 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Self-Interference Cancellation With Robust Multi-layered Total Least Mean Squares Adaptive Filters
Aug 06, 2023



In simultaneous transmit and receive (STAR) wireless communications, digital self-interference (SI) cancellation is required before estimating the remote transmission (RT) channel. Considering the inherent connection between SI channel reconstruction and RT channel estimation, we propose a multi-layered M-estimate total least mean squares (m-MTLS) joint estimator to estimate both channels. In each layer, our proposed m-MTLS estimator first employs an M-estimate total least mean squares (MTLS) algorithm to eliminate residual SI from the received signal and give a new estimation of the RT channel. Then, it gives the final RT channel estimation based on the weighted sum of the estimation values obtained from each layer. Compared to traditional minimum mean square error (MMSE) estimator and single-layered MTLS estimator, it demonstrates that the m-MTLS estimator has better performance of normalized mean squared difference (NMSD). Besides, the simulation results also show the robustness of m-MTLS estimator even in scenarios where the local reference signal is contaminated with noise, and the received signal is impacted by strong impulse noise.
Overview and Performance Analysis of Various Waveforms in High Mobility Scenarios
Feb 28, 2023In the high-mobility scenarios of next-generation wireless communication systems (beyond 5G/6G), the performance of orthogonal frequency division multiplexing (OFDM) deteriorates drastically due to the loss of orthogonality between the subcarriers caused by large Doppler frequency shifts. Various emerging waveforms have been proposed for fast time-varying channels with excellent results. In this paper, we classify these waveforms from the perspective of their modulation domain and establish a unified framework to provide a comprehensive system structure comparison. Then we analyze bit error rate (BER) performance of each waveform in doubly selective channels. Through the discussions on their complexity and compatibility with OFDM systems, we finally give the candidate waveform suggestions.
Diff-Net: Image Feature Difference based High-Definition Map Change Detection
Jul 14, 2021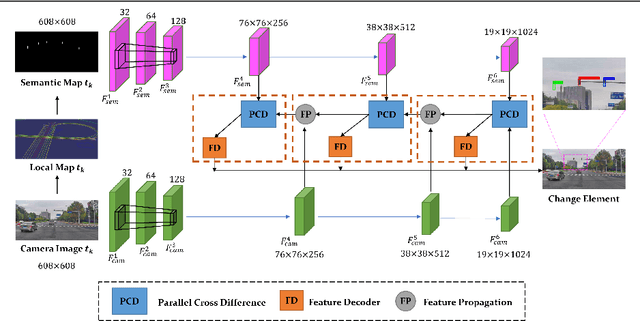

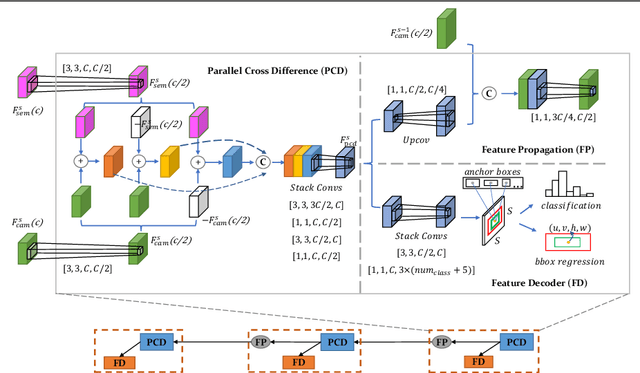

Up-to-date High-Definition (HD) maps are essential for self-driving cars. To achieve constantly updated HD maps, we present a deep neural network (DNN), Diff-Net, to detect changes in them. Compared to traditional methods based on object detectors, the essential design in our work is a parallel feature difference calculation structure that infers map changes by comparing features extracted from the camera and rasterized images. To generate these rasterized images, we project map elements onto images in the camera view, yielding meaningful map representations that can be consumed by a DNN accordingly. As we formulate the change detection task as an object detection problem, we leverage the anchor-based structure that predicts bounding boxes with different change status categories. Furthermore, rather than relying on single frame input, we introduce a spatio-temporal fusion module that fuses features from history frames into the current, thus improving the overall performance. Finally, we comprehensively validate our method's effectiveness using freshly collected datasets. Results demonstrate that our Diff-Net achieves better performance than the baseline methods and is ready to be integrated into a map production pipeline maintaining an up-to-date HD map.
