 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoadPainter: Points Are Ideal Navigators for Topology transformER
Jul 22, 2024



Topology reasoning aims to provide a precise understanding of road scenes, enabling autonomous systems to identify safe and efficient routes. In this paper, we present RoadPainter, an innovative approach for detecting and reasoning the topology of lane centerlines using multi-view images. The core concept behind RoadPainter is to extract a set of points from each centerline mask to improve the accuracy of centerline prediction. We start by implementing a transformer decoder that integrates a hybrid attention mechanism and a real-virtual separation strategy to predict coarse lane centerlines and establish topological associations. Then, we generate centerline instance masks guided by the centerline points from the transformer decoder. Moreover, we derive an additional set of points from each mask and combine them with previously detected centerline points for further refinement. Additionally, we introduce an optional module that incorporates a Standard Definition (SD) map to further optimize centerline detection and enhance topological reasoning performance. Experimental evaluations on the OpenLane-V2 dataset demonstrate the state-of-the-art performance of RoadPainter.
EgoVM: Achieving Precise Ego-Localization using Lightweight Vectorized Maps
Jul 18, 2023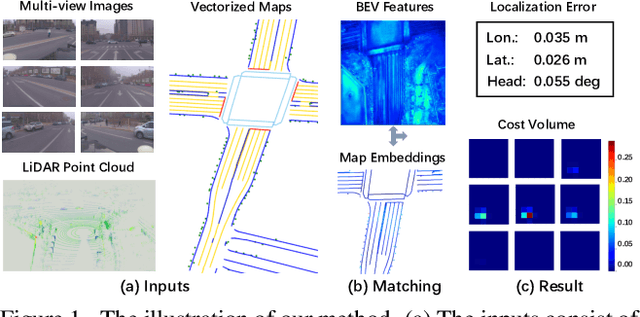

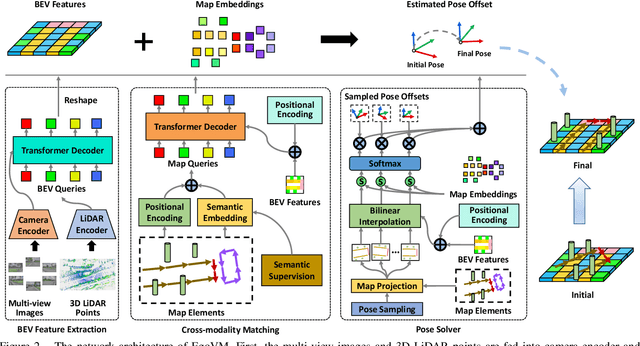

Accurate and reliable ego-localization is critical for autonomous driving. In this paper, we present EgoVM, an end-to-end localization network that achieves comparable localization accuracy to prior state-of-the-art methods, but uses lightweight vectorized maps instead of heavy point-based maps. To begin with, we extract BEV features from online multi-view images and LiDAR point cloud. Then, we employ a set of learnable semantic embeddings to encode the semantic types of map elements and supervise them with semantic segmentation, to make their feature representation consistent with BEV features. After that, we feed map queries, composed of learnable semantic embeddings and coordinates of map elements, into a transformer decoder to perform cross-modality matching with BEV features. Finally, we adopt a robust histogram-based pose solver to estimate the optimal pose by searching exhaustively over candidate poses. We comprehensively validate the effectiveness of our method using both the nuScenes dataset and a newly collected dataset. The experimental results show that our method achieves centimeter-level localization accuracy, and outperforms existing methods using vectorized maps by a large margin. Furthermore, our model has been extensively tested in a large fleet of autonomous vehicles under various challenging urban scenes.
