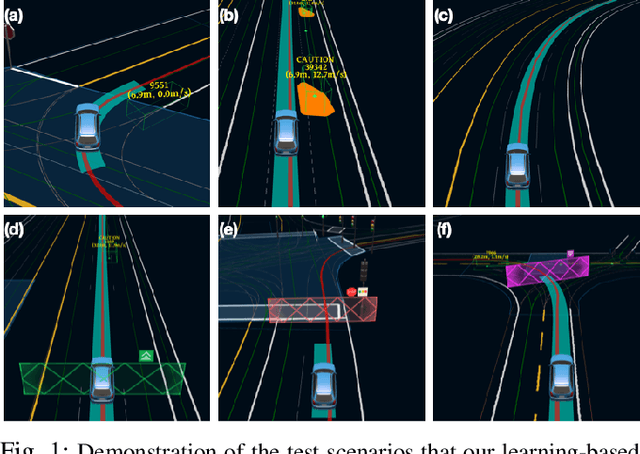
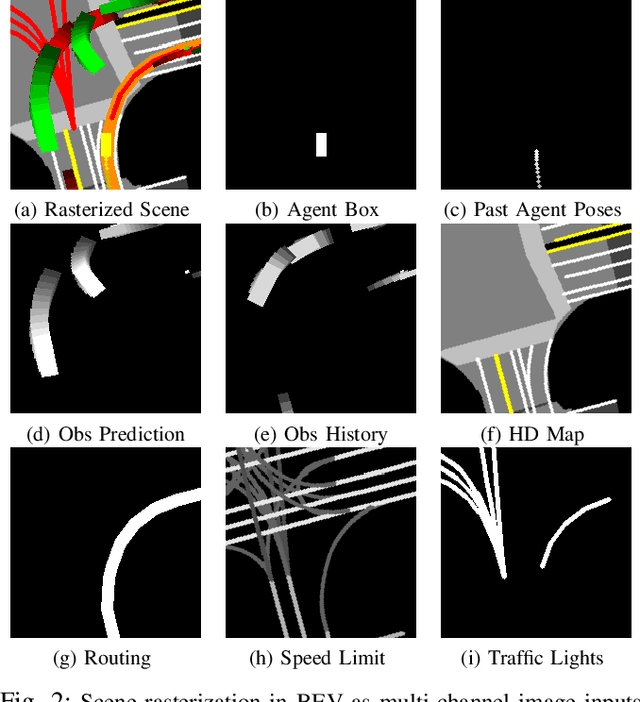
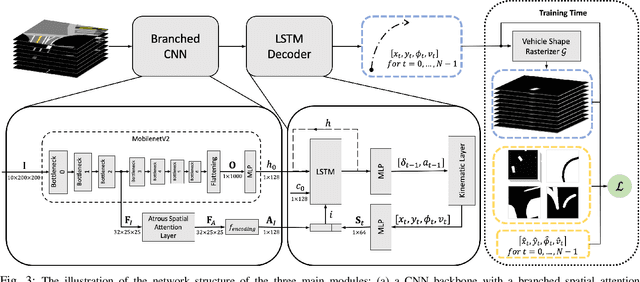

We present a learning-based planner that aims to robustly drive a vehicle by mimicking human drivers' driving behavior. We leverage a mid-to-mid approach that allows us to manipulate the input to our imitation learning network freely. With that in mind, we propose a novel feedback synthesizer for data augmentation. It allows our agent to gain more driving experience in various previously unseen environments that are likely to encounter, thus improving overall performance. This is in contrast to prior works that rely purely on random synthesizers. Furthermore, rather than completely commit to imitating, we introduce task losses that penalize undesirable behaviors, such as collision, off-road, and so on. Unlike prior works, this is done by introducing a differentiable vehicle rasterizer that directly converts the waypoints output by the network into images. This effectively avoids the usage of heavyweight ConvLSTM networks, therefore, yields a faster model inference time. About the network architecture, we exploit an attention mechanism that allows the network to reason critical objects in the scene and produce better interpretable attention heatmaps. To further enhance the safety and robustness of the network, we add an optional optimization-based post-processing planner improving the driving comfort. We comprehensively validate our method's effectiveness in different scenarios that are specifically created for evaluating self-driving vehicles. Results demonstrate that our learning-based planner achieves high intelligence and can handle complex situations. Detailed ablation and visualization analysis are included to further demonstrate each of our proposed modules' effectiveness in our method.
TDR-OBCA: A Reliable Planner for Autonomous Driving in Free-Space Environment
Sep 23, 2020
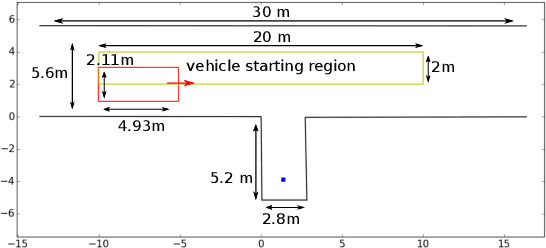
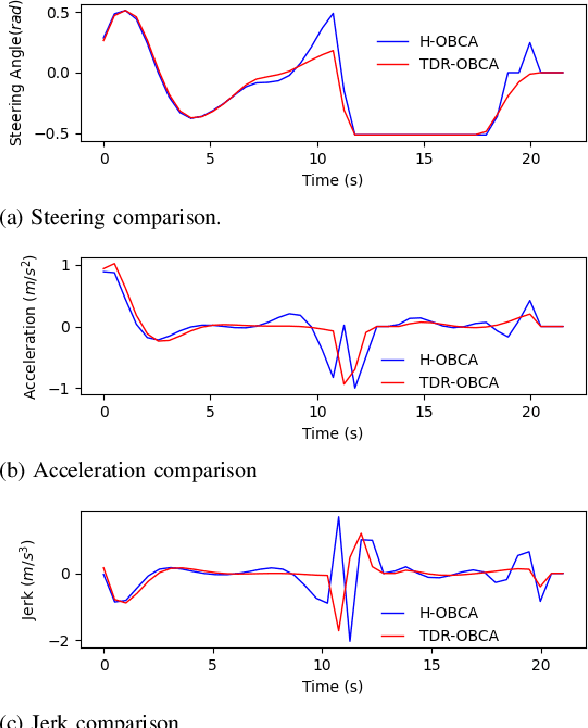

This paper presents an optimization-based collision avoidance trajectory generation method for autonomous driving in free-space environments, with enhanced robust-ness, driving comfort and efficiency. Starting from the hybrid optimization-based framework, we introduces two warm start methods, temporal and dual variable warm starts, to improve the efficiency. We also reformulates the problem to improve the robustness and efficiency. We name this new algorithm TDR-OBCA. With these changes, compared with original hybrid optimization we achieve a 96.67% failure rate decrease with respect to initial conditions, 13.53% increase in driving comforts and 3.33% to 44.82% increase in planner efficiency as obstacles number scales. We validate our results in hundreds of simulation scenarios and hundreds of hours of public road tests in both U.S. and China. Our source code is availableathttps://github.com/ApolloAuto/apollo.