Exploring Imitation Learning for Autonomous Driving with Feedback Synthesizer and Differentiable Rasterization
Mar 02, 2021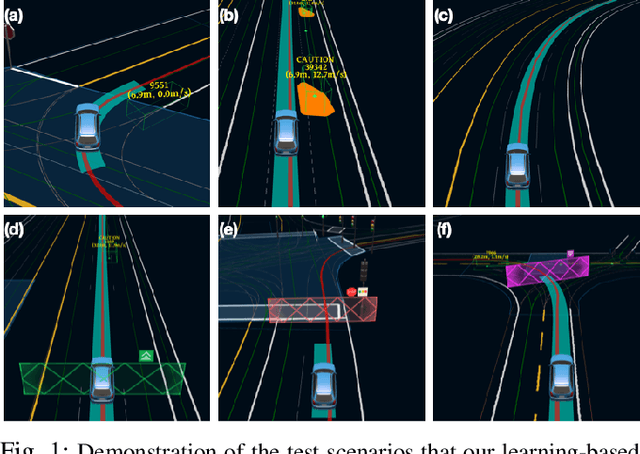
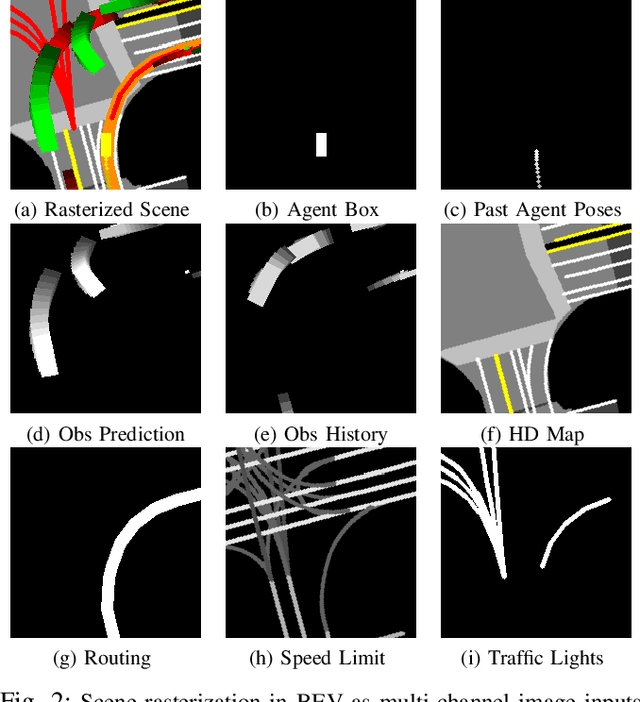
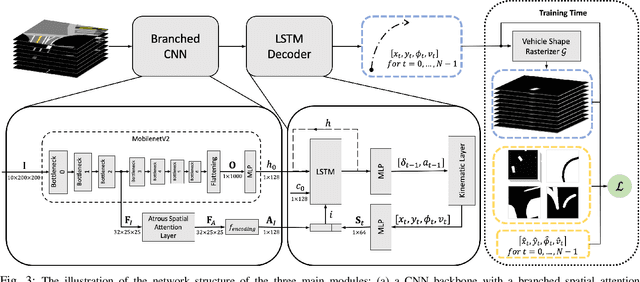

We present a learning-based planner that aims to robustly drive a vehicle by mimicking human drivers' driving behavior. We leverage a mid-to-mid approach that allows us to manipulate the input to our imitation learning network freely. With that in mind, we propose a novel feedback synthesizer for data augmentation. It allows our agent to gain more driving experience in various previously unseen environments that are likely to encounter, thus improving overall performance. This is in contrast to prior works that rely purely on random synthesizers. Furthermore, rather than completely commit to imitating, we introduce task losses that penalize undesirable behaviors, such as collision, off-road, and so on. Unlike prior works, this is done by introducing a differentiable vehicle rasterizer that directly converts the waypoints output by the network into images. This effectively avoids the usage of heavyweight ConvLSTM networks, therefore, yields a faster model inference time. About the network architecture, we exploit an attention mechanism that allows the network to reason critical objects in the scene and produce better interpretable attention heatmaps. To further enhance the safety and robustness of the network, we add an optional optimization-based post-processing planner improving the driving comfort. We comprehensively validate our method's effectiveness in different scenarios that are specifically created for evaluating self-driving vehicles. Results demonstrate that our learning-based planner achieves high intelligence and can handle complex situations. Detailed ablation and visualization analysis are included to further demonstrate each of our proposed modules' effectiveness in our method.