A Unified BEV Model for Joint Learning of 3D Local Features and Overlap Estimation
Mar 14, 2023
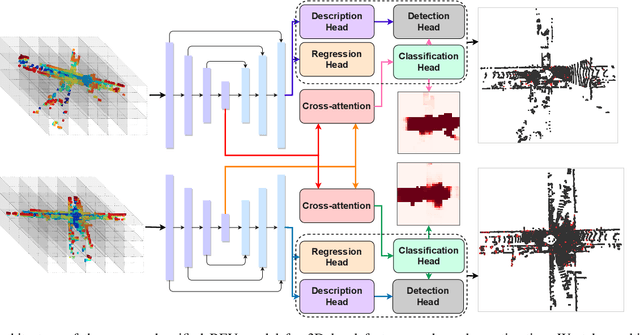


Pairwise point cloud registration is a critical task for many applications, which heavily depends on finding correct correspondences from the two point clouds. However, the low overlap between input point clouds causes the registration to fail easily, leading to mistaken overlapping and mismatched correspondences, especially in scenes where non-overlapping regions contain similar structures. In this paper, we present a unified bird's-eye view (BEV) model for jointly learning of 3D local features and overlap estimation to fulfill pairwise registration and loop closure. Feature description is performed by a sparse UNet-like network based on BEV representation, and 3D keypoints are extracted by a detection head for 2D locations, and a regression head for heights. For overlap detection, a cross-attention module is applied for interacting contextual information of input point clouds, followed by a classification head to estimate the overlapping region. We evaluate our unified model extensively on the KITTI dataset and Apollo-SouthBay dataset. The experiments demonstrate that our method significantly outperforms existing methods on overlap estimation, especially in scenes with small overlaps. It also achieves top registration performance on both datasets in terms of translation and rotation errors.
DA4AD: End-to-end Deep Attention Aware Features Aided Visual Localization for Autonomous Driving
Mar 06, 2020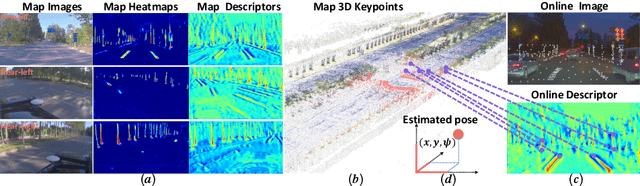
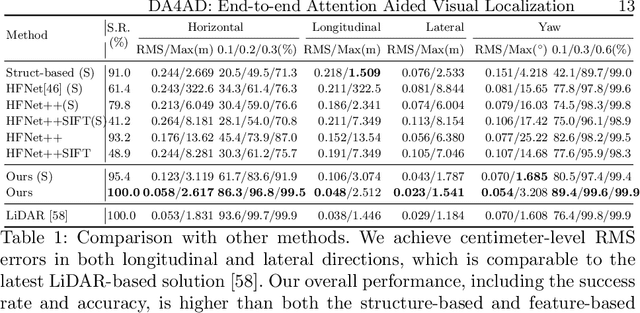
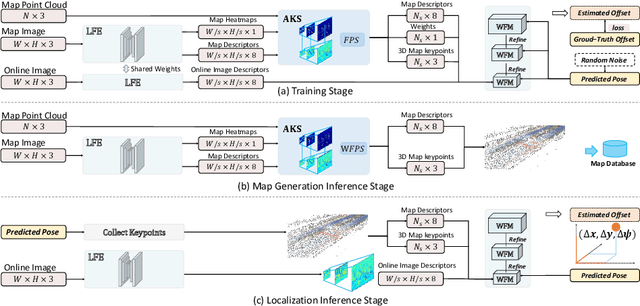
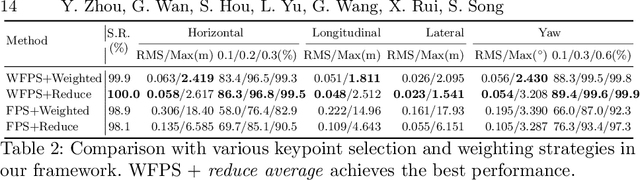
We present a visual localization framework aided by novel deep attention aware features for autonomous driving that achieves centimeter level localization accuracy. Conventional approaches to the visual localization problem rely on handcrafted features or human-made objects on the road. They are known to be either prone to unstable matching caused by severe appearance or lighting changes, or too scarce to deliver constant and robust localization results in challenging scenarios. In this work, we seek to exploit the deep attention mechanism to search for salient, distinctive and stable features that are good for long-term matching in the scene through a novel end-to-end deep neural network. Furthermore, our learned feature descriptors are demonstrated to be competent to establish robust matches and therefore successfully estimate the optimal camera poses with high precision. We comprehensively validate the effectiveness of our method using a freshly collected dataset with high-quality ground truth trajectories and hardware synchronization between sensors. Results demonstrate that our method achieves a competitive localization accuracy when compared to the LiDAR-based localization solutions under various challenging circumstances, leading to a potential low-cost localization solution for autonomous driving.