SOSD-Net: Joint Semantic Object Segmentation and Depth Estimation from Monocular images
Jan 19, 2021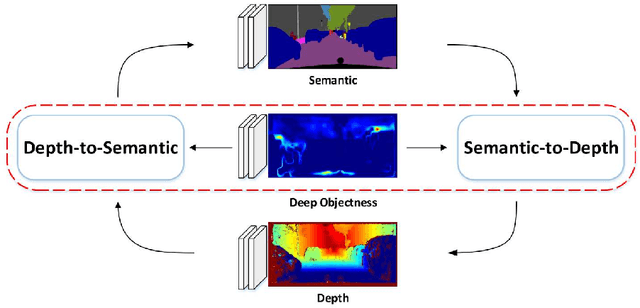
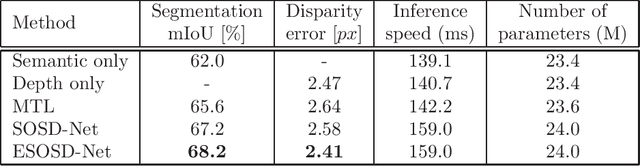
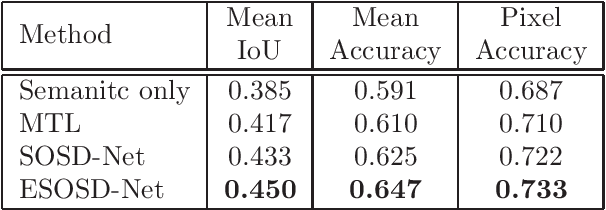
Depth estimation and semantic segmentation play essential roles in scene understanding. The state-of-the-art methods employ multi-task learning to simultaneously learn models for these two tasks at the pixel-wise level. They usually focus on sharing the common features or stitching feature maps from the corresponding branches. However, these methods lack in-depth consideration on the correlation of the geometric cues and the scene parsing. In this paper, we first introduce the concept of semantic objectness to exploit the geometric relationship of these two tasks through an analysis of the imaging process, then propose a Semantic Object Segmentation and Depth Estimation Network (SOSD-Net) based on the objectness assumption. To the best of our knowledge, SOSD-Net is the first network that exploits the geometry constraint for simultaneous monocular depth estimation and semantic segmentation. In addition, considering the mutual implicit relationship between these two tasks, we exploit the iterative idea from the expectation-maximization algorithm to train the proposed network more effectively. Extensive experimental results on the Cityscapes and NYU v2 dataset are presented to demonstrate the superior performance of the proposed approach.
TDR-OBCA: A Reliable Planner for Autonomous Driving in Free-Space Environment
Sep 23, 2020
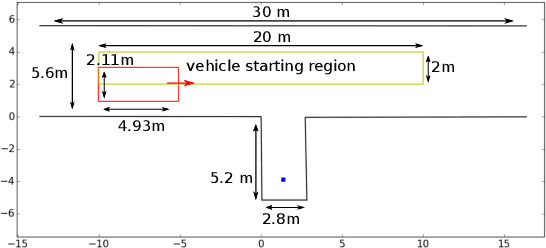
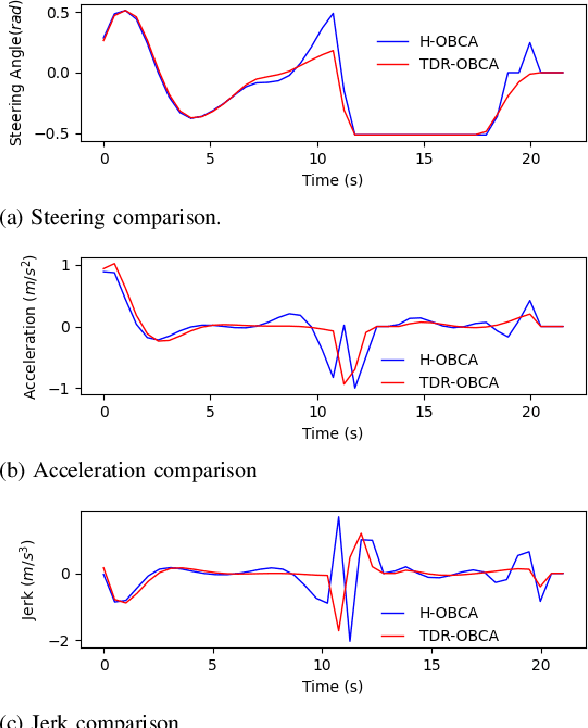

This paper presents an optimization-based collision avoidance trajectory generation method for autonomous driving in free-space environments, with enhanced robust-ness, driving comfort and efficiency. Starting from the hybrid optimization-based framework, we introduces two warm start methods, temporal and dual variable warm starts, to improve the efficiency. We also reformulates the problem to improve the robustness and efficiency. We name this new algorithm TDR-OBCA. With these changes, compared with original hybrid optimization we achieve a 96.67% failure rate decrease with respect to initial conditions, 13.53% increase in driving comforts and 3.33% to 44.82% increase in planner efficiency as obstacles number scales. We validate our results in hundreds of simulation scenarios and hundreds of hours of public road tests in both U.S. and China. Our source code is availableathttps://github.com/ApolloAuto/apollo.
DA4AD: End-to-end Deep Attention Aware Features Aided Visual Localization for Autonomous Driving
Mar 06, 2020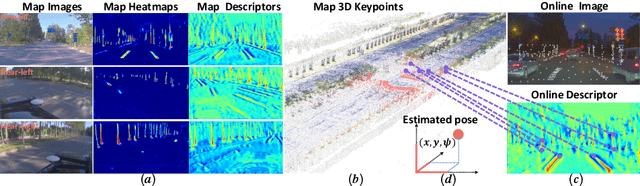
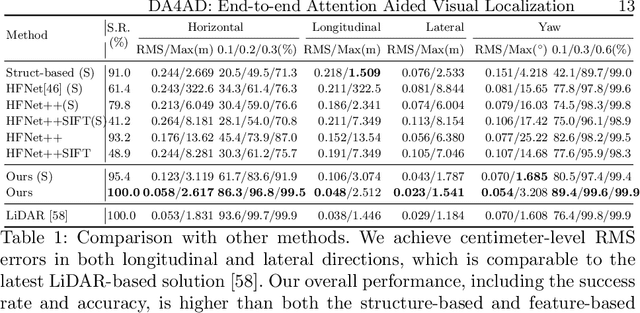
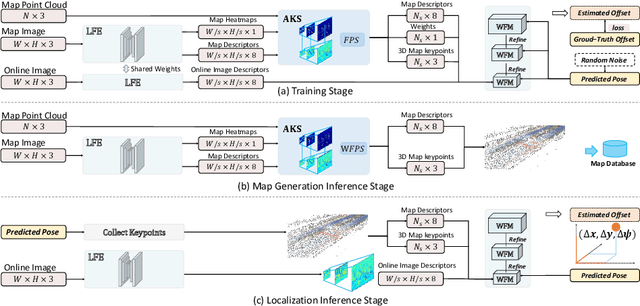
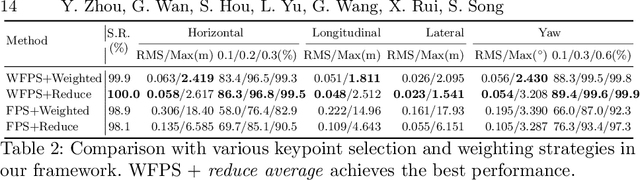
We present a visual localization framework aided by novel deep attention aware features for autonomous driving that achieves centimeter level localization accuracy. Conventional approaches to the visual localization problem rely on handcrafted features or human-made objects on the road. They are known to be either prone to unstable matching caused by severe appearance or lighting changes, or too scarce to deliver constant and robust localization results in challenging scenarios. In this work, we seek to exploit the deep attention mechanism to search for salient, distinctive and stable features that are good for long-term matching in the scene through a novel end-to-end deep neural network. Furthermore, our learned feature descriptors are demonstrated to be competent to establish robust matches and therefore successfully estimate the optimal camera poses with high precision. We comprehensively validate the effectiveness of our method using a freshly collected dataset with high-quality ground truth trajectories and hardware synchronization between sensors. Results demonstrate that our method achieves a competitive localization accuracy when compared to the LiDAR-based localization solutions under various challenging circumstances, leading to a potential low-cost localization solution for autonomous driving.