DeepICP: An End-to-End Deep Neural Network for 3D Point Cloud Registration
May 10, 2019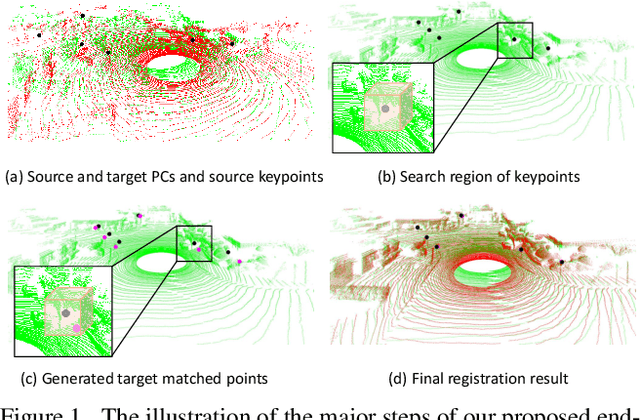
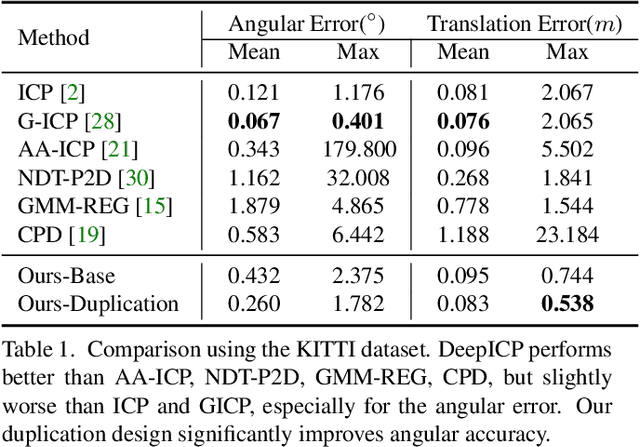
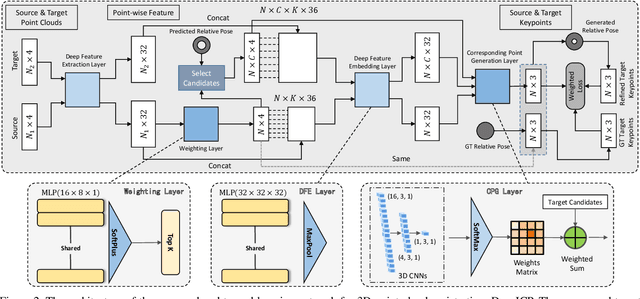
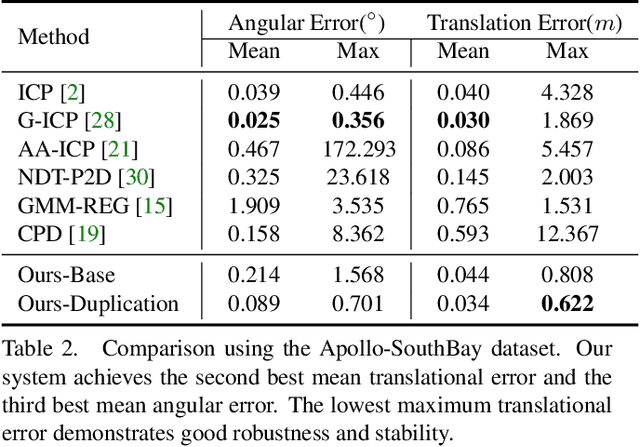
We present DeepICP - a novel end-to-end learning-based 3D point cloud registration framework that achieves comparable registration accuracy to prior state-of-the-art geometric methods. Different from other keypoint based methods where a RANSAC procedure is usually needed, we implement the use of various deep neural network structures to establish an end-to-end trainable network. Our keypoint detector is trained through this end-to-end structure and enables the system to avoid the inference of dynamic objects, leverages the help of sufficiently salient features on stationary objects, and as a result, achieves high robustness. Rather than searching the corresponding points among existing points, the key contribution is that we innovatively generate them based on learned matching probabilities among a group of candidates, which can boost the registration accuracy. Our loss function incorporates both the local similarity and the global geometric constraints to ensure all above network designs can converge towards the right direction. We comprehensively validate the effectiveness of our approach using both the KITTI dataset and the Apollo-SouthBay dataset. Results demonstrate that our method achieves comparable or better performance than the state-of-the-art geometry-based methods. Detailed ablation and visualization analysis are included to further illustrate the behavior and insights of our network. The low registration error and high robustness of our method makes it attractive for substantial applications relying on the point cloud registration task.