DeepICP: An End-to-End Deep Neural Network for 3D Point Cloud Registration
May 10, 2019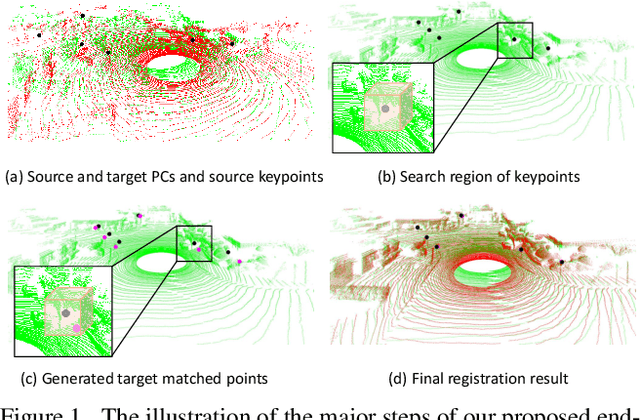
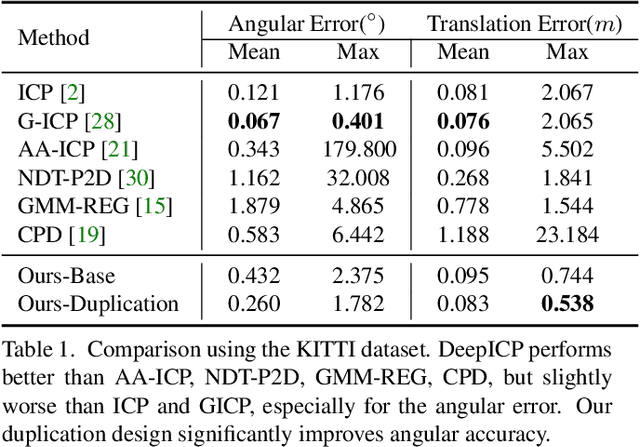
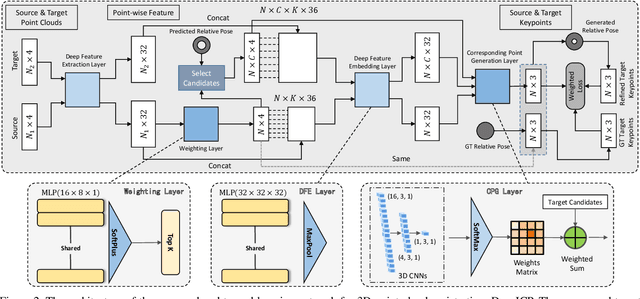
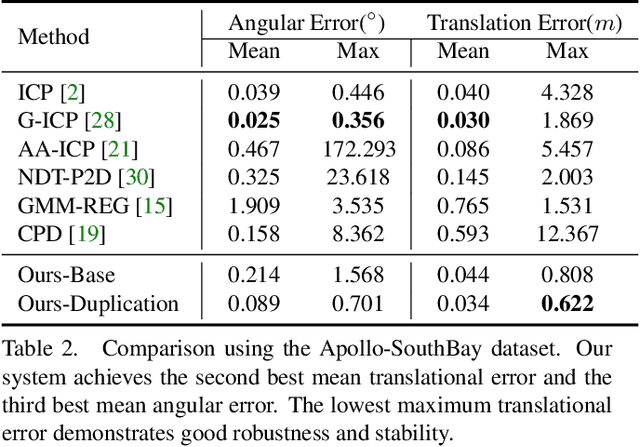
We present DeepICP - a novel end-to-end learning-based 3D point cloud registration framework that achieves comparable registration accuracy to prior state-of-the-art geometric methods. Different from other keypoint based methods where a RANSAC procedure is usually needed, we implement the use of various deep neural network structures to establish an end-to-end trainable network. Our keypoint detector is trained through this end-to-end structure and enables the system to avoid the inference of dynamic objects, leverages the help of sufficiently salient features on stationary objects, and as a result, achieves high robustness. Rather than searching the corresponding points among existing points, the key contribution is that we innovatively generate them based on learned matching probabilities among a group of candidates, which can boost the registration accuracy. Our loss function incorporates both the local similarity and the global geometric constraints to ensure all above network designs can converge towards the right direction. We comprehensively validate the effectiveness of our approach using both the KITTI dataset and the Apollo-SouthBay dataset. Results demonstrate that our method achieves comparable or better performance than the state-of-the-art geometry-based methods. Detailed ablation and visualization analysis are included to further illustrate the behavior and insights of our network. The low registration error and high robustness of our method makes it attractive for substantial applications relying on the point cloud registration task.
Robust and Precise Vehicle Localization based on Multi-sensor Fusion in Diverse City Scenes
Nov 15, 2017
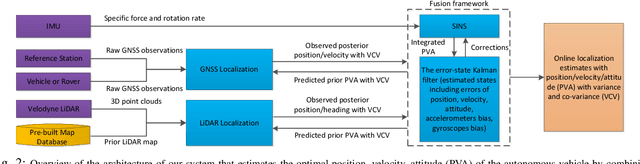
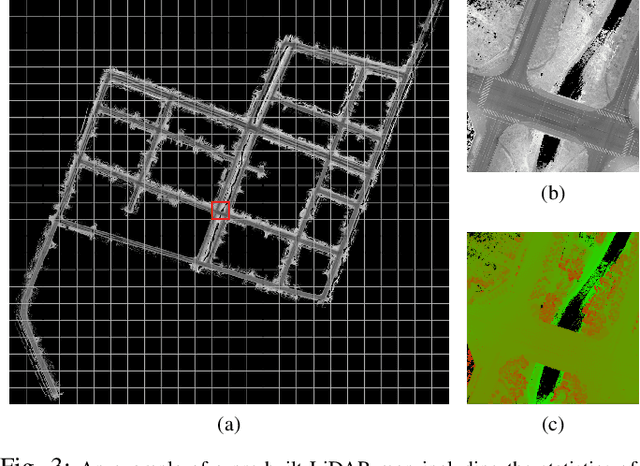
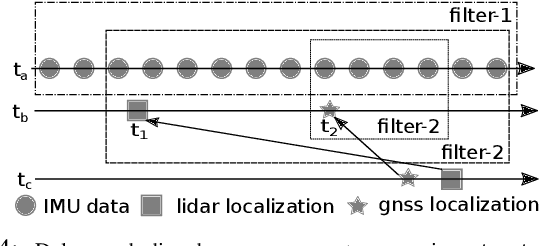
We present a robust and precise localization system that achieves centimeter-level localization accuracy in disparate city scenes. Our system adaptively uses information from complementary sensors such as GNSS, LiDAR, and IMU to achieve high localization accuracy and resilience in challenging scenes, such as urban downtown, highways, and tunnels. Rather than relying only on LiDAR intensity or 3D geometry, we make innovative use of LiDAR intensity and altitude cues to significantly improve localization system accuracy and robustness. Our GNSS RTK module utilizes the help of the multi-sensor fusion framework and achieves a better ambiguity resolution success rate. An error-state Kalman filter is applied to fuse the localization measurements from different sources with novel uncertainty estimation. We validate, in detail, the effectiveness of our approaches, achieving 5-10cm RMS accuracy and outperforming previous state-of-the-art systems. Importantly, our system, while deployed in a large autonomous driving fleet, made our vehicles fully autonomous in crowded city streets despite road construction that occurred from time to time. A dataset including more than 60 km real traffic driving in various urban roads is used to comprehensively test our system.