Robust and Precise Vehicle Localization based on Multi-sensor Fusion in Diverse City Scenes
Nov 15, 2017
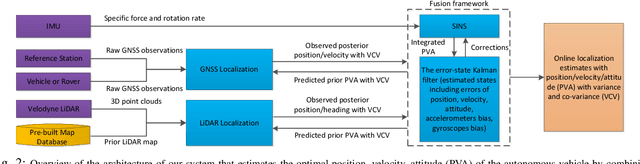
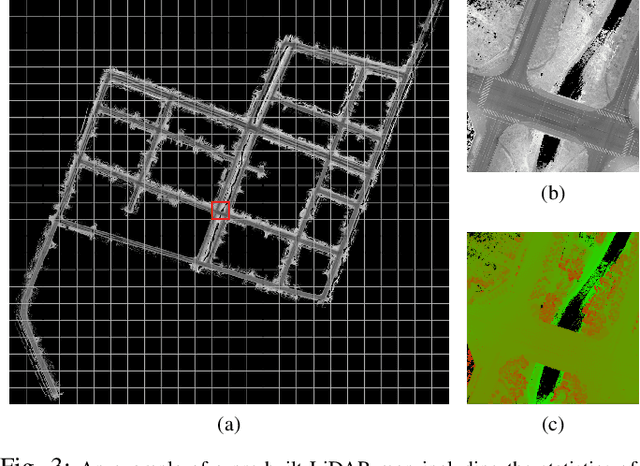
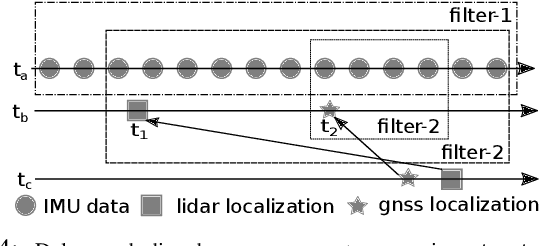
We present a robust and precise localization system that achieves centimeter-level localization accuracy in disparate city scenes. Our system adaptively uses information from complementary sensors such as GNSS, LiDAR, and IMU to achieve high localization accuracy and resilience in challenging scenes, such as urban downtown, highways, and tunnels. Rather than relying only on LiDAR intensity or 3D geometry, we make innovative use of LiDAR intensity and altitude cues to significantly improve localization system accuracy and robustness. Our GNSS RTK module utilizes the help of the multi-sensor fusion framework and achieves a better ambiguity resolution success rate. An error-state Kalman filter is applied to fuse the localization measurements from different sources with novel uncertainty estimation. We validate, in detail, the effectiveness of our approaches, achieving 5-10cm RMS accuracy and outperforming previous state-of-the-art systems. Importantly, our system, while deployed in a large autonomous driving fleet, made our vehicles fully autonomous in crowded city streets despite road construction that occurred from time to time. A dataset including more than 60 km real traffic driving in various urban roads is used to comprehensively test our